1 引入NumPy和Pandas
2 df[col]方法选取列
**pandas.read_csv()函数可以用来读取csv文件,其主要参数如下:
filepath_or_buffer:数据输入的路径,输入可以是文件路径、URL,可以是实现read方法的任意对象。
sep:读取csv文件时指定的分隔符,默认为逗号。
header:设置导入Datarame的列名称,默认为“infer”。
names:当names没被赋值时,header会变成0,即选取数据文件的第一行作为列名。 当 names 被赋值,header 没被赋值时,那么header会变成None。如果都赋值,就会实现两个参数的组合功能。
index_col:们在读取文件之后,生成的 DataFrame 的索引默认。**
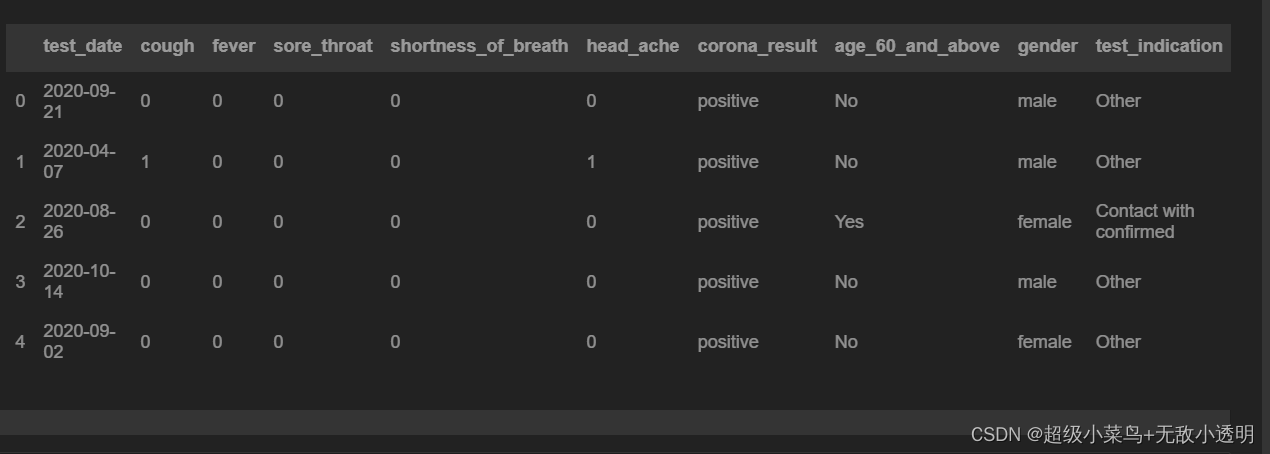
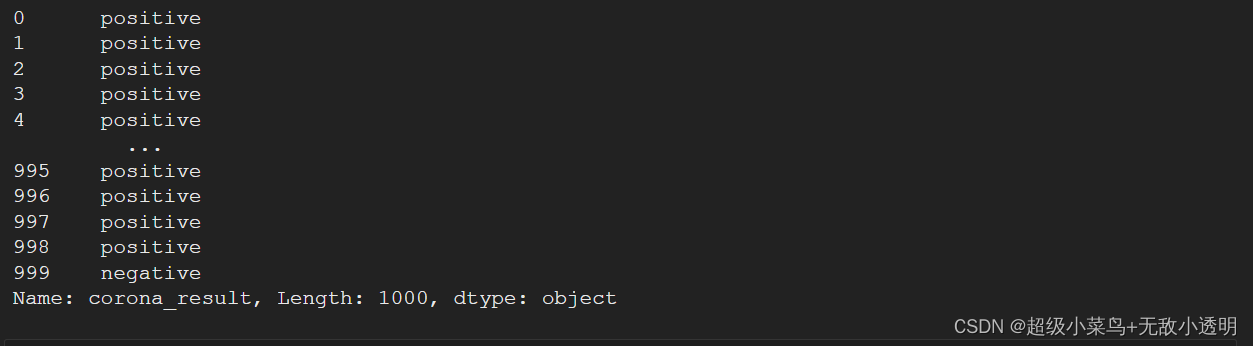
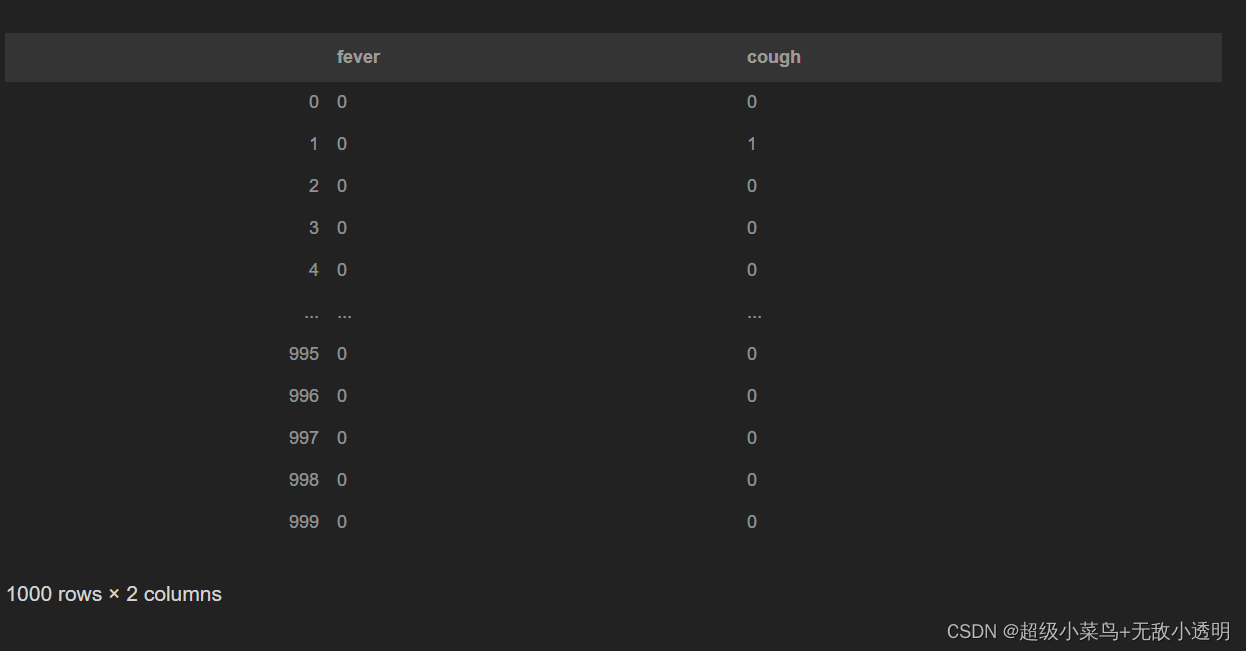
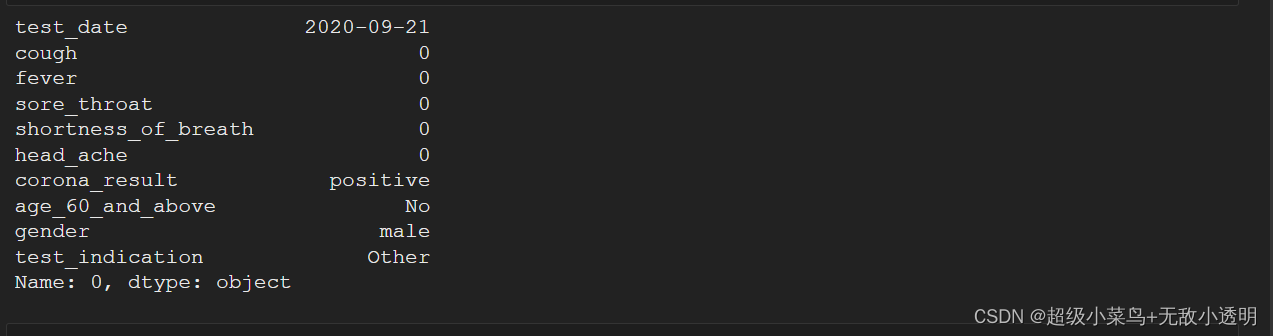
3 df.loc[label] 通过标签选取行/列
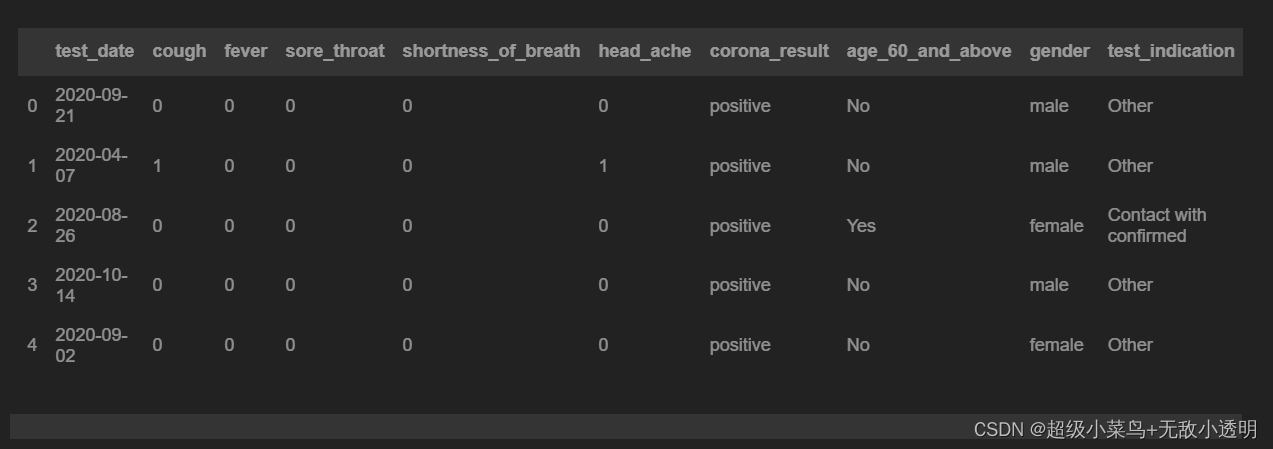
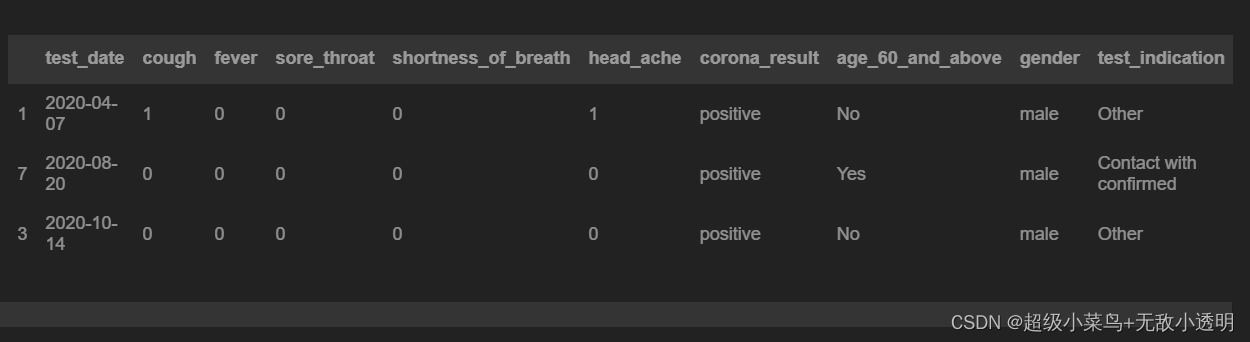
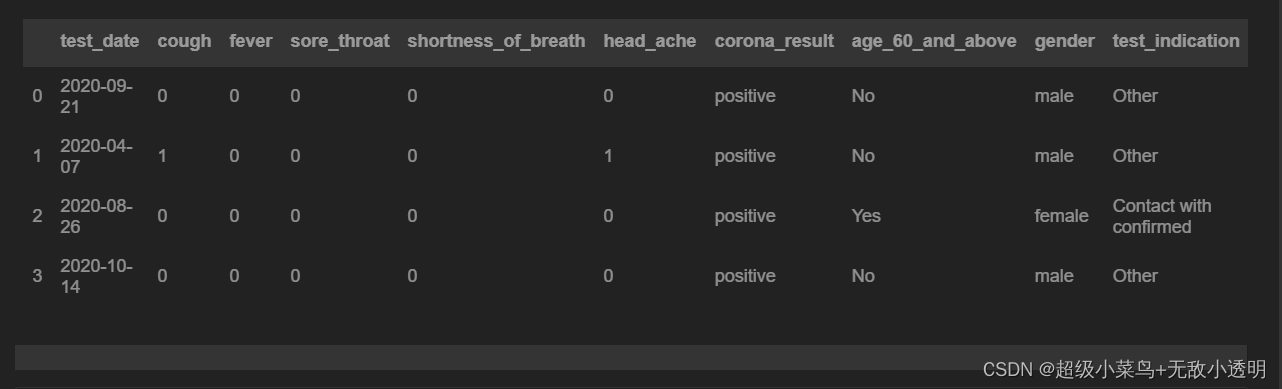


4 df.iloc[loc]通过位置选择行/列
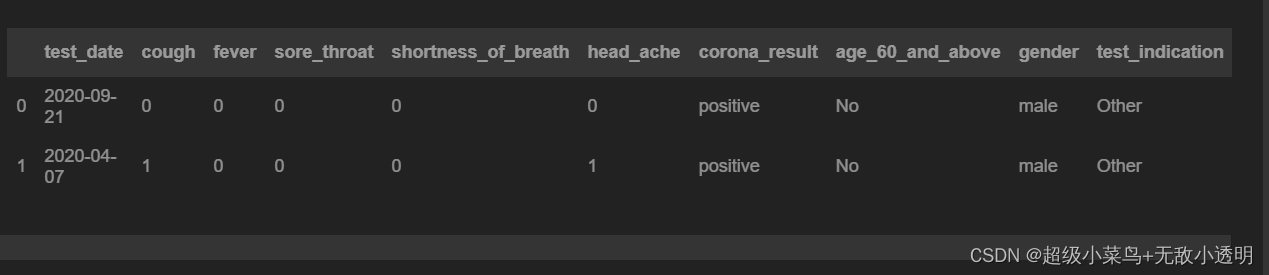
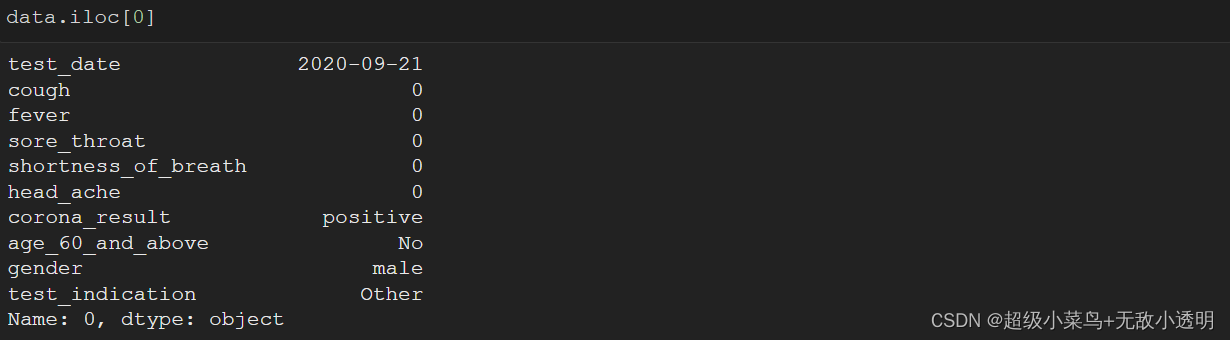
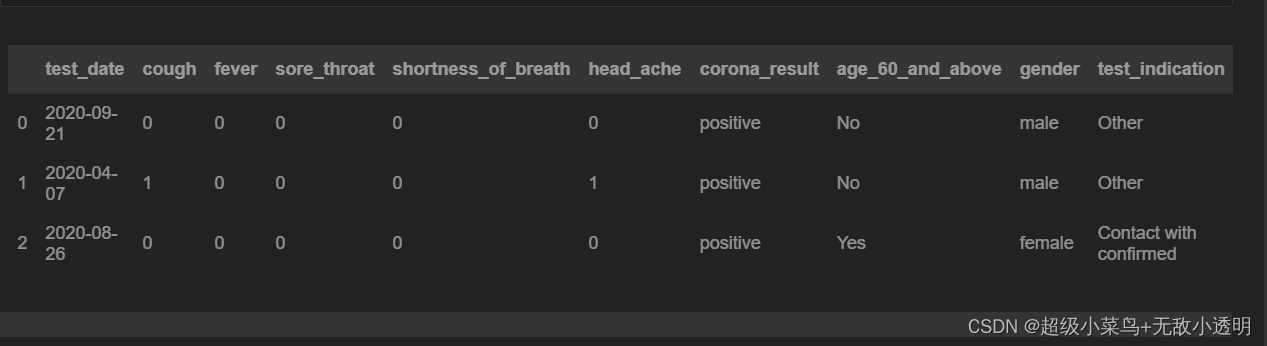
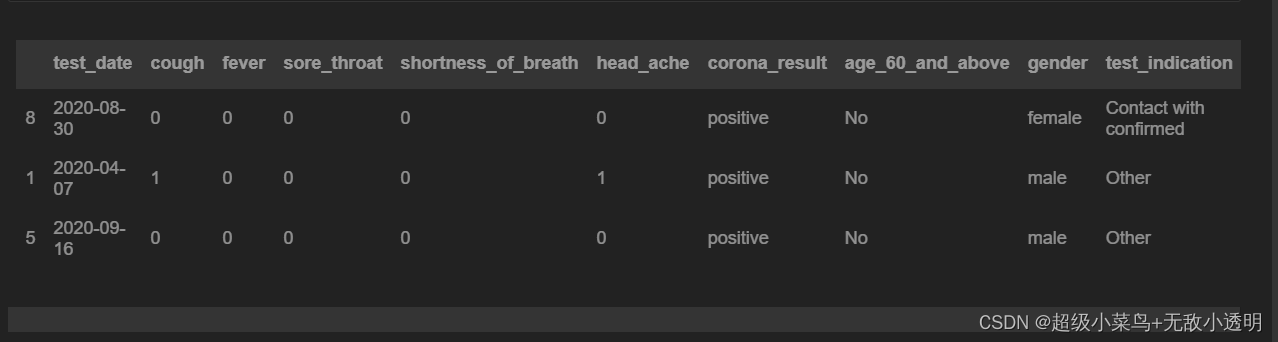
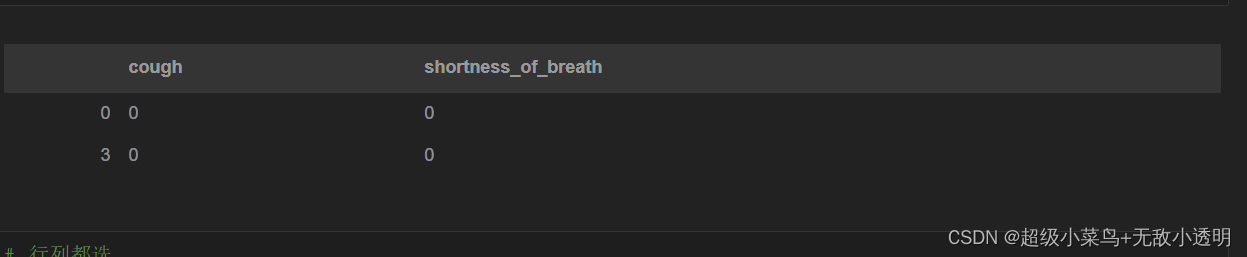

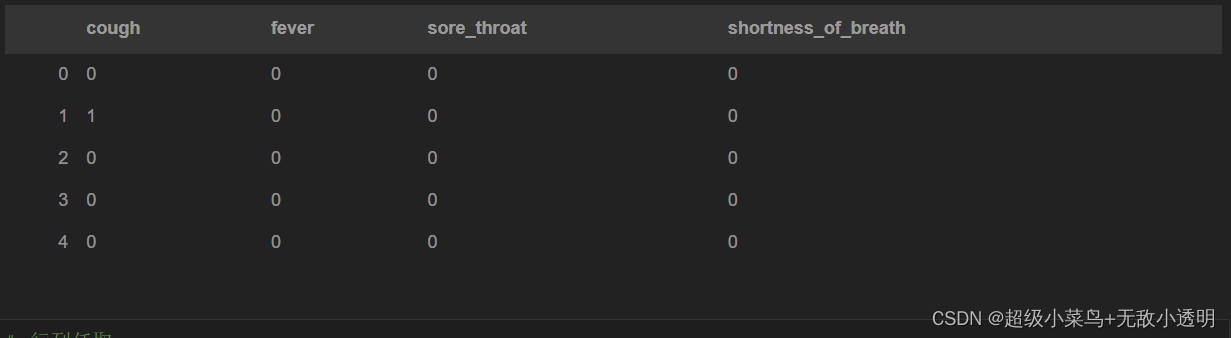
5 通过切片方式获取多行/列
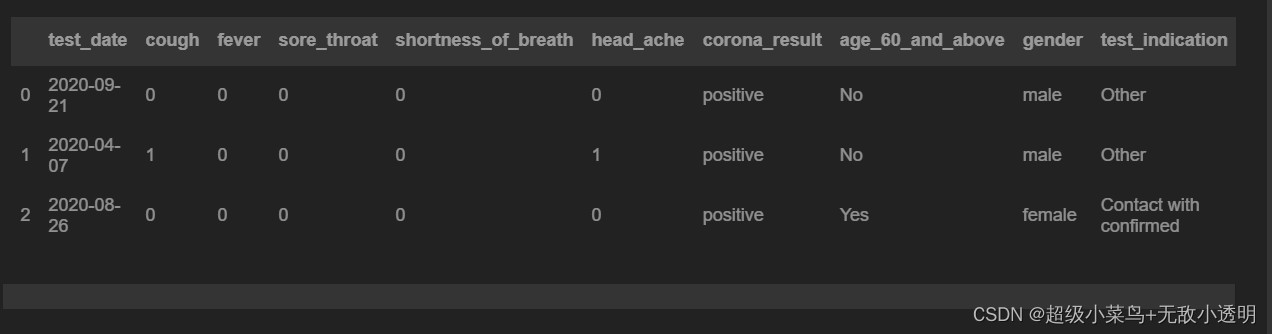
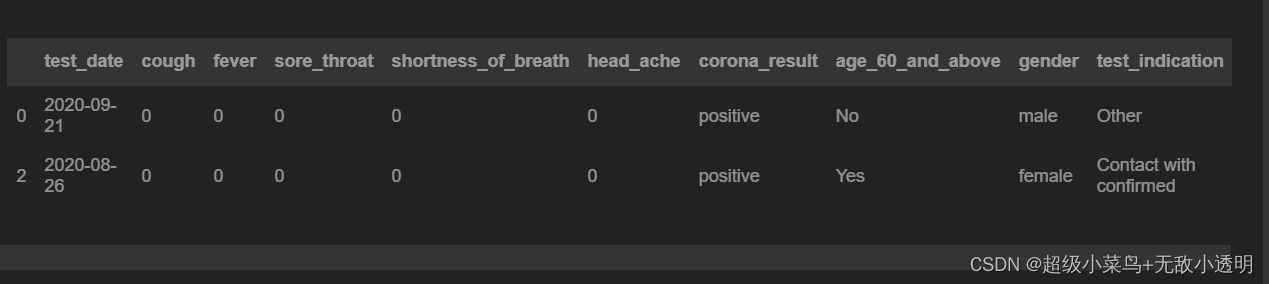
6 通过布尔向量获取多行/列



声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。





