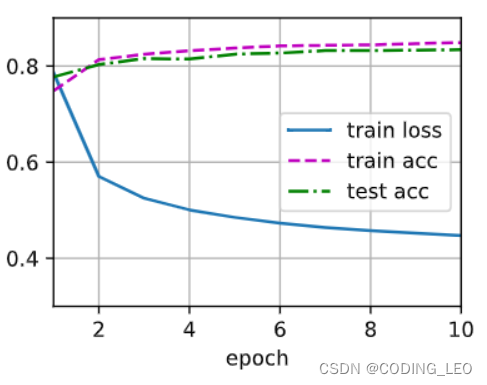
深度学习
前言
Batch Normalization作为最近一年来DL的重要成果,已经广泛被证明其有效性和重要性。虽然有些细节处理还解释不清其理论原因,但是实践证明好用才是真的好,别忘了DL从Hinton对深层网络做Pre-Train开始就是一个经验领先于理论分析的偏经验的一门学问。本文是对论文《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》的导读。
机器学习领域有个很重要的假设:IID独立同分布假设,就是假设训练数据和测试数据是满足相同分布的,这是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障。那BatchNorm的作用是什么呢?BatchNorm就是在深度神经网络训练过程中使得每一层神经网络的输入保持相同分布的。
为什么深度神经网络随着网络深度加深,训练起来越困难,收敛越来越慢?这是个在DL领域很接近本质的好问题。很多论文都是解决这个问题的,比如ReLU激活函数,再比如Residual Network,BN本质上也是解释并从某个不同的角度来解决这个问题的。
一、“Internal Covariate Shift”问题
从论文名字可以看出,BN是用来解决“Internal Covariate Shift”问题的,那么首先得理解什么是“Internal Covariate Shift”?
论文首先说明Mini-Batch SGD相对于One Example SGD的两个优势:梯度更新方向更准确;并行计算速度快;(为什么要说这些?因为BatchNorm是基于Mini-Batch SGD的,所以先夸下Mini-Batch SGD,当然也是大实话);然后吐槽下SGD训练的缺点:超参数调起来很麻烦。(作者隐含意思是用BN就能解决很多SGD的缺点)
接着引入covariate shift的概念:如果ML系统实例集合<X,Y>中的输入值X的分布老是变,这不符合IID假设,网络模型很难稳定的学规律,这不得引入迁移学习才能搞定吗,我们的ML系统还得去学习怎么迎合这种分布变化啊。对于深度学习这种包含很多隐层的网络结构,在训练过程中,因为各层参数不停在变化,所以每个隐层都会面临covariate shift的问题,也就是在训练过程中,隐层的输入分布老是变来变去,这就是所谓的“Internal Covariate Shift”,Internal指的是深层网络的隐层,是发生在网络内部的事情,而不是covariate shift问题只发生在输入层。