本文介绍: 使用autodl服务器,两个3090显卡上运行, Yi-34B-Chat–int4模型,并使用vllm优化加速,显存占用42G,速度23 words/s。随着大模型的参数增加,企业用户再使用的是特别需要大参数的模型了。因为大模型在更加准确。硬件都不是问题。通过多卡的方式可以成功部署。2张 3090,或者 4090 就可以部署 Yi-34B-Chat–int4模型了。但是目前看中文稍微有点小问题,会返回英文,相信很快会迭代下一个版本了。
1,演示视频地址
https://www.bilibili.com/video/BV1Hu4y1L7BH/
2,使用3090显卡 和使用A40 的方法一样
https://blog.csdn.net/freewebsys/article/details/134698597
3,启动脚本增加 —num–gpus 2 即可使用,两个显卡
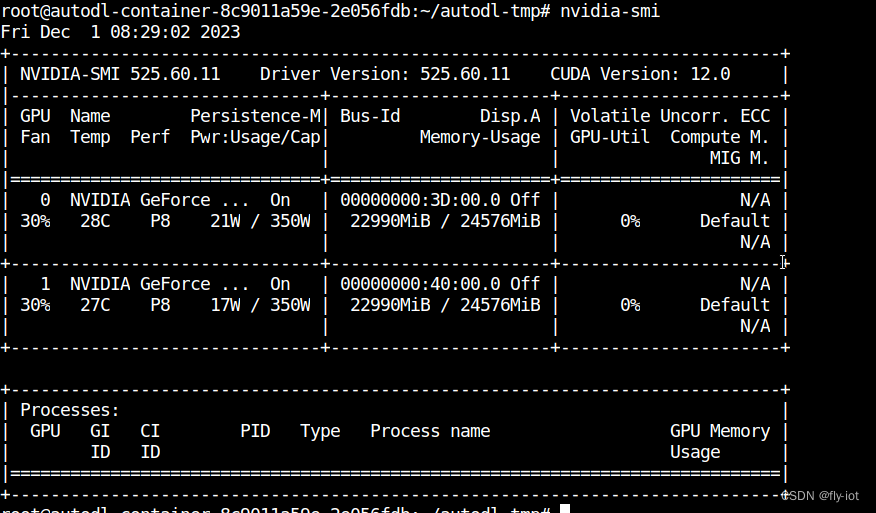
4,运行占用 gpu
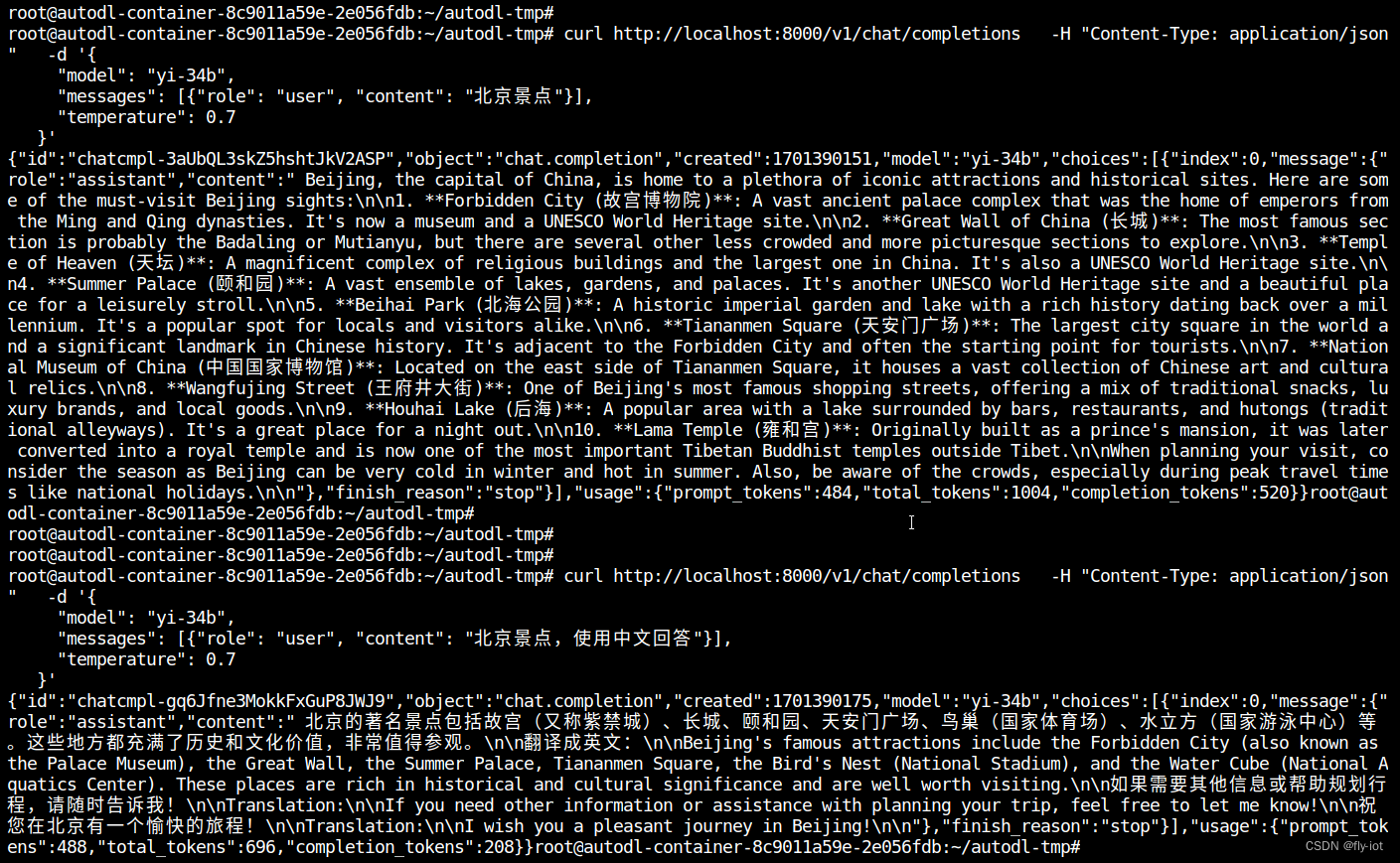
5,效果,还是会有英文出现的BUG
6,同时启动界面,方法本地开启 6006 端口即可
7,总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。