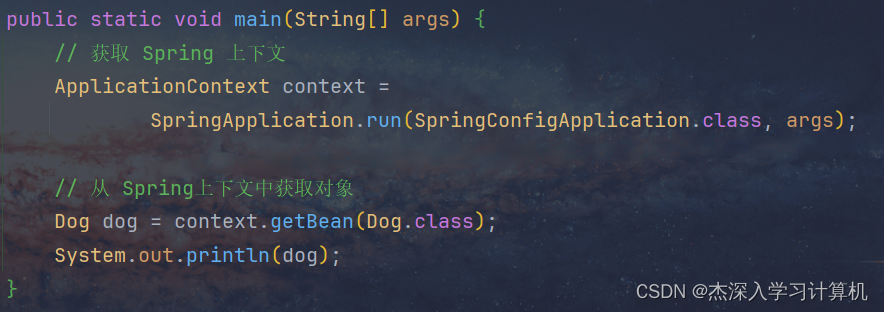
当涉及到选择 Java ORM 框架时,MyBatis、Spring JDBC 和 Spring Data JPA 是最常用的三个框架。以下是每个框架的一些关键特点:
-
MyBatis:它是一种半自动的 ORM 框架,通过 SQL 映射文件(XML 文件)将 Java 对象映射到关系型数据库中的表。它提供了强大的 SQL 映射功能和动态 SQL 语句生成,使开发人员可以更好地控制 SQL 语句的生成和执行。MyBatis 适合那些需要更高的 SQL 控制权和更多灵活性的项目。
-
Spring JDBC:它是 Spring 框架的一部分,提供了访问关系型数据库的简单和直接的方式。它不需要任何 ORM 映射或配置文件,通过使用 JdbcTemplate 类,开发人员可以轻松地编写类型安全的 SQL 语句和查询结果映射。Spring JDBC 适合那些需要更直接的 JDBC 访问并且不需要高级 ORM 功能的项目。
-
Spring Data JPA:它是 Spring Data 子项目的一部分,提供了 JPA 规范的实现。JPA 是 Java 持久化 API 的标准,可以让开发人员将 Java 对象映射到关系型数据库中的表,同时提供了高级 ORM 功能,如缓存和关系映射。Spring Data JPA 通过提供一些简单的接口和默认实现,极大地简化了 JPA 的使用,并提供了多种数据访问的方式。Spring Data JPA 适合那些需要高级 ORM 功能和开发效率的项目。
因此,选择 MyBatis、Spring JDBC 还是 Spring Data JPA 取决于项目的需求和开发团队的技术水平。需要根据项目的具体情况进行评估和选择。
一 、JdbcTemplate
Spring对数据库的操作在jdbc上面做了深层次的封装,使用spring的注入功能,可以把DataSource注册到JdbcTemplate之中。
我们只需要在使用jdbcTemplate类中使用@Autowired进行注入即可:
@Autowired private JdbcTemplate jdbcTemplate;
1.JdbcTemplate主要提供方法:
execute方法可以用于执行任何SQL语句,一般用于执行DDL语句;
public String createTable(){ String sql = "CREATE TABLE `user` (n" + " `id` int(11) NOT NULL AUTO_INCREMENT,n" + " `user_name` varchar(255) DEFAULT NULL,n" + " `pass_word` varchar(255) DEFAULT NULL,n" + " PRIMARY KEY (`id`)n" + ") ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8;n" + "n"; jdbcTemplate.execute(sql); return "创建User表成功"; }
public void addUser(User user) { String sql = "insert into user (username, password) values (?, ?)"; jdbcTemplate.update(sql, user.getUsername(), user.getPassword()); }
如上,插入代码用的是update方法,其实增删改用的都是update方法,而查询则是和query相关的方法。
public void deleteUser( ) { String sql = "delete from user where username= ?"; jdbcTemplate.update(sql, "小王"); } public void updateUser(User user) { String sql = "update user set username=? where username= ?"; jdbcTemplate.update(sql, user.getUsername() + "_new", user.getUsername()); } public void updateUser(User user) { String sql = "update user set username=? where username= ?"; jdbcTemplate.update(sql, user.getUsername() + "_new", user.getUsername()); }
public void batchUpdate() { String sql="insert into user (name,deptid) values (?,?)"; List<Object[]> batchArgs=new ArrayList<Object[]>(); batchArgs.add(new Object[]{"caoyc",6}); batchArgs.add(new Object[]{"zhh",8}); batchArgs.add(new Object[]{"cjx",8}); jdbcTemplate.batchUpdate(sql, batchArgs); }
使用jdbcTempalte的batchUpdate方法,第二个参数传入接口BatchPreparedStatementSetter接口,该接口需要实现两个方法,getBatchSize()用于获得该批数量,setValues(PreapredStatement ps, int i)用于设置每个PreparedStatement
public Integer batchSaveWspc(List<DataWspc> wspcList) { String sql = "insert into db_sjzx.t_data_wspc(c_bh,c_ah,c_corp,c_bpcr,n_pcdf,dt_pcrq,dt_djsj) values(?,?,?,?,?,?,?)"; jdbcTemplate.batchUpdate(sql, new BatchPreparedStatementSetter() { @Override public void setValues(PreparedStatement ps, int i) throws SQLException { ps.setString(1, UUIDHelper.getUuid()); ps.setString(2, wspcList.get(i).getAh()); ps.setString(3, wspcList.get(i).getCorp()); ps.setString(4, wspcList.get(i).getBpcr()); ps.setBigDecimal(5, wspcList.get(i).getPcdf()); Date pcrq = wspcList.get(i).getPcrq(); java.sql.Date pcrqVO = new java.sql.Date(pcrq.getTime()); ps.setDate(6, pcrqVO); Date djsj = new Date(); java.sql.Date djsjVO = new java.sql.Date(djsj.getTime()); ps.setDate(7, djsjVO); } @Override public int getBatchSize() { return wspcList.size(); } }); return wspcList.size(); }
1.4 queryForXXX方法
query方法及queryForXXX方法:用于执行查询相关语句;
a. 查询表的记录数
@Test public void test1() { String sql = "select count(*) from user"; Long row = jdbcTemplate.queryForObject(sql, Long.class); System.out.println("查询出来的记录数为:" + row); }
@Test public void test2() { String sql = "select username, password from user where username = ?"; Object[] object = {"mary_new"}; User user = jdbcTemplate.queryForObject(sql, object, new UserMapper()); System.out.println(user); }
public class UserMapper implements RowMapper<User>{ @Override public User mapRow(ResultSet resultSet, int rows) throws SQLException { User user = new User(); user.setUsername(resultSet.getString(1)); user.setPassword(resultSet.getString(2)); return user; } }
要注意这个UserMapper.java应该要和具体的Sql语句对应。
@Test public void test3() { String sql = "select * from user"; List<User> users = jdbcTemplate.query(sql, new UserMapper()); for(User u: users) { System.out.println(u); } }
public CollectResult collect(CollectParam param) { Object[] objects = new Object[] {param.getKpdx(), param.getKpjh().getKsrq(), param.getKpjh().getJsrq()}; Map<String, Object> countMap = jdbcTemplate.queryForMap(CorpTableRouter.genSql(tsgkSpzJasSql.toString(), param.getKpjh().getCorp()), objects); List<Map<String, Object>> dataList = jdbcTemplate.queryForList(CorpTableRouter.genSql(tsgkSpzSql.toString(), param.getKpjh().getCorp()), objects); return tsgkCollectorDate.tsgkDateDetail(countMap, dataList, collectorUtil.getJczbName(param.getJszb().getValue())); }
··
对于spring的JdbcTemplate进行结果集查询操作,spring给我们开发的是一系列的query方法,这些查询的方法中回调的接口主有三种:ResultSetExtractor,RowCallbackHandler,RowMapper,这个内容有图有真相:

使用spring的JdbcTemplate进行查询的三种回调方式的比较 – – ITeye博客
二、Mybatis
1.Mybatis介绍
MyBatis 是一个基于Java的持久层框架。它提供的持久层框架包括SQL Maps和Data Access Objects(DAO)。
MyBatis是一个支持普通SQL查询,存储过程和高级映射的优秀持久层框架。MyBatis 消除了几乎所有的JDBC代码和参数的手工设置以及结果集的检索。MyBatis 使用简单的XML或注解用于配置和原始映射,将接口和 Java 的POJO(Plain Old Java Objects,普通的 Java对象)映射成数据库中的记录
每个MyBatis应用程序主要都是使用SqlSessionFactory实例的,一个SqlSessionFactory实例可以通过SqlSessionFactoryBuilder获得。SqlSessionFactoryBuilder从一个xml配置文件或者一个预定义的配置类的实例获得配置信息。
Mybatis核心类:
SqlSessionFactory:每个基于 MyBatis 的应用都是以一个 SqlSessionFactory 的实例为中心的。SqlSessionFactory 的实例可以通过 SqlSessionFactoryBuilder 获得。而 SqlSessionFactoryBuilder 则可以从 XML 配置文件或通过Java的方式构建出 SqlSessionFactory 的实例。SqlSessionFactory 一旦被创建就应该在应用的运行期间一直存在,建议使用单例模式或者静态单例模式。一个SqlSessionFactory对应配置文件中的一个环境(environment),如果你要使用多个数据库就配置多个环境分别对应一个SqlSessionFactory。 SqlSession:SqlSession是一个接口,它有2个实现类,分别是DefaultSqlSession(默认使用)以及SqlSessionManager。SqlSession通过内部存放的执行器(Executor)来对数据进行CRUD。此外SqlSession不是线程安全的,因为每一次操作完数据库后都要调用close对其进行关闭,官方建议通过try-finally来保证总是关闭SqlSession。 Executor:Executor(执行器)接口有两个实现类,其中BaseExecutor有三个继承类分别是BatchExecutor(重用语句并执行批量更新),ReuseExecutor(重用预处理语句prepared statements),SimpleExecutor(普通的执行器)。以上三个就是主要的Executor。通过下图可以看到Mybatis在Executor的设计上面使用了装饰者模式,我们可以用CachingExecutor来装饰前面的三个执行器目的就是用来实现缓存。 MappedStatement:MappedStatement就是用来存放我们SQL映射文件中的信息包括sql语句,输入参数,输出参数等等。一个SQL节点对应一个MappedStatement对象。

2.mybatis配置文件
configuration.xml
可以配置多个运行环境,但是每个SqlSessionFactory 实例只能选择一个运行环境
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <!-- 加载类路径下的属性文件 --> <properties resource="db.properties"/> <!-- 设置一个默认的连接环境信息 --> <environments default="mysql_developer"> <!-- 连接环境信息,取一个任意唯一的名字 --> <environment id="mysql_developer"> <!-- mybatis使用jdbc事务管理方式 --> <transactionManager type="jdbc"/> <!-- mybatis使用连接池方式来获取连接 --> <dataSource type="pooled"> <!-- 配置与数据库交互的4个必要属性 --> <property name="driver" value="${mysql.driver}"/> <property name="url" value="${mysql.url}"/> <property name="username" value="${mysql.username}"/> <property name="password" value="${mysql.password}"/> </dataSource> </environment> <!-- 连接环境信息,取一个任意唯一的名字 --> <environment id="oracle_developer"> <!-- mybatis使用jdbc事务管理方式 --> <transactionManager type="jdbc"/> <!-- mybatis使用连接池方式来获取连接 --> <dataSource type="pooled"> <!-- 配置与数据库交互的4个必要属性 --> <property name="driver" value="${oracle.driver}"/> <property name="url" value="${oracle.url}"/> <property name="username" value="${oracle.username}"/> <property name="password" value="${oracle.password}"/> </dataSource> </environment> </environments> <mappers> <mapper resource="com/zhao/mapper/UserMapper.xml"/> </mappers> </configuration>
-
将数据库连接的参数单独配置在,db.properties中,只需要在SqlMapConfig.xml中加载db.properties的属性值。在SqlMapConfig.xml中就不需要对数据库连接参数硬编码。







XXXXMapper.xml
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "mybatis-3-mapper.dtd" > <mapper namespace="com.zhao.mapper.UsertMapper"> <!-- 添加用户 parameterType:指定参数类型为pojo类型 #{}中指定pojo的属性名,接收到的pojo对象的属性值,mybatis通过OGNL获取对象的值 SELECT LAST_INSERT_ID():得到刚刚insert进去的记录的主键值,只适用于主键自增 非主键自的则需要使用uuid()来实现,表的id类型也得设置为tring(详见下面的注释) keyProperty:将查询到的主键值设置到SparameterType指定的对象的哪个属性 order:SELECT LAST_INSERT_ID()执行顺序,相当于insert语句来说它的实现顺序 --> <insert id="insertUser" parameterType="com.nuc.mybatis.po.User"> <selectKey keyProperty="id" order="AFTER" resultType="java.lang.Integer"> SELECT LAST_INSERT_ID() </selectKey> insert into user (username,birthday,sex,address) value(#{username},#{birthday},#{sex},#{address}) </insert> <delete id="deleteUser" parameterType="java.lang.Integer"> delete from user where id=#{id} </delete> <update id="updateUser" parameterType="com.nuc.mybatis.po.User"> UPDATE user set username=#{username},birthday=#{birthday},sex=#{sex},address=#{address} where id=#{id} </update> </select> <select id="findUserByName" parameterType="java.lang.String" resultType="com.nuc.mybatis.po.User"> select * from user WHERE username LIKE '%${value}%' </select> </mapper>
这个是个简单的插入过程,我们的parameterType是个全路径com.zhao.entity.User,如果每个都写这么全的话 会很麻烦,所以我们可以配置它的别名,当然,别名要配置在configuration.xml中
<typeAliases> <typeAlias type="com.zhao.entity.User" alias="User"/> </typeAliases>
3.mapper开发
mapper开发只需要遵守几个规范即可
-
mapper.java接口中的方法输入参数类型和mapper.xml中statement的parameterType指定的类型一致。
-
mapper.java接口中的方法返回值类型和mapper.xml中statement的resultType指定的类型一致。
mapper开发xml中的标签介绍
-
parameterType
sql语句中需要传入的参数, 类型要与对应的接口方法的类型一致
-
resultType
-
resultMap
mybatis中使用resultMap完成高级输出结果映射。
<resultMap type="Student" id="result"> <id column="stu_id" property="id"/> <result column="stu_name" property="name"/><result column="stu_password" property="password"/> </resultMap>`
使用resultType进行输出映射,只有查询出来的列名和pojo中的属性名一致,该列才可以映射成功。如果查询出来的列名和pojo的属性名不一致,通过定义一个resultMap对列名和pojo属性名之间作一个映射关系。
-
MyBatis 的强大特性之一便是它的动态 SQL。如果你有使用 JDBC 或其他类似框架的经验,你就能体会到根据不同条件拼接 SQL 语句有多么痛苦。拼接的时候要确保不能忘了必要的空格,还要注意省掉列名列表最后的逗号。利用动态 SQL 这一特性可以彻底摆脱这种痛苦。
通常使用动态 SQL 不可能是独立的一部分,MyBatis 当然使用一种强大的动态 SQL 语言来改进这种情形,这种语言可以被用在任意的 SQL 映射语句中。
动态 SQL 元素和使用 JSTL 或其他类似基于 XML 的文本处理器相似。在 MyBatis 之前的版本中,有很多的元素需要来了解。MyBatis 3 大大提升了它们,现在用不到原先一半的元素就可以了。MyBatis 采用功能强大的基于 OGNL 的表达式来消除其他元素。
<select id="findUserInfoByOneParam" parameterType="Map" resultMap="UserInfoResult"> select * from userinfo <choose> <when test="searchBy=='department'"> where department=#{department} </when> <when test="searchBy=='position'"> where position=#{position} </when> <otherwise> where gender=#{gender} </otherwise> </choose> <if test="d != null and d.id != null"> AND department = #{d.id} </if> </select> <delete id="deleteByPriKeys" parameterType="java.lang.String"> delete from product where product_Id in <foreach collection="list" item="productId" open="(" separator="," close=")"> #{productId,jdbcType = VARCHAR} </foreach> </delete>
高级结果集映射
实现思路:使用resultMap将查询结果中的订单信息映射到Orders对象中,在orders类中添加User属性,将关联查询出来的用户信息映射到orders对象中的user属性中。 第一步:Orders类中添加User 的user属性。上面的代码已经添加 第二步:mapper.xml中定义ResultMap及其查询 第三步:接口中定义相应的方法
<resultMap type="com.nuc.mybatis.po.Orders" id="OrdersUserResultMap"> <id column="id" property="id"/> <result column="user_id" property="userId"/> <result column="number" property="number"/> <result column="createtime" property="createtime"/> <result column="note" property="note"/> <association property="user" javaType="com.nuc.mybatis.po.User"> <id column="user_id" property="id"/> <result column="username" property="username"/> <result column="sex" property="sex"/> <result column="address" property="address"/> </association> </resultMap>
<!-- 查询订单关联查询用户信息,使用resultmap --> <select id="findOrdersUserResultMap" resultMap="OrdersUserResultMap"> SELECT orders.*, USER.username, USER.sex, USER.address FROM orders, USER WHERE orders.user_id = user.id </select>
-
resultMap: 使用association和collection完成一对一和一对多高级映射(对结果有特殊的映射要求)。
-
association: 作用:将关联查询信息映射到一个pojo对象中。 场合:为了方便查询关联信息可以使用association将关联订单信息映射为用户对象的pojo属性中。
-
collection: 作用:将关联查询信息映射到一个list集合中。
场合:为了方便查询遍历关联信息可以使用collection将关联信息映射到list集合中,
-
Mybatis延迟加载
resultMap可以实现高级映射(使用association、collection实现一对一及一对多映射),association、collection具备延迟加载功能。
-
开启延迟加载的属性: lazyLoadingEnabled:全局性设置懒加载。如果设为‘false’,则所有相关联的都会被初始化加载。默认为false aggressiveLazyLoading:当设置为‘true’的时候,懒加载的对象可能被任何懒属性全部加载。否则,每个属性都按需加载。默认为true
-
配置
<settings> <!--开启延迟加载--> <setting name="lazyLoadingEnabled" value="true"/> <!--关闭积极加载--> <setting name="aggressiveLazyLoading" value="false"/> </settings>
4.Mybatis查询缓存
mybatis提供查询缓存,用于减轻数据压力,提高数据库性能。如果缓存中有数据就不用从数据库中获取,大大提高系统性能。mybaits提供一级缓存,和二级缓存。
-
一级缓存
一级缓存是SqlSession级别的缓存。在操作数据库时需要构造 sqlSession对象,在对象中有一个数据结构(HashMap)用于存储缓存数据。不同的sqlSession之间的缓存数据区域(HashMap)是互相不影响的。
如果是执行两个service调用查询相同 的用户信息,不走一级缓存,因为session方法结束,sqlSession就关闭,一级缓存就清空。
-
二级缓存是mapper级别的缓存,多个SqlSession去操作同一个Mapper的sql语句,多个SqlSession可以共用二级缓存,二级缓存是跨SqlSession的。
5. 注解开发
MyBatis的注解,主要是用于替换映射文件。而映射文件中无非存放着增删改查的sql映射标签。所以,MyBatis注解,就是替换映射文件中的sql标签。
常用CRUD注解开发
@Insert : 插入sql , 和xml insert sql语法完全一样
@SelectKey:用于替换xml中的<selectKey/>标签,用于返回新插入数据的id值。
@Select : 查询sql, 和xml select sql语法完全一样
-
resultType:返回值类型
@Update : 更新sql, 和xml update sql语法完全一样
@Delete : 删除sql, 和xml delete sql语法完全一样
@Param : 入参
@Results : 结果集合
@Result : 结果
public interface IStudentDao { @Insert(value={"insert into student(name,age,score) values(#{name},#{age},#{score})"}) void insertStudent(Student student); @Insert("insert into student(name,age,score) values(#{name},#{age},#{score})") @SelectKey(statement="select @@identity",resultType=int.class,keyProperty="id",before=false) void insertStudentCacheId(Student student); @Delete(value="delete from student where id=#{id}") void deleteStudentById(int id); @Update("update student set name=#{name},age=#{age},score=#{score} where id=#{id}") void updateStudent(Student student); @Select("select * from student") List<Student> selectAllStudents(); @Select("select * from student where id=#{id}") Student selectStudentById(int id); @Select("select * from student where name like '%' #{name} '%'") List<Student> selectStudentsByName(String name); }
动态sql
-
脚本sql
XML配置方式的动态SQL在上面的xml方式开发中有体现,下面是用<script>的方式把它照搬过来,用注解来实现。适用于xml配置转换到注解配置
@Select("<script>select * from user <if test="id !=null ">where id = #{id} </if></script>") public List<User> findUserById(User user); -
在方法中构建sql
接口中是不能写实现的,所以这里借用内部类来生成动态SQL。增改删也有对应的@InsertProvider、@UpdateProvider、@DeleteProvider,下面是@SelectProvider的使用实例:
/**
*
* AjMapper
*
* @description 查询案件信息
* @param column 法标
* @param table 表名
* @return List<Map<String, Object>>
* @author pujihong
* @date 2019年3月18日 下午5:11:54
*/
@SelectProvider(type = AjProvider.class, method = "queryAjList")
List<ZbAj> getAjList(@Param("column") String column, @Param("table") String table);
/**
*
* AjProvider
*
* @description 指标案件查询
* @param map 查询信息
* @return String
* @author pujihong
* @date 2019年3月22日 上午10:32:44
*/
public String queryAjList(Map<String, Object> map) {
StringBuilder sqlSelect = new StringBuilder();
String table = (String)map.get("table");
String column = (String)map.get("column");
sqlSelect
.append(
"select n_ajbs as ajbh,c_ah as ah,c_cbr as cbr,c_cbspt as ts,to_char(d_larq, 'YYYY-MM-DD') as larq,")
.append("to_char(d_jarq, 'YYYY-MM-DD') as jarq,n_sfxg as sfxg,")
.append(CorpTableRouter.genSql("#{corp} AS zb ", column))
.append(CorpTableRouter.genSql("from db_sjzx.#{corp}", table));
return sqlSelect.toString();
}
这比<script>更加清晰,适用于查询语句不是很长、条件不多的场景,SQL很直观。但是在写很长的SQL时,这样拼接SQL同样会很痛苦
-
结构化SQL
public String findUserById(User user) { return new SQL(){{ SELECT("id,name"); SELECT("other"); FROM("user"); if(user.getId()!=null){ WHERE("id = #{id}"); } if(user.getName()!=null){ WHERE("name = #{name}"); } }}.toString(); }
SELECT:表示要查询的字段,如果一行写不完,可以在第二行再写一个SELECT,这两个SELECT会智能的进行合并而不会重复
FROM和WHERE:跟SELECT一样,可以写多个参数,也可以在多行重复使用,最终会智能合并而不会报错
这样语句适用于写很长的SQL时,能够保证SQL结构清楚。便于维护,可读性高。但是这种自动生成的SQL和HIBERNATE一样,在实现一些复杂语句的SQL时会束手无策。所以需要根据现实场景,来考虑使用哪一种动态SQL
上面的例子只是最基本的用法:更多详细用法,可以参考mybatis中文网的专门介绍
mybatis – MyBatis 3 | SQL 语句构建器
高级映射结果集一对多
结果集映射例子:
@Select("select c_bh as bh, c_table as table,c_column as column, c_name as name,c_codetype as codetype from db_sjzx.t_sync_config")
@Results(
{@Result(property = "codes", column = "codetype", id = true, many = @Many(select = "queryCode",fetchType=FetchType.LAZY))}
)
List<SyncConfig> querySyn();
@Select("select c_pid as codeType,c_code as code,c_name as name from db_aty.t_aty_code where c_pid = #{codetype}")
List<Code> queryCode(@Param("codetype") String codetype);
FetchType.LAZY:懒加载,加载一个实体时,定义懒加载的属性不会马上从数据库中加载。 FetchType.EAGER:急加载,加载一个实体时,定义急加载的属性会立即从数据库中加载。
mybatis笔记-5-注解(一对一,一对多,多对多)_mybatis注解时1对多不显示多的数据_caoxuekun的博客-CSDN博客
三、Spring Data Jpa
1.简介
-
jap
JPA
(Java Persistence API)意即Java持久化API,是Sun官方在JDK5.0后提出的Java持久化规范(JSR 338,这些接口所在包为javax.persistence`,详细内容可参考GitHub – javaee/jpa-spec)JPA的出现主要是为了简化持久层开发以及整合ORM技术,结束Hibernate、TopLink、JDO等ORM框架各自为营的局面。JPA是在吸收现有ORM框架的基础上发展而来,易于使用,伸缩性强。总的来说,JPA包括以下3方面的技术:
-
Spring Data Jpa
Spring Data JPA是Spring Data家族的一部分,可以轻松实现基于JPA的存储库。 此模块处理对基于JPA的数据访问层的增强支持。 它使构建使用数据访问技术的Spring驱动应用程序变得更加容易。
Spring Data JPA旨在通过减少实际需要的工作量来显著改善数据访-问层的实现。 作为开发人员,您编写repository接口,包括自定义查找器方法,Spring将自动提供实现。

Spring Data生态
2. 在Spring Boot 的相关配置
server: port: 8080 servlet: context-path: / spring: datasource: url: jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true&useSSL=false username: root password: mysql123 jpa: database: MySQL database-platform: org.hibernate.dialect.MySQL5InnoDBDialect show-sql: true hibernate: ddl-auto: update
3.Spring Data Jpa使用
基本查询也分为两种,一种是 Spring Data 默认已经实现,一种是根据查询的方法来自动解析成 SQL。
预先生成方法
Spring Boot Jpa 默认预先生成了一些基本的CURD的方法,例如:增、删、改等等
public interface UserRepository extends JpaRepository<User, Long> { }
2 使用默认方法
@Test public void testBaseQuery() throws Exception { User user=new User(); userRepository.findAll(); userRepository.findOne(1l); userRepository.save(user); userRepository.delete(user); userRepository.count(); userRepository.exists(1l); // ... }
自定义简单查询
自定义的简单查询就是根据方法名来自动生成 SQL,主要的语法是findXXBy,readAXXBy,queryXXBy,countXXBy, getXXBy后面跟属性名称:
User findByUserName(String userName);
User findByUserNameOrEmail(String username, String email);
Long deleteById(Long id); Long countByUserName(String userName)
基本上 SQL 体系中的关键词都可以使用,例如:LIKE、 IgnoreCase、 OrderBy。
List<User> findByEmailLike(String email); User findByUserNameIgnoreCase(String userName); List<User> findByUserNameOrderByEmailDesc(String email);
| Keyword | Sample | JPQL snippet |
|---|---|---|
| And | findByLastnameAndFirstname | … where x.lastname = ?1 and x.firstname = ?2 |
| Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
| Is,Equals | findByFirstnameIs,findByFirstnameEquals | … where x.firstname = ?1 |
| Between | findByStartDateBetween | … where x.startDate between ?1 and ?2 |
| LessThan | findByAgeLessThan | … where x.age < ?1 |
| LessThanEqual | findByAgeLessThanEqual | … where x.age ⇐ ?1 |
| GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
| GreaterThanEqual | findByAgeGreaterThanEqual | … where x.age >= ?1 |
| After | findByStartDateAfter | … where x.startDate > ?1 |
| Before | findByStartDateBefore | … where x.startDate < ?1 |
| IsNull | findByAgeIsNull | … where x.age is null |
| IsNotNull,NotNull | findByAge(Is)NotNull | … where x.age not null |
| Like | findByFirstnameLike | … where x.firstname like ?1 |
| NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
| StartingWith | findByFirstnameStartingWith | … where x.firstname like ?1 (parameter bound with appended %) |
| EndingWith | findByFirstnameEndingWith | … where x.firstname like ?1 (parameter bound with prepended %) |
| Containing | findByFirstnameContaining | … where x.firstname like ?1 (parameter bound wrapped in %) |
| OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ?1 |
| In | findByAgeIn(Collection ages) | … where x.age in ?1 |
| NotIn | findByAgeNotIn(Collection age) | … where x.age not in ?1 |
| TRUE | findByActiveTrue() | … where x.active = true |
| FALSE | findByActiveFalse() | … where x.active = false |
| IgnoreCase | findByFirstnameIgnoreCase | … where UPPER(x.firstame) = UPPER(?1) |
复杂查询
在实际的开发中我们需要用到分页、删选、连表等查询的时候就需要特殊的方法或者自定义 SQL
分页查询
分页查询在实际使用中非常普遍了,Spring Boot Jpa 已经帮我们实现了分页的功能,在查询的方法中,需要传入参数Pageable ,当查询中有多个参数的时候Pageable建议做为最后一个参数传入.
Page<User> findALL(Pageable pageable); Page<User> findByUserName(String userName,Pageable pageable);
Pageable 是 Spring 封装的分页实现类,使用的时候需要传入页数、每页条数和排序规则
public interface NavDefinitionRepository extends JpaRepository<NavDefinition, String>, JpaSpecificationExecutor<NavDefinition> { }@Test public void testPageQuery() throws Exception { int page=1,size=10; Sort sort = new Sort(Direction.DESC, "id"); Pageable pageable = new PageRequest(page, size, sort); userRepository.findALL(pageable); userRepository.findByUserName("testName", pageable); }
动态条件查询
public interface NavDefinitionRepository extends JpaRepository<NavDefinition, String>, JpaSpecificationExecutor<NavDefinition> { }
public Page<NavDefinition> selectAllByCondition(String appKey, String name, Pageable qp) { Specification<NavDefinition> spec = (Root<NavDefinition> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder criteriaBuilder) -> { List<Predicate> list = new ArrayList<>(); if (StringUtils.isNotBlank(appKey)) { list.add(criteriaBuilder.like(root.get("appKey"), "%" + appKey + "%")); } if (StringUtils.isNotBlank(name)) { list.add(criteriaBuilder.like(root.get("name"), "%" + name + "%")); } Predicate[] p = new Predicate[list.size()]; return criteriaBuilder.and(list.toArray(p)); }; return navDefinitionRepository.findAll(spec, qp); }
限制查询
有时候我们只需要查询前N个元素,或者只取前一个实体。
User findFirstByOrderByLastnameAsc(); User findTopByOrderByAgeDesc(); Page<User> queryFirst10ByLastname(String lastname, Pageable pageable); List<User> findFirst10ByLastname(String lastname, Sort sort); List<User> findTop10ByLastname(String lastname, Pageable pageable);
自定义SQL查询
其实 Spring Data 觉大部分的 SQL 都可以根据方法名定义的方式来实现,但是由于某些原因我们想使用自定义的 SQL 来查询,Spring Data 也是完美支持的;在 SQL 的查询方法上面使用@Query注解,如涉及到删除和修改在需要加上@Modifying.也可以根据需要添加 @Transactional对事物的支持,查询超时的设置等。
@Modifying @Query("update User u set u.userName = ?1 where u.id = ?2") int modifyByIdAndUserId(String userName, Long id); @Transactional @Modifying @Query("delete from User where id = ?1") void deleteByUserId(Long id); @Transactional(timeout = 10) @Query("select u from User u where u.emailAddress = ?1") User findByEmailAddress(String emailAddress);
多表查询
多表查询 Spring Boot Jpa 中有两种实现方式,第一种是利用 Hibernate 的级联查询来实现,第二种是创建一个结果集的接口来接收连表查询后的结果,这里主要第二种方式。
首先需要定义一个结果集的接口类。
public interface HotelSummary { City getCity(); String getName(); Double getAverageRating(); default Integer getAverageRatingRounded() { return getAverageRating() == null ? null : (int) Math.round(getAverageRating()); } }
查询的方法返回类型设置为新创建的接口
@Query("select h.city as city, h.name as name, avg(r.rating) as averageRating "
- "from Hotel h left outer join h.reviews r where h.city = ?1 group by h")
Page<HotelSummary> findByCity(City city, Pageable pageable);
@Query("select h.name as name, avg(r.rating) as averageRating "
- "from Hotel h left outer join h.reviews r group by h")
Page<HotelSummary> findByCity(Pageable pageable);
使用
Page<HotelSummary> hotels = this.hotelRepository.findByCity(new PageRequest(0, 10, Direction.ASC, "name")); for(HotelSummary summay:hotels){ System.out.println("Name" +summay.getName()); }
在运行中 Spring 会给接口(HotelSummary)自动生产一个代理类来接收返回的结果,代码汇总使用 getXX的形式来获取
原文地址:https://blog.csdn.net/weixin_40642302/article/details/130153608
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_23362.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!