1. 什么是进程地址空间(what)
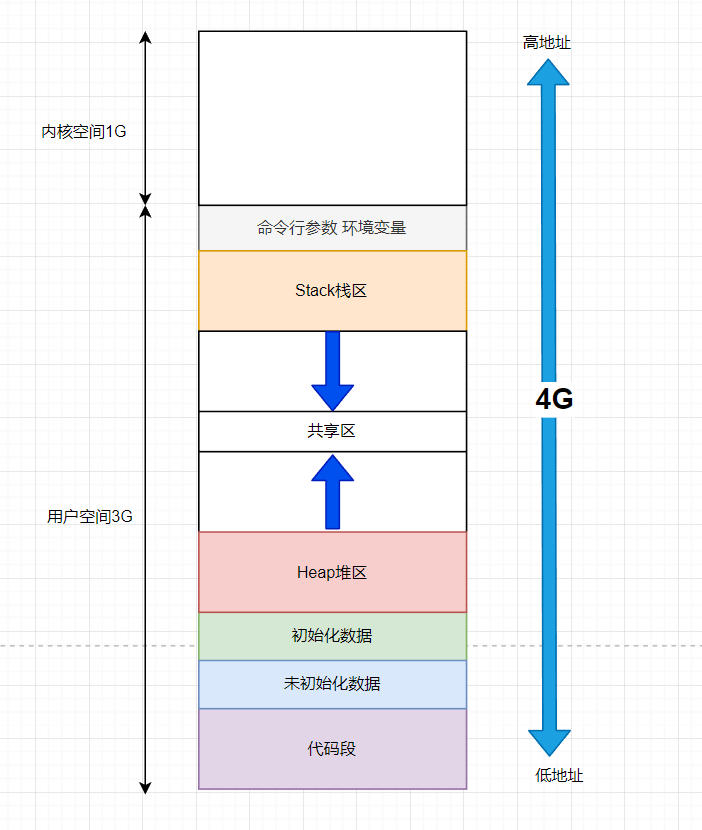
在我们之前的博文中,画过很多次这个图,我们当时说的是内存中的分布情况,但是实际上它并不是所谓内存上的东西,它有一个自己的名字叫做进程地址空间。
首先来一段代码感受一下:
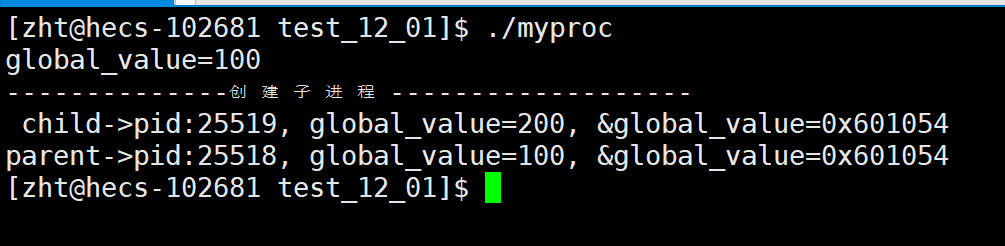
可以看到首先打印的是创建子进程前的global_value的值是100,没有问题,然后创建子进程后,父进程sleep,子进程将global_value修改成200然后打印,3秒后父进程打印global_value,这里父子进程的global_value的值不一样,为什么呢?这个原因我们可以用进程的独立性来解释。再往后看,父子进程的global_value的地址是相同的!!!
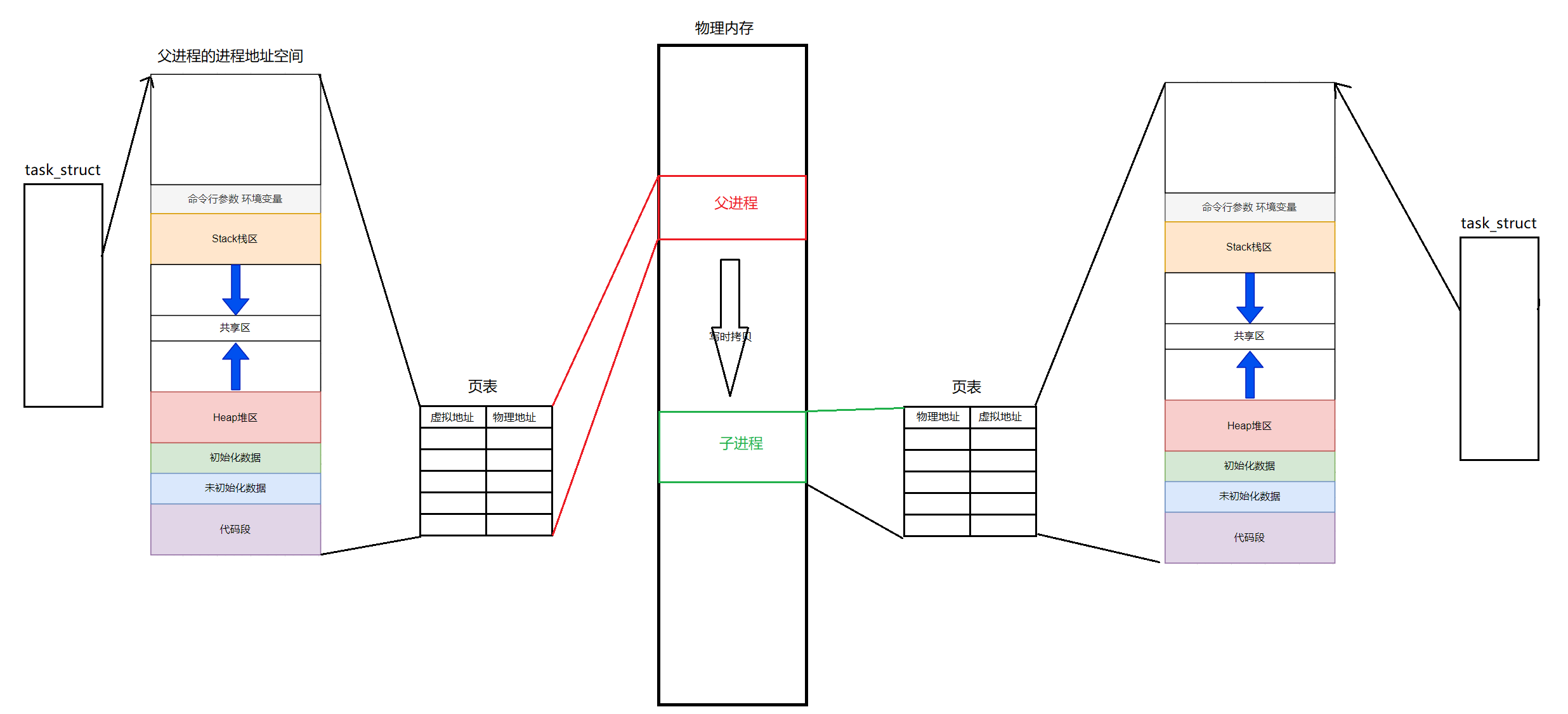
2. 为什么要有进程地址空间(why)
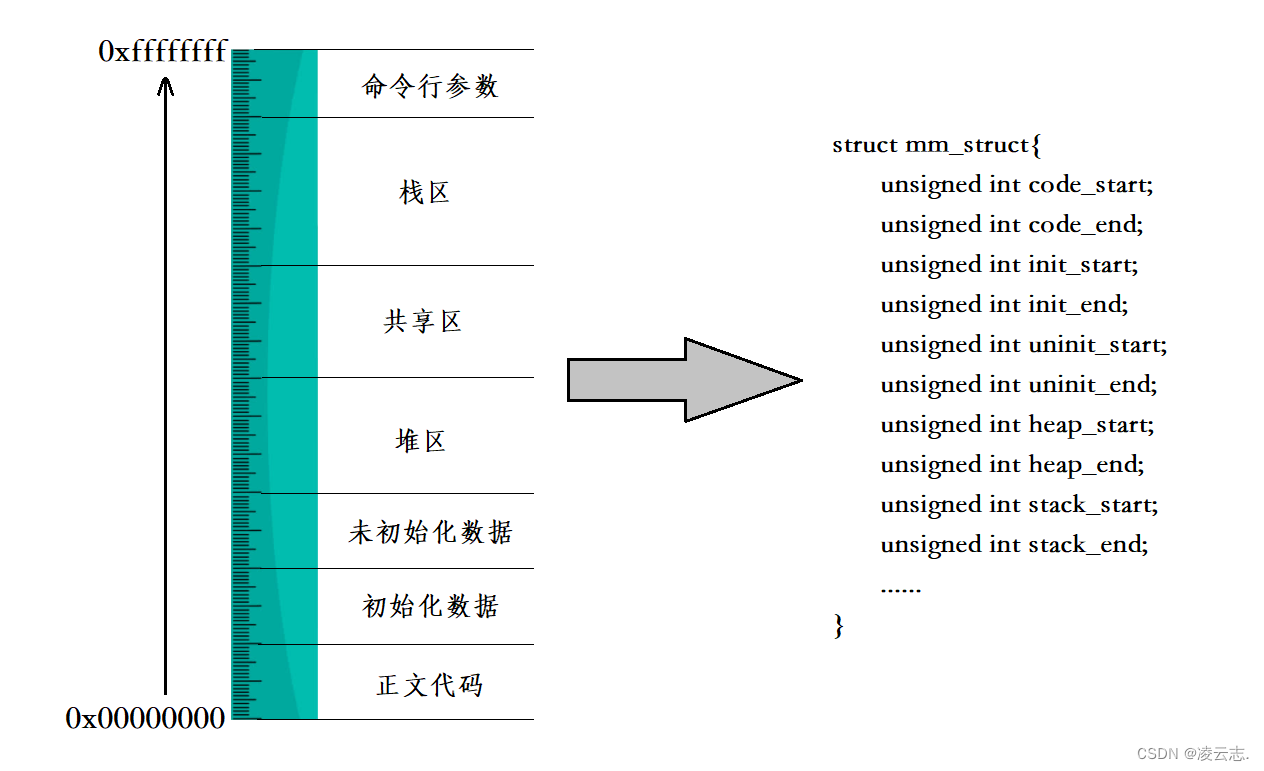
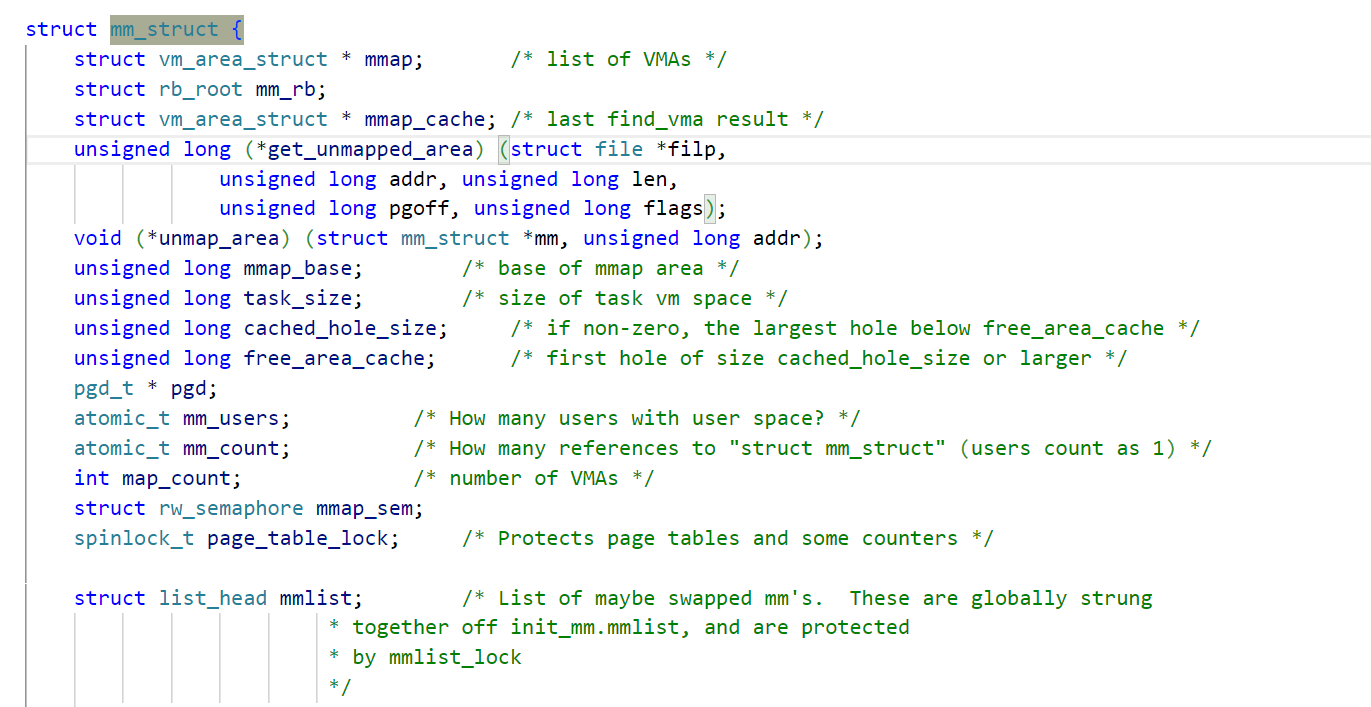
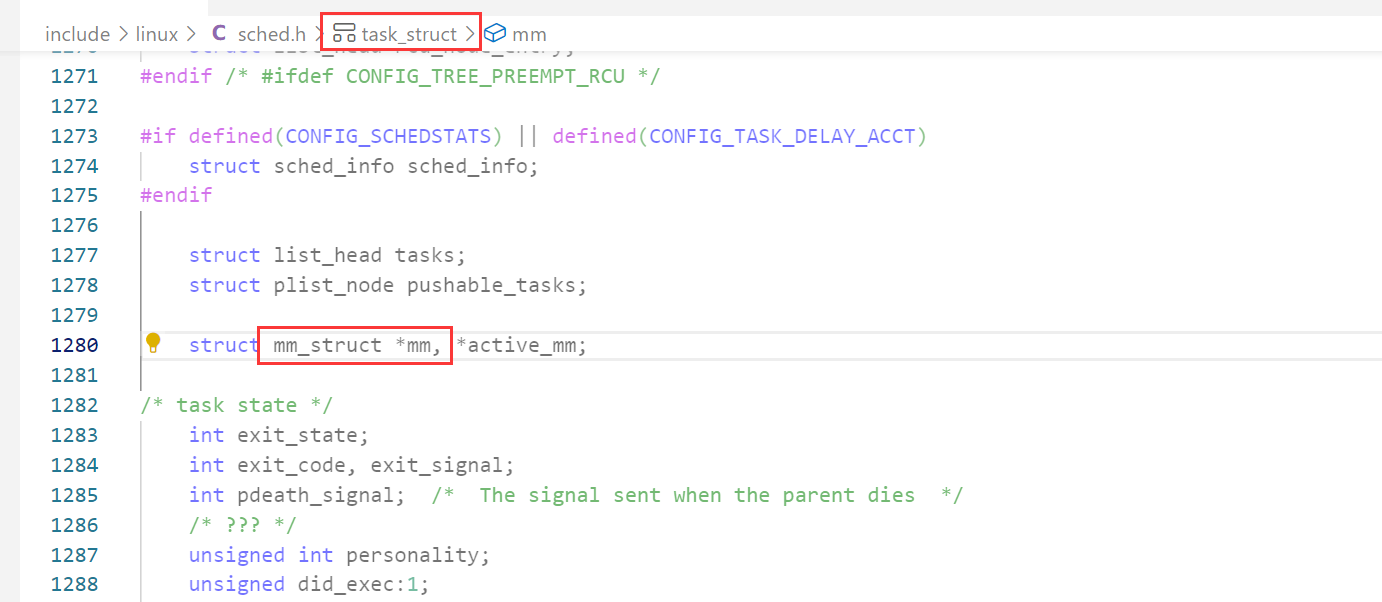
3. 进程地址空间是怎么处理的(how)
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。