Python数据分析 2-3 DataFrame对象
介绍DataFrame对象的创建,删除列增加列,修改列名索引以及数据显示等操作
**2 DataFrame对象的创建
pandas.DataFrame()函数可以返回给定形状和数据类型的数据框,其主要参数如下:
data:数据,其类型可以是ndarray(结构化数组或同构)、Iterable(迭代器)、dic或者直接是DataFrame。
index:行索引。默认为RangeIndex (0, 1, 2, …, n)。
columns:用于生成框架的列标签。默认为RangeIndex (0, 1, 2, …, n)。
dtype:数据类型,可选参数,默认为无。只允许使用一种数据类型,若无,系统自行推断。
copy:布尔型,可选参数{0,1}。从输入复制数据。**


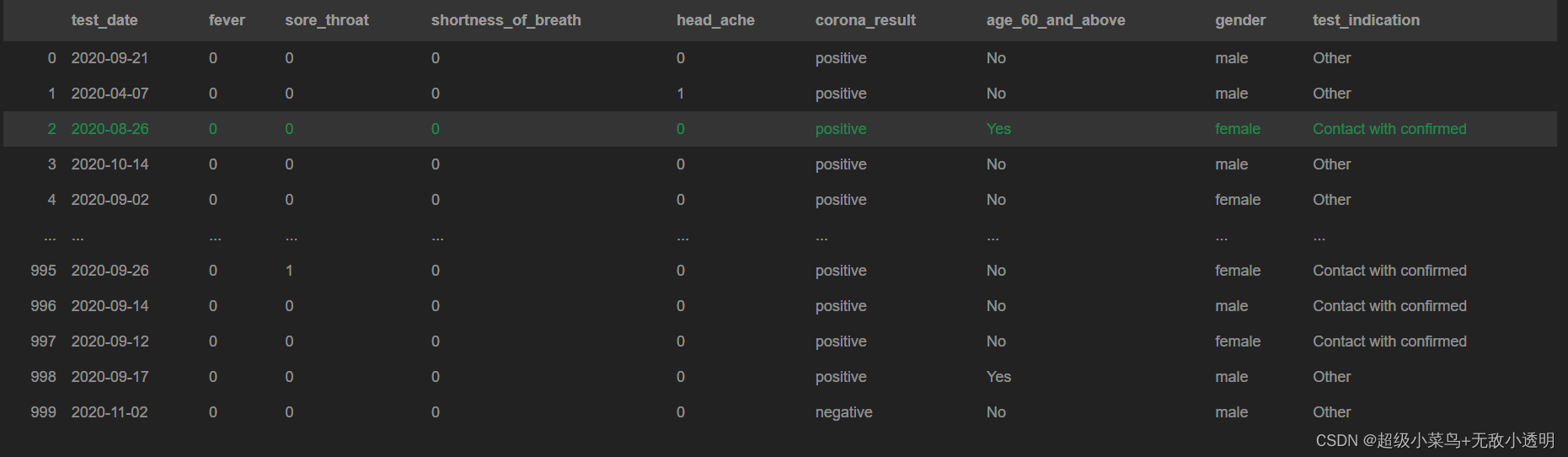
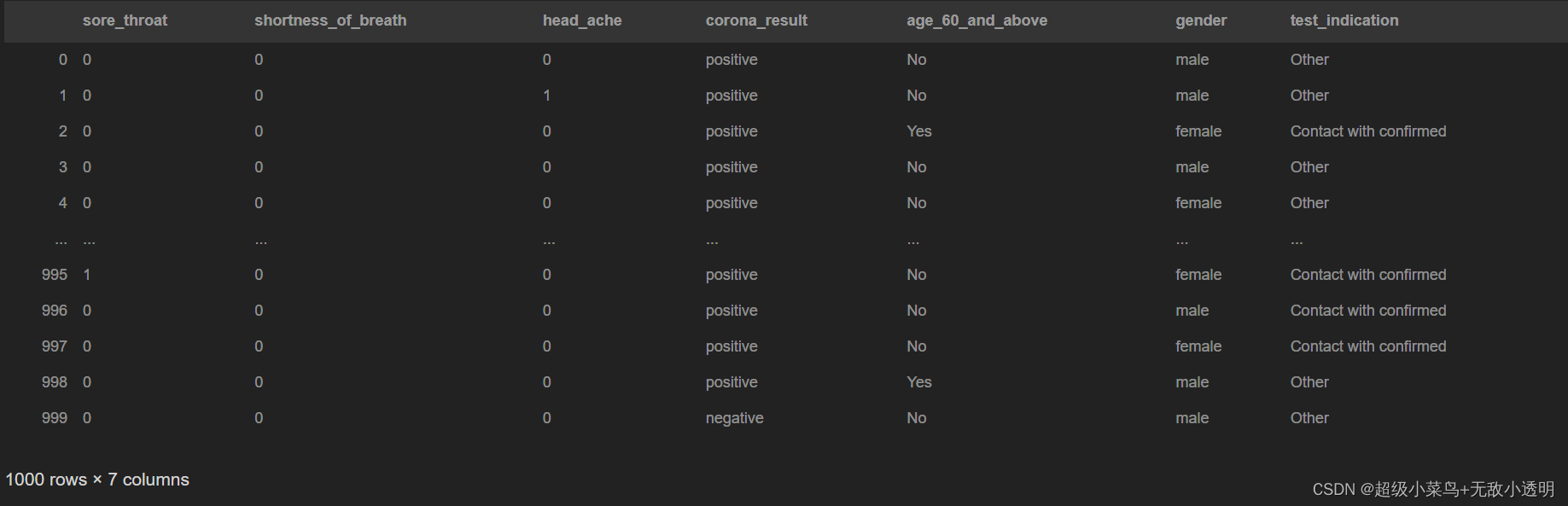
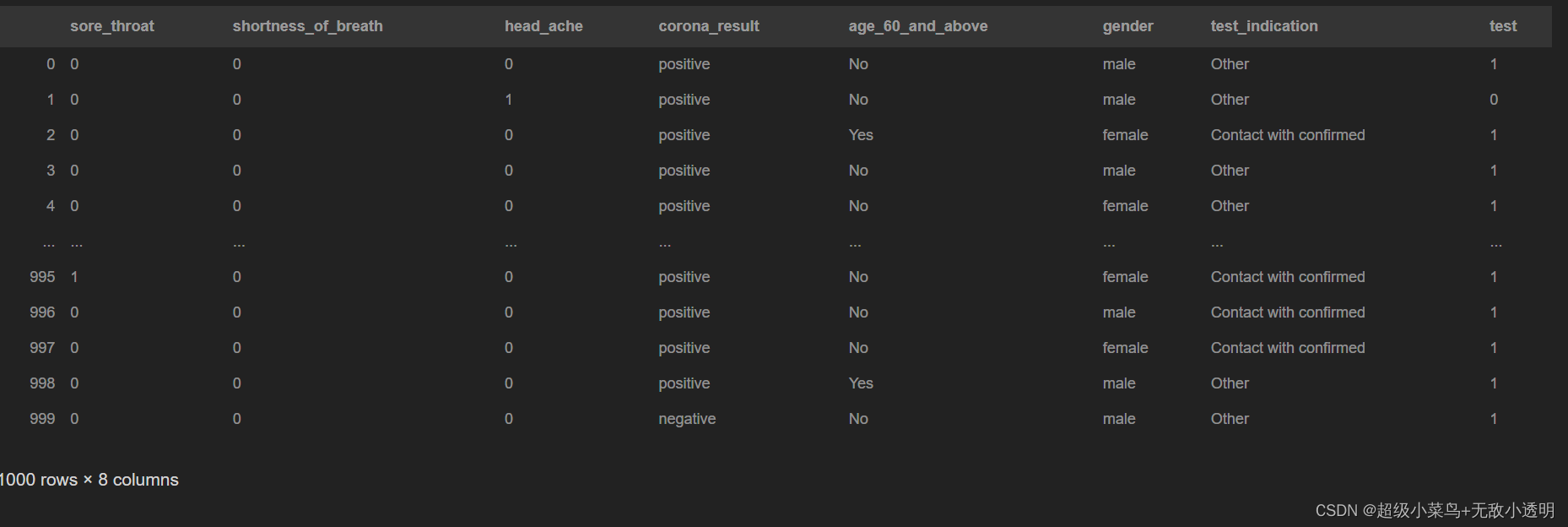
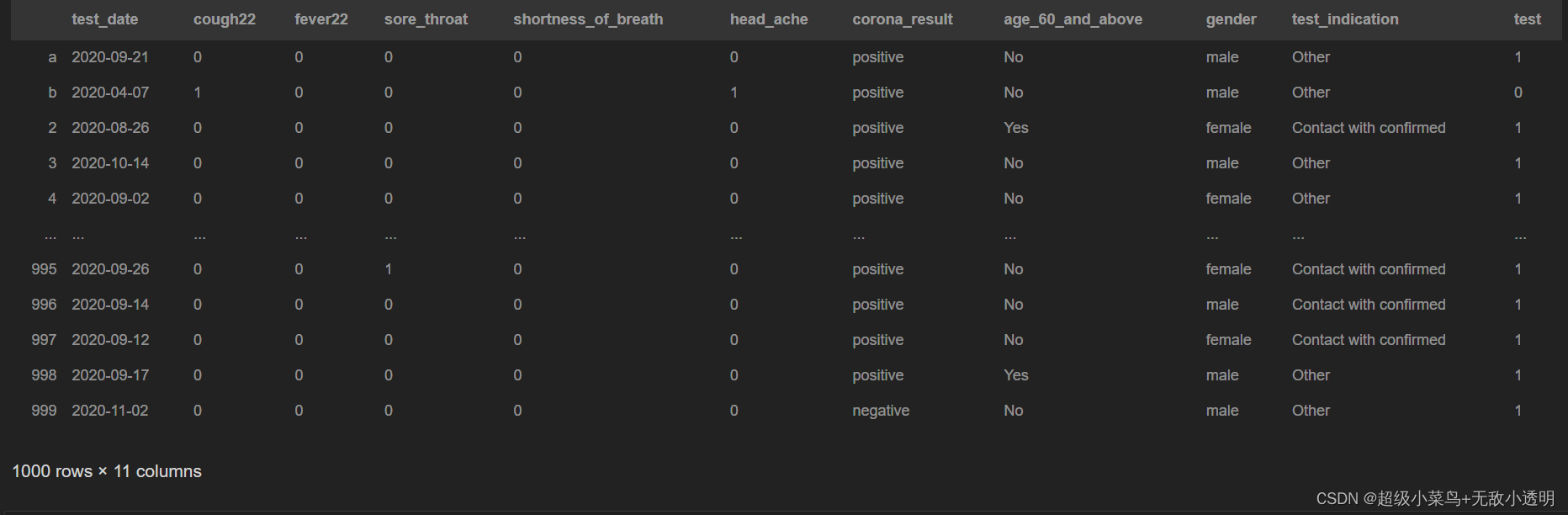
pandas.read_csv()函数从csv文件中读取数据,并返回为一个DataFrame数据框,主要参数如下:
filepath_or_buffer:表示文件所处路径。此参数必须有。
sep:指定分隔符,默认为逗号,。
delimiter:定界符,默认为None,若指定该参数,sep参数失效。
header:指定表头,默认为0(即第一行为表头),若需要没有表头,则header=None。
names:指定列名,用列表表示。
index_col:指定某列数据为索引,默认为None。
prefix:给列名加前缀。默认为None。
encoding:解码方式,乱码时考虑用。默认为None。







声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。