在做机器学习的时候,构建特征变量有很多时候都是文本型的,比如电影分类的时候的电影标题,房价预测的时候房子地址,股吧评论等……都是文本类型的数据。
文本型数据怎么构建特征,它又不是分类变量不能直接独立热编码或者生成虚拟变量。
NLP深度学习领域早就发明了将文本进行向量化的方法,将文本进行词嵌入变为张量。
但是这一般要借助深度学习的框架才能实现,很多同学不懂深度学习,也没时间装框架。
如果不用深度学习领域的方法,只用sklearn库接口,也是可以处理文本的,将文本变为数值型的特征变量,然后再去进行分类回归等监督学习。
数据展示

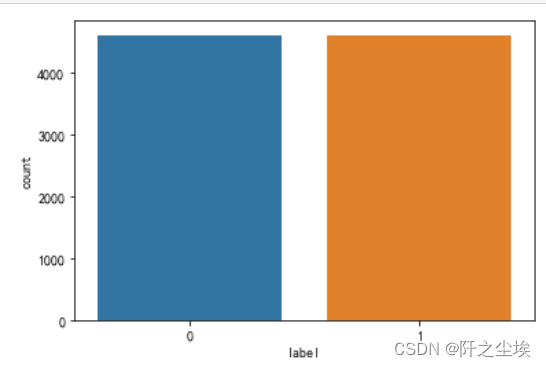
数据读取


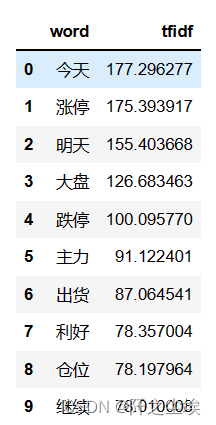
词向量化
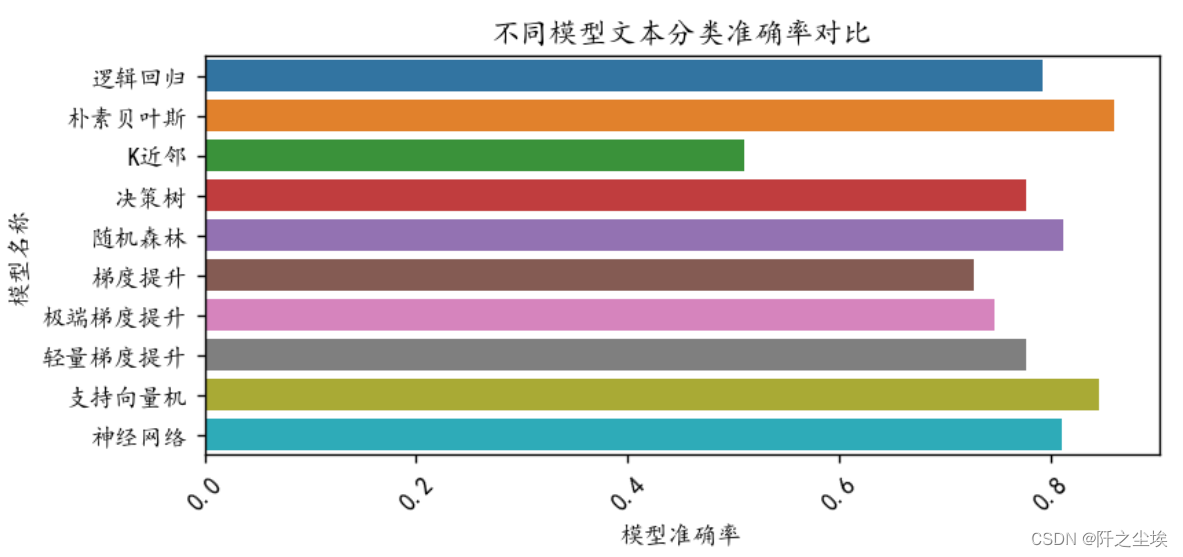
机器学习


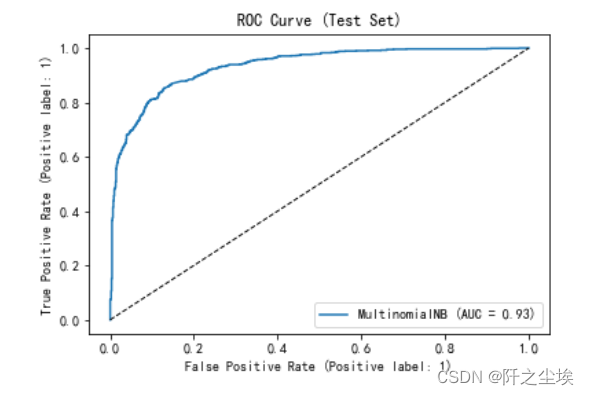
ROC曲线
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。