当前,ChatGLM-6B 在自然语言处理领域日益流行。其卓越的技术特点和强大的语言建模能力使其成为对话语言模型中的佼佼者。让我们深入了解 ChatGLM-6B 的技术特点,探索它在对话模型中的创新之处。
ChatGLM-6B 技术特点详解
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数,基于原文提炼出一些特点
- Tokenization(标记化)
论文采用了基于 icetk 包的文本标记器,词汇量达到 150,000,其中包括 20,000 个图像标记和 130,000 个文本标记。标记的范围从 No.20000 到 No.145653,其中包括常见标点、数字和无扩展定义的空格。 - 层规范化
层规范化在语言建模问题中的重要性得到了深入讨论。论文采用了 DeepNorm 作为 Post-LN 方法,取代了传统的 Pre-LN 方法。该决策是为了应对模型规模扩大至 100B 甚至遇到多模态数据时 Pre-LN 的训练困难的问题。 - 管道并行分析
管道并行性的优化对于训练效率至关重要。论文引入了 Gpipe 和 PipeDream-Flush 策略。在实际 GLM-130B 的预训练中,通过调整微批次的数量,成功减少了 GPU 内存泡沫的占用。具体而言,当微批次数(m)大于等于 4 倍管道数(p)时,总 GPU 内存泡沫的占比可以被降低到可接受的水平。 - 权重量化
为了在推理过程中节省 GPU 内存,论文采用了权重量化技术。Absmax 量化方法在性能和计算效率上的平衡得到了充分的考虑。以下是量化结果的比较:
Model | Original | Absmax INT8 | Absmax INT4 | Zeropoint INT4
-----------|----------|-------------|-------------|----------------
BLOOM-176B | 64.37% | 65.03% | 34.83% | 48.26%
GLM-130B | 80.21% | 80.21% | 79.47% | 80.63%
这表明 GLM-130B 在 INT4 精度下能够保持较高性能,同时有效地减少 GPU 内存占用。考虑到ChatGLM-6B是基于 General Language Model (GLM) 架构实现的,下文将详细对GLM架构展开介绍。
GLM
这个图展示了GLM(General Language Model)的基本原理。在这个模型中,我们首先将文本中的一些部分(绿色部分)标记为空白,也就是我们遮挡了其中的一些文本片段。接下来,我们通过自回归的方式逐步生成这些被遮挡的文本片段。也就是说,我们从左到右逐个预测每个被遮挡的位置上应该是什么词语,然后将这些预测组合起来形成完整的文本。
GLM(General Language Model)发展背景:
当前存在多种预训练模型架构,如自编码模型(BERT)、自回归模型(GPT)和编码–解码模型(T5)。然而,这些框架在自然语言理解(NLU)、无条件生成和条件生成等任务中均无法在所有方面表现最佳。
GLM特点:
GLM是一种基于自回归空白填充的通用语言模型。它通过在输入文本中随机空白化连续跨度的令牌,并训练模型顺序重构这些跨度来进行预训练。GLM改进了空白填充预训练,引入了2D位置编码和允许以任意顺序预测跨度的机制。GLM能够处理不同类型任务的预训练,通过变化空白的数量和长度,实现了对条件和无条件生成任务的预训练。
GLM的改进:
GLM在实现自回归空白填充时引入了两个关键改进:1)跨度洗牌,即对空白的连续跨度进行随机排序;2)2D位置编码,为每个位置引入二维位置编码。这些改进使得GLM在相同参数和计算成本下显著优于BERT,并在多任务学习中表现卓越,尤其在NLU和生成任务中。
自回归模型(例如GPT):
自编码模型(例如BERT):
编码-解码模型(例如T5):
三大类预训练框架对比:
| 特点 | 自回归模型(GPT) | 自编码模型(BERT) | 编码-解码模型(T5) |
|---|---|---|---|
| 训练方向 | 左到右 | 双向 | 双向 |
| 任务适用性 | 长文本生成 | 自然语言理解 | 条件生成任务 |
| 上下文捕捉 | 单向上下文 | 双向上下文 | 双向上下文 |
| 应用领域 | 生成任务 | 自然语言理解任务 | 条件生成任务 |
| 训练效率 | 参数较大时效果较好 | 效果较好且能同时处理所有词 | 参数相对较大 |
这些预训练框架在不同的任务和应用场景中有各自的优势和不足,选择合适的框架取决于具体任务的性质和需求。
GLM预训练框架
我们提出了一个通用的预训练框架GLM,基于一种新颖的自回归空白填充目标。GLM将NLU任务形式化为包含任务描述的填空问题,这些问题可以通过自回归生成来回答。
预训练目标
自回归空白填充
=
[
1
,
⋅
⋅
⋅
,
n
]
[
1
,
⋅
⋅
⋅
,
m
]
x
[
,
1
,
.
.
.
,
s
,
l
]
[s_{i,1}, … , s_{i,l_i}]
[si,1,…,si,li]。
每个片段用单个
[
M
A
S
K
]
[MASK]
x
o
r
r
u
t
xcorrupt。模型根据损坏的文本以自回归方式预测片段中缺失的令牌,具体而言,模型在预测一个片段的缺失令牌时,可以访问损坏的文本以及先前预测的片段。为了全面捕捉不同片段之间的相互依赖关系,我们随机排列了片段的顺序。这种自回归空白填充目标通过引入二维位置编码和允许以任意顺序预测片段,改进了填充预训练,并在 NLU 任务中相较于 BERT 和 T5 取得了性能提升。
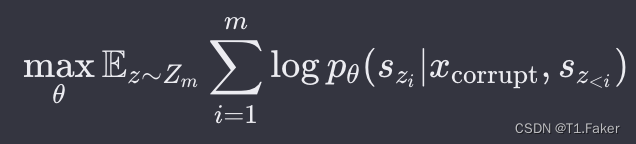
其中,
Z
m
Z_m
Zm是长度为
m
m
s
z
<
i
s_{z<i}
sz<i为
[
s
z
1
,
⋅
⋅
⋅
,
s
z
i
−
1
]
[s_{z_1}, · · · , s_{z_{i−1}}]
[sz1,⋅⋅⋅,szi−1]。每个缺失令牌的生成概率在自回归空白填充目标下,被分解为:
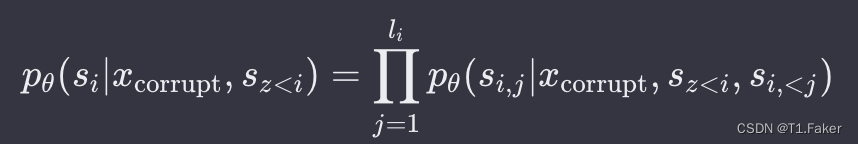
为了实现自回归生成,将输入
x
x
x
o
r
r
u
p
t
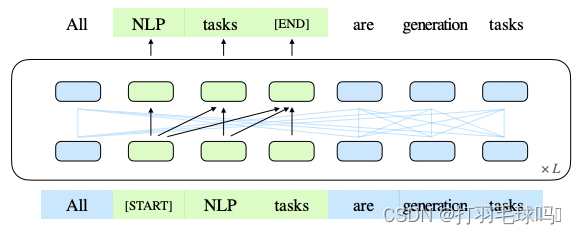
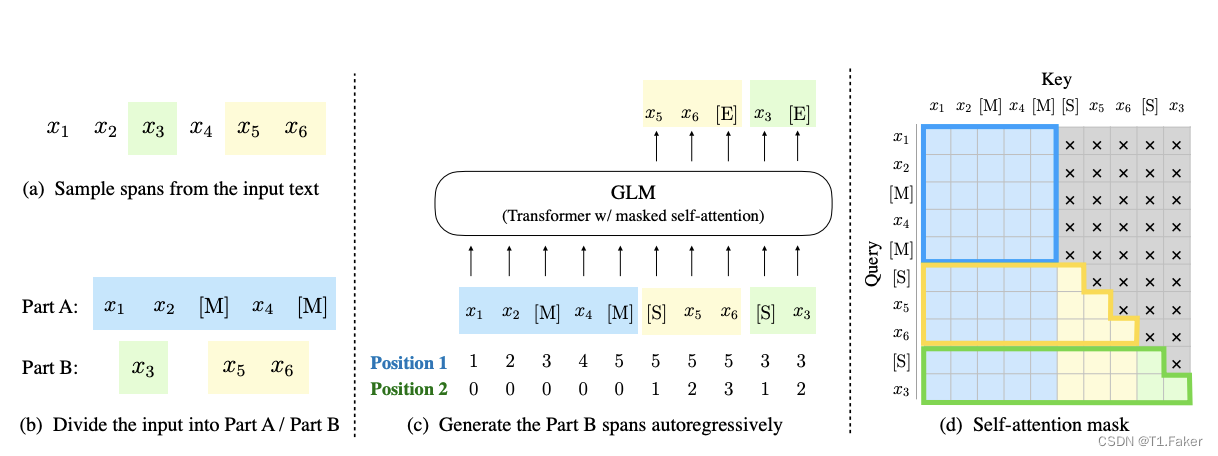
xcorrupt,Part B 包含被掩蔽的片段。Part A 中的令牌可以互相关注,但不能关注 B 中的任何令牌。Part B 中的令牌可以关注 Part A 以及 B 中的先行令牌,但不能关注 B 中的任何后续令牌。为了实现自回归生成,每个片段都用特殊令牌 [START] 和 [END] 进行填充,作为输入和输出。模型的实现如下图所示:
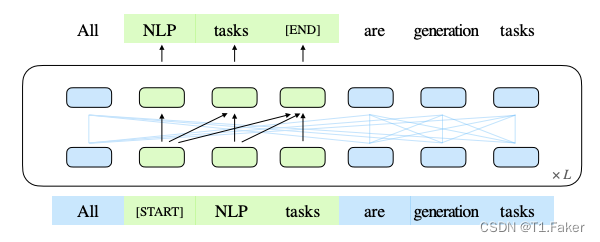
这张图片展示了GLM的预训练流程。原始文本被抽样为多个片段,其中的一些被[MASK]替换,然后进行自回归生成。每个片段都以[S]开始,[E]结束。2D位置编码用于表示片段的内部和相互之间的位置关系。
我们通过从泊松分布中抽样长度为
l
i
l_i
li的片段,反复抽样新片段,直到至少 15% 的原始令牌被掩蔽,来确定片段的数量和长度。实验证明,15% 的比例对于在下游 NLU 任务中取得良好性能至关重要。
多任务预训练
在上述自回归空白填充目标的基础上,GLM 引入了多任务预训练。我们考虑了两个附加目标:
- 文档级别目标: 通过抽样一个长度在原始长度的50%–100%之间的单个片段,鼓励模型进行长文本生成
- 句子级别目标: 限制必须为完整句子的掩蔽片段,以涵盖原始令牌的15%。这个目标旨在处理通常需要生成完整句子或段落的 seq2seq 任务。
这两个新目标都采用与原始目标相同的形式,但有不同数量和长度的片段。
模型架构
GLM 使用单个 Transformer 模型,对其进行了几处修改:
- 将层归一化和残差连接的顺序重新排列,以避免大规模语言模型中的数值错误。
- 使用单个线性层进行输出令牌预测。
- 将 ReLU 激活函数替换为 GeLU(Gaussian Error Linear Unit)。
2D 位置编码
自回归空白填充任务的一个挑战是如何编码位置信息。为了解决这个问题,GLM 引入了二维位置编码。具体而言,每个令牌都用两个位置 id 进行编码。第一个位置 id 表示在损坏的文本
x
o
r
r
u
p
t
xcorrupt中的位置,对于被替换的片段,它是相应
[
M
A
S
K
]
[MASK]
[MASK] 令牌的位置。第二个位置 id 表示片段内部的位置。对于 Part A 中的令牌,它们的第二个位置 id 为0;对于 Part B 中的令牌,它们的第二个位置 id 在1到片段长度之间。这两个位置 id 通过可学习的嵌入表投影为两个向量,然后与输入令牌嵌入相加。
这种编码确保了在模型重建片段时,模型不知道被替换片段的长度,这与其他模型不同。例如,XLNet 在推理时需要知道或枚举答案的长度,而 SpanBERT 替换了多个
[
M
A
S
K
]
[MASK]
[MASK]令牌并保持长度不变。
微调 GLM
通常,对于下游 NLU 任务,线性分类器将预训练模型生成的序列或令牌表示作为输入,并预测正确的标签。我们将 NLU 分类任务重新构造为空白填充任务,通过 PET(Pattern-Exploiting Training)的方式,将输入文本
x
x
(
x
)
c(x)
c(x)。这个填充模板以自然语言编写,以表示任务的语义,例如,情感分类任务可以被构造成“{SENTENCE}. It’s really [MASK]”。候选标签
∈
Y
y∈Y
e
r
a
l
i
z
e
r
(
)
verbalizerv(y)。在情感分类中,标签“positive”和“negative”被映射为“good”和“bad”。给定
x
x
x的条件下预测
y
y
y的概率为:

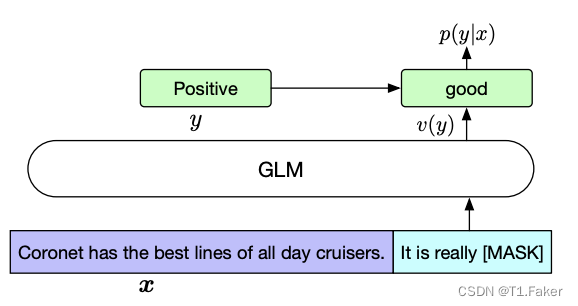
对比
在这一节中,我们讨论 GLM 与其他预训练模型的差异,并关注它们如何适应下游空白填充任务。
与 BERT 的比较
与 BERT 不同,GLM 在 MLM 的独立性假设下,无法捕捉掩蔽令牌之间的相互依赖关系。BERT 的另一个劣势是,它不能很好地填充多个令牌的空白。为了推断长度为
l
l
l
l
l个连续的预测。如果长度
l
l
l未知,可能需要枚举所有可能的长度,因为 BERT 需要根据长度改变 [MASK] 令牌的数量。这是 GLM 改进的一个方面。
与 XLNet 的比较
GLM 和 XLNet 都是通过自回归目标进行预训练的,但它们之间存在两个主要区别。首先,XLNet 在损坏之前使用原始位置编码。在推断时,我们需要知道或枚举答案的长度,这与 BERT 有相同的问题。其次,XLNet 使用双流自注意机制,而不是右移,以避免 Transformer 内的信息泄漏。这导致了预训练的时间成本加倍。
与 T5 的比较
T5 提出了一种类似的空白填充目标,以预训练编码器-解码器 Transformer。T5 为编码器和解码器使用独立的位置编码,并依赖于多个 sentinel 令牌来区分被掩蔽的片段。在下游任务中,只使用其中一个 sentinel 令牌,导致模型容量的浪费和预训练与微调之间的不一致性。此外,T5 总是按固定的从左到右顺序预测片段,而 GLM 在 NLU 和 seq2seq 任务上可以使用更少的参数和数据获得更好的性能。
与 UniLM 的比较
结合了不同的预训练目标,通过在自动编码框架中更改注意力掩码,实现了在双向、单向和交叉注意力之间的切换。然而,UniLM总是用[MASK]令牌替换掉掩蔽的片段,这限制了其建模掩蔽片段及其上下文之间依赖关系的能力。与之不同,GLM以自回归的方式输入前一个令牌并生成下一个令牌,提高了模型对片段和上下文之间依赖关系的建模能力。
UniLMv2在生成任务中采用了部分自回归建模,同时在NLU任务中使用自动编码目标。GLM通过自回归预训练来统一NLU和生成任务,使其在两者之间更加高效。
原文地址:https://blog.csdn.net/weixin_42010722/article/details/134599773
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_23968.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!