答:因为block在创建的时候,它的内存是分配在栈上的,而不是在堆区。栈区的特点是:对象随时有可能被销毁,一旦被销毁,在调用时就会造成崩溃。所以我们要使用copy吧它拷贝到堆区。
答:如果要在显示屏幕上述显示内容,我们至少需要一块屏幕一样大小的frame buffer(帧缓冲区),作为像素数据的储存区域,然后由显示器把帧缓存区的数据显示到屏幕上。如果有时因为一些限制比如:阴影,遮罩mask等,造成GPU无法把渲染的结果直接写入frame buffer中,而是先把中间的一个临时的状态存在另外的内存区域,之后在写入frame buffer,这个过程被称之为离屏渲染。离屏渲染的影响:需要额外的开辟内存,增大内存的消耗。需要多次切换上下文,从当前屏切换带离屏,从离屏切换到当前屏,上下文的切换是耗时的,可能会引起掉帧。
答:ro是在编译的时候的生成的。当类在编译的时候,类的属性,协议,方法。这些内容就存在ro这个解构题中,这是一个纯净的内存空间。不允许修改。
rw是在运行的时候生成的。它把ro的内容拷贝进去。实现访问类的方法,属性等内容访问rw中里面的的内容。修改也是修改里面的内容。
rwe的设计是为了节省内存。rwe只有添加分类且分类都为非懒加载类,汇总或通过runtime动态修改类的信息的时候才会存在。
答:三次握手:为了防止失效的链接请求报文突然又传到了服务器,因为产生了错误,假设这是一个早已失传的报文段。但server收到此失效的请求报文后,就向为client发出的确认报文,同时建立链接,假设不采用三次握手,那么只要server发出确认,新的链接就建立了。由于现在的client并没有发出建立连接的的请求,因此不会理睬server的确认,也不会发送数据,但是server却以为是新的连接已经建立,并一直等待client发来的数据,这样,server的很多资源就白白浪费了。
四次挥手:因为tcp是双向通信的,在接收到客服端的关闭请求是,还有可能在向客户端发送数据,因此不能再回应关闭的请求时,同时发送关闭的请求。
答:1. http是明文传输的安全性较差,https数据传输过程是加密的,安全性较好
2. https协议需要到申请证书,一般免费的证书较少,需要付费。
3.http比https传输快,因为http使用三次握手建立连接的时候,客服端和服务器需要传输3个包,https需要还要加上ssl握手的需要的9个包,所以一个12个包。
4.http和https的连接方式完全不一样,连接的端口也不一样一个是80,https是443。
5.https其实就是建立在SSL/TLSS上的http协议,所以https比http更耗服务器资源。
答:MVC:M是数据模型model,负责处理数据,以及数据改变是发出通知(notifuration,KVO),Moddel和View不能直接进行通信,这样会违背MVC设计模式。V是视图View,用来显示界面和用户进行交互,为了解耦一般不会直接持有或者操作数据层中的数据模型可以通过target–action,delegate,block等方式解耦;C是控制器Controller用来调节model和view之间的交互,可以直接与model,view进行通信,操作model进行数据更新,刷新view。优点:view,model低耦合,高复用,容易维护。缺点:大的交互界面controller的代码过于臃肿。
MVVM是MVC的一种演进,促使了UI代码和业务代码的分离,抽取controller中的逻辑代码放到Viewmodel中。M:数据模型model,V:就是view,vuew和controller都不能直接引用model,可引用viewmodel。controller尽量不能涉及业务逻辑,让viewmodel区处理,controller只是一个中间人,负责view的事件,调用viewmodel的方法,响应viewmodel的变化。vm:viewmodel负责业务逻辑,网络请求。使用viewmodel会增加代码,但是总体上减少了代码的复杂性。viewmodel之间可以依赖。优点:低耦合,可复用,数据流向清晰,而且兼容MVC便于代码的移植,并且viewmodel可以拆出来独立开发,方便测试。缺点:类会增大,viewmodel会越来越庞大,调用的复杂度增加,双向绑定会导致调式变的困难。注意:view引用viewmodel,但反过来不行,因为VM跟v
产生了耦合,不方便复用,viewmodel可以引用model但是反过来不行。
总结:mvvm其实就mvc的变种,mvvm只是mvc帮controller瘦身,把逻辑代码和网络请求分离出来。不让controller处理更多的东西,不会变得臃肿,mvc与mvvm按需进行灵活的选择。mvvm在使用使用双向绑定的技术,是的model变化是view自动变化。需要学习额外的响应式编程。
答:成员变量 默认是@protected,不会自动生成set和get方法,需要手动实现,不能通过点语法调用,只能->调用。属性 会自动生成带下划线的成员变量,set和get方法,可以通过点语法调用实际是调用set和get方法,注意分类中的属性没有set和get方法,必须自己手动实现。实例变量是与class初始化出来的对象是实例对象。
访问关键字: public声明公共的实例变量,任何地方到可以访问。private私有的变量只有当前类可以访问子类调用需要使用父类的set和get访问。
8 类簇?
答:类簇是Foundation框架中广泛使用的设计模式。类簇在公共抽象超类下对多个私有的具体子类进行分组。以这种方式对类进行分组简化了面对对象框架的公共可见体系结构,二不会降低其功能的丰富度。类簇是基于抽象工厂设计模式的。常见的类簇有个nsstring,nsarray,nsdictionary等,以数组为例,不管创建可变还是不可变的数组在alloc之后得到是一个__NSPlaceholderArray.而当我们init一个可变的数组之后,得到的_NSArrayO;如果有且只有一个元素,那就是__NSSingleObjectArrayI;有多个元素叫__NSArrayI;init出来可变数组是__NSArrayM;
优点:1可以抽象基类背后的复杂细节隐藏起来。2程序员不需要记住各种创建的具体类实现,简化了开发成本,提高了开发效率。3便于进行封装和组件化,4减少了if-else这样缺乏扩展性的代码。5增加新功能支持不影响其他代码。缺点:已有的类簇不好拓展。
运用场景:出现bug是可以通过崩溃报告的关键字,快速定位bug的位置。在实现一下固定且不需要修改的事物是,可以高效的选择使用类簇。例:针对不同版本,不同机型往往需要不同设置,这时可以选择使用类簇。app的设置页面,这种往往不需要经常修改可以使用类簇区创建大量的重复布局代码。
8 常用的设计模式?
答:单例模式: 在整个应用程序中共享一份资源。保证在程序运行过程中一个类只有一个实例对象,提供一个全局的访问点供外界访问,从而方便控制实例个数,节约系统资源。优点:提供一个且唯一的实例对象避免频繁的创建和销毁。缺点:延迟了生命周期,一直占用资源。如果两个单例循环依赖会造成死锁,所以尽量不去产生单例之间的依赖关系。
工厂方法模式:通过类继承创建抽象的产品,创建一个产品,子类创建并重载工厂方法以创建新产品。
抽象工厂模式:通过对象组合创建抽象产品,可以创建多系列产品,必须修改父类的接口才能支持新的产品。
代理模式:代理用来吃了事件的监听和参数传递,使用前先判断方法是否实现。避免找不到方法而崩溃。
装饰模式:在不改变原类文件和使用继承的情况下,动态的扩展一个对象的功能例:分类。
享元模式:使用共享的物件,减少同一个类对象的大量创建。如:uitableviewcell的复用。
观察者模式:其本质是一种发布–订阅模型。用来消除有不同行为对象之间的耦合,通过这一模式,不同对象可以协调工作。比如:kvo
命令模式:是一种将方法调用封装对象的设计模式,在ios中具体实现为NSInvocation。
答:1GCD的核心是C语言写的系统服务,执行和操作简单高效,因此NSOperation是通过GCD实现,换个说法就是GCD更高层次的抽象,这是他们之间做本质区别。因此如果希望自定义任务,建议使用NSOperation;2 依赖关系NSOperation可以设置两个的依赖,第二个任务依赖于第一个任务完成执行,GCD无法设置依赖关系,不过可以通过dippatch_barrirer_async来实现3kvo,NSOperation很容易判断当前的状态,对此GCD无法通过KVO判断。4优先级nsoperation可以设置自身的优先级,但是优先级高的不一定先执行,GCD只能设置队列的优先级,无法在执行的block设置优先级。5NSOperation是一个抽象类。效率GCD效率更高。
答:kvo是基于runtime机制实现的,kvo运用了isa-swizzing技术,将2个指针相互调换,就是黑魔法。1当某个类的属性对象第一次创建是,系统就会在运行期动态地创建该类的一个派生类:NSKVONotifying——xxx,在这个派生类中重新基类的任何被观察的属性的setter方法。1派生类在重新的setter方法实现真正的通知机制。每个类对象中都有一个isa指针指向当前类,当一个类对向的第一次被观察,那么系统会向isa指针指向动态生成的派生类,从而给被监控的属性值赋值是执行的事派生类。2键值观察通知依赖于NSObject的两个方法:wilchangvalueforkey和didchangevalueforkey;在一个被观察改变之前调用wilchangvalueforkey,当改变后调用didchangevalueforkey;3继而通过消息或者响应机制区调用observerValueForKey:ofObject:change:context:4removeObserver的时候isa指正回来
答:1分类是在运行时把分类的信息合并到类信息中,而扩展实在编译时,就不信息合并到类中
2分类声明的属性。时候在生成getter、setter方法声明,不会自动生成setter,getter,而扩展会自动生成。3分类不可用分类添加实例变量,而扩展可以4分类可以为分类添加方法,而扩展只能声明,不能实现。
内存管理
1 引用计数
oc类中实现了引用计数,对象直到自己当前被引用的次数。对象初始化计数为1,每次操作对象都会引起计数的变化;retain+1,release-1;当引用计数为0时,系统给对象发送dealloc消息销毁对象。
重点:凡是通过alloc,init,copy,mutableCopy,retain进行创建的对象多要使用relasee或者autorelease进行释放。自己生成的对象,自己持有,不是自己生产的对象,自己也能持有,不再需要时释放对象。非自己持有的对象无需是否
引用计数的存放:从64位开始,对象的引用计数存放在优化过的isa指针中,也可以存放在SideTable中。当优化过的isa指针中,引用计数过大存放不下时,就会存放在SideTable中。SideTables是一个哈希表,Key为对象指针,Value为对象内容具体存放的SideTable。SideTable包含自旋锁,引用计数表,弱引用表,有Runtime维护。SideTables查找或修改引用计数时是要加锁的,方便多个对象同时做操作。
MRC
ios5之前,需要手动去管理内存。需要引用对象是,发送retain消息,对象的引用计数+1;不需要时,发送release消息,对象引用计数-1;当引用计数为0时,自动调用对象的dealloc方法销毁对象,引用计数为0的对象,不能再使用release和其他的方法。
ARC
ARC也是基于引用计数,只是编译器在编译的时候自动在已有的代码中插入了适合内存管理代码(retain, release, copy, autorelease, autoreleasepool)以及在Runtime做一些优化。简单来说,回事代码自动加了retain,release,原先的MRC中需要手动添加的用来管理引用技术 的代码都由编译器来帮我们完成。
strong
强引用,指向一个对象时,对象引用计数加1;当对象没有一个强引用指向它时才会被释放。如果在声明引用时不加修饰,默认是strong
weak
弱引用,不会引起引用计数的变化;当对象被释放是,所以指向它的弱引用指针自动被设置为nil,防止野指针。给nil发送消息时,会直接return,不会调用方法,也不会crash。对象的SideTable中有一个weak表,对象的内存地址为key,value则是多有指向该对象的弱引用指针的数组。当对象销毁时,通过对象内存地址找到所有指向它的弱引用指针,设置为nil并删除。
assign
assign指针纯粹指向对象不会引用计数不会变化,当对象被释放是指针依然指向原来的内存地址,不能设置为nil,所以容易造成野指针。由此assign都用来修饰基本的数据类型如int,float,struct等值类型。值类型会被放入栈中,遵循先进后出的原则,由系统负责管理内存。引用类型会被放入堆中,需要我们手动管理内存或者RAC管理。
深拷贝,浅拷贝
深拷贝:copy出来的对象与原对象的地址不一样,修改对象不影响原对象。
浅拷贝:copy出来的对象与原对象的地址一样,修改就是修改原对象本身。
对于不可变的类型对象,copy为浅拷贝,对象引用计数+1;对于可变类型对象,copy为深拷贝,拷贝的对象为不可变的对象。对对象做mutableCopy操作,都为深拷贝,拷贝对象也不变的对象变成可变的对象。对容器类对象mutableCopy深拷贝的仅仅是容器本身,对其中的元素只做了浅拷贝。
声明NSString类型的属性,用copy还strong好?
由于多态的原因,NSString类型的属性,最终可以能指向NSMutabelString,为了防止原字符串的修改引起变化,最好采用copy来修饰。
如何自定义copy操作?
遵循copy协议<NSCopying, NSMutableCopying>重写copyWithZone, mutableCopyWithZone方法。
atomic,nonatomic
对atomic修饰的属性setter,getter方法添加了原子锁保证set,get操作的完整性,因为atomic添加了原子锁,会增加开销,运行速度慢,在不需要保证set,get的完整的情况下,所以一般使用nonatomic。atomic不能保证线程安全,只能保证set,get操作完整性当开启多个线程是无法保证执行的顺序。
循环引用
两个对象之间相互强引用,引用计数都依赖于对方,导致无法释放。例如:delegate,block,所以才引入了弱引用。持有对象,但不增加引用计数,这样就避免了循环引用。
内存泄漏,内存溢出
内存泄漏是指申请的内存空间在用完之后未释放,在ARC下根本原因是循环引起来的。内存溢出是指内存不足,程序申请的内存空间时,没有足够的内存可供使用了。
2 runtime
oc是一门动态地语言。动态语言是指程序在运行时可以改变其结构:添加新的函数,属性等结构上的变化,在运行时做类型的检查。oc的动态性由runtime支持,runtime是一个c语言的库,提供API创建类,添加方法,删除方法,交换方法等。
id
使用ID修饰的对象是动态类型,只是简单的声明对象的指针。编译时不做类型检查,可以发送任何消息给id类型的对象。
instancetype
表示某个方法返回未知类型的oc对象非关联类型的方法返回所在类的类型。instancetype可以返回和方法所在类相同的类型。id返回未知类型对象。instancetype只能做返回值,id还能做参数。
oc对象的本质
oc对象本身是一个结构体,这个结构体只有一个isa指针,任何数据结构,只要在恰当的位置有个指针指向一个class,那么它就可以被认为是一个对象。
什么是isa
Class isa;
}
super_class, name, version, info, instance_size, ivars, methodLists, cache,protocols
}
isa指向流程
实例对象的isa指向类对象
类对象isa指向元类
所有元类isa
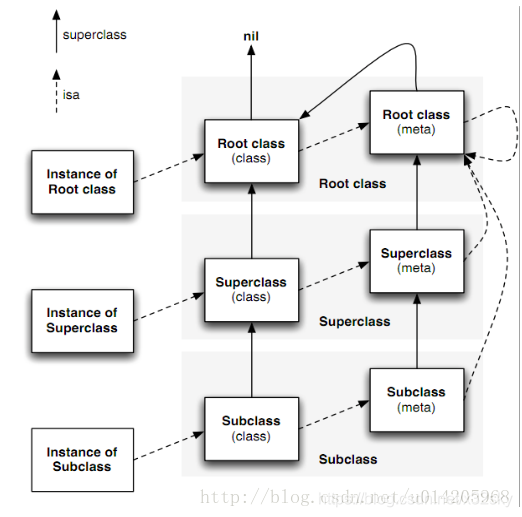
category-分类
category_name, class_name, instance_methods, class_methods,protocols
}
在程序运行时实例方法整合到主类中,类方法整合到元类中,协议同时整合到主类和元类中。
1 再类的+load方法中可以调用category里面声明的方法吗?
可以,因为附加的category到类的工作是先与+load方法
2 类和category的+load方法调用的顺序
先类,后category,而各个category的+load方法按编译的顺序。
3关联对象存在哪?
所以得管理对象都由AssociationsManager管理,AssociationsManager里面由一个静态的AssociationHashMap来存储所有的管理对象。
4在category里能添加属性吗?
category中只能添加方法,不能添加实例变量。类的内存大小是在编译的时候确定的,而category实在运行时被添加的,此时在添加会破坏类的结构。在category中添加属性,可以通过关联对象实现setter,getter方法。
5类和category的同名方法调用顺序
category并不是完全替换掉主方法的同名方法,只是类方法会在查找同名方法的时候查找排在前面的方法时就返回不再查找。类的方法优先级低于分类的方法。
6 分类与类的扩展区别
category运行时决议,有单独的.h,.m文件,可以为系统添加分类,看不到源码的类可以添加分类,只能添加方法,不能添加实例变量
extesion编译时决议,以声明的方式存在,没有单独的.h,.m文件,不可以为系统添加extension,可以声明方法,添加属性。
消息发送机制
在oc中,对调用方法其实是对象接收到消息,消息的发送采用动态发送的机制,具体那个方法直到运行时才确定,确定方法才绑定代码。oc对象调用方法在运行时会被转换为 void objc_msgSend(id self, SEL cdm,…);SEL方法名IMP指向方法实现的函数指针。
消息发送流程
1根据消息的接受者isa确定自己所属的类,先在类的cache和moethList中查找IMP;
2如果本类中没有找到,则会根据本类的superClass指针查找父类,一直向上。
消息转发流程
1 动态解析
+(BOOL)resolveInstanceMethod:(SEL)selecot;
+(BOOL)resolveClassMethod:(SEL)selecot;
2备用接受者
-(id)forwardingTargetForSelector:(SEL)selector;
3 消息重定向
最后未处理还调用-(void)dodeNotRecongnizeSleecor抛出异常。
Method swizzling
发生运行时的方法交换。先给要替换的方法中添加一个分类,然后在分类中+load调用。swizzling应在总在+load中,load时在程序加载到内存时候调用,执行早,并且不需要我们手动调用,并且总在dispatch_once执行,避免重复调用。
1,交换controller view的生命周期方法,页面统计
2,事件统计,防止按钮 短时间内重复点击交换UIContol sendAction:to:forEvent方法
3 交换delegate方法,hook setDelegate方法,最后假设是否实现delegate的方法的判断
4 防止数据越界崩溃,hook objectAtIndex需要获取类簇真身。
KVC
kvc是一种可以通过可以来访问类属性的机制。而不是通过setter, getter方法访问的。可以在运行时访问和修改对象的属性。setValue:forKey。 forKeyPath是对更深层的对象访问,如数组的莫个元素,对象的某个属性setValue:forKeyPath。
设值流程
1.首先在当前类中查找是否实现setKey,_setKey,setIsKey方法,如果有,则直接调用,没有则继续
2.判断 accessInstanceVariablesDirectly是否存在,如果返回NO,则报错,如果返回YES,继续
3.寻找实例变量列表,依次查找_key,_isKey,key,isKey,有则直接复制,没有则继续
4.如果找不到,则报错
1.首先依次查找getKey,_getkey方法,有则直接调用,没有则继续
2..判断 accessInstanceVariablesDirectly是否存在,如果返回NO,则报错,如果返回YES,继续
3.查找实例变量列表,依次查找_key,_isKey,key,isKey,有则直接复制,没有则继续
4.如果找不到,则报错
KVO
kvo键值监听,可以监听对象某个属性的变化区1给对象添加监听2通过runtime
动态创建一个子类,修改对象isa指向子类。3子类重写set方法,内部执行顺序。
归档接档
对象实现数列化需遵循NSCoding协议,通过runtime中的方法class_copyIvarList获取对象的属性列表马桶属性获取属性的名字,在利用kvc进行归档接档。
block
block 实际就是OC对于闭包的实现,闭包是一个函数,再加上该函数执行的外部的上下变量,block
本质上也是一个oc对象,因为它内部有isa指针,封装了函数调用以及函数调用环境的OC对象。
block原理
block是一个结构体,通常包含了连个成员变量:__blocj_impl,__bblck_desc和一个构造函数
void *isal//isa 指针指向一个类对象,有三种类型
void *funcPtr突然;//指向blcok执行时的函数指针
}
1 通过block结构体的构造函数生成一个实例,并用一个指针指向当前实例
block类型
没有访问auto变量,访问外部static或者全局变量还是全局block。
访问了外部的auto变量
全局block调用copy还是全局block,对block调用copy引用计数+1。
block捕获变量
考虑作用域的问题,在block中属于跨函数来访问局部变量,所以需要捕获。
auto变量存放在栈中,可能会被销毁,内存可能会消失,不采用指针访问;static一直内存中,采用指针访问
3 全局变量不需要捕获,直接访问
5 block里面访问成员变量先捕获self,然后通过self访问成员变量。
__block,__weak
__blcok对象可以在block中重新赋值,__weak不可以,使用__weak防止循环引用。__block修饰变量在block中保存了变量的地址有,引用计数+1,使它不会作用域的原因而销毁。__block不能修饰全局变量和静态变量。
weakSelf
如果block在栈空间不管外部变量是强引用还是弱引用,block都是对其弱引用。如果block在堆空间中如果外部是强引用,block对其强引用,如果是弱引用,block对其也是弱引用。
block是controller的属性,如果内部没有使用弱引用,会造成循环引用,从而内存泄漏。如果block不是controller的属性即使使用了self,不能造成内存泄漏
当使用类方式有block作为参数使用时,block使用self也不会造成内存泄漏。
多线程
进程:当一个程序进入内存运行,即变成了一个进程。进程是处于运行过程中的程序,并具有一定独立功能。
线程:线程是进程的一个执行单元,负责当前进程的执行,一个进程至少有一个线程。
对于CPU的一个核心而言,某个时刻只能执行一个线程,但是由于线程的切换相对于我们的关键非常快,感觉上就是同时进行的。多线程并不能提高程序的运行速度,但是能提高程序的运行速度,行效率
任务
执行操作的意思,就是要在现场中执行对的代码。
同步执行:同步添加任务到队列中,队列在任务结束之前一直等待,直到任务完成才继续执行下一个任务,只能在当前线程中执行任务,不具备开启线程的能力。
异步执行:异步添加任务到队列中,队列不会等待,可以继续执行其他的任务,可以在新的线程中执行任务,可以开启新的线程,但不一定开启新的线程。
队列
执行任务的等待队列,即用来存放任务的队列。队列是一种特殊的线性表,采用FIFO多原则。新的任务重视被插到队列的末尾,读取任务重视总头到尾开始读取。每读取一个任务,则从队列中释放一个任务。
串行队列:只开启一个线程,每次只能执行一个任务,当前任务执行完了才能执行下一个任务。
并发队列:可以让多个任务并发执行,可以开启多线程,并并同时执行任务。
主队列:是一种特殊的串行队列,添加到主队列的任务只能在主程序上执行。
任务+队列
同步执行+串行队列:不开启新的线程,串行执行
同步执行+主队列:线程死锁。原因:主队列,如果主线程正在执行代码,就不调度任务;同步执行:一直执行第一个任务直到结束。两者互相等待造成死锁
异步执行+串行队列:开启1个线程,串行执行
异步执行+主队列:不开启新的线程,串行执行
队列+任务+任务(任务里面还有个任务)
并发队列+异步执行+同步执行:不开启新的线程,串行执行。
并发队列+异步执行+ 异步执行:开启新的线程,并发执行。
并发队列+同步任务+同步任务:不开启新的线程,串行执行
并发队列+同步任务+异步执行:开启新的线程,并发执行,与第一个相反。
串行队列+异步执行+同步执行:串行队列只能一个一个执行,异步执行完成,队列才能完成。同步执行需要等待第一任务完成才能执行,才继续执行,异步又需要等待同步完成,才能继续,所以死锁。
串行队列+异步执行+异步执行:开启新的线程,串行执行
串行队列+同步执行+同步执行:线程死锁。
串行队列+同步执行+异步执行:开启新的线程,串行执行
异步执行不一定开启新的线程
因为主队列的任务都是在主线程里执行,而主线程是app启动就开启了,所以在主队列中添加异步执行不会开启线程
主队列添加同步任务会死锁
因为主队列是一个串行队列,串行队列的特点就是一个任务完成才能执行下一个任务,同步任务特点是必须等当前任务执行完了执行。从而造成了当前任务等待同步任务完成才继续往下执行到结束,同步任务要等待当前任务结束才执行,这样相互等待,而造成死锁。
线程安全
自旋锁和互斥锁
自旋锁是一种取锁时以忙等待的形式不断地循环检查是否可用。当上一个线程的任务没有完成时被锁住,那么下一个线程一直等待,当任务完成时下一个任务立即执行。在多CPU的环境下,多对持有锁较短的程序来说使用自旋锁往往能有效提高程序的性能。自旋锁会忙的,就是访问是调用者的线程不会休眠而是不能的循环等待,直到被锁资源释放锁。互斥锁会休眠。自旋锁不能递归调用
自旋锁:atomic,osspinlock,dispatch_scmaphorc_t
互斥锁:plhrend_mulex,nslock,nscoundtion@synchronizxl.等。
GCD
dispatch_barrier_async: 栅栏函数,等待前面的并发任务完成后,再将指定的任务追加到该异步队列中。
dispatch_after:延迟执行,不是在指定时间后执行,而是在指定的时间后将任务追加到主队列中。严格来讲,这个时间并不准确。
dispatch_once: 只执行一次,常用于创建单例。在多线程下线程安全的。
dispatch_group_notify: 监听group中的任务执行完成,然后把指定的任务追加到group中。
dispatch_group_wait:阻塞当前线程,等待指定的任务完成才往下执行。
dispatch_group_enter: 表示一个任务追加到group中
dispatch_group_leave:表示一个任务离开group。
dispatch_semaphore_create:信号量创建
dispatch_semaphore_singal:信号量+1
信号量<=0时会一直阻塞所在的线程,反正就可以正常执行
NSOperation, NSOperationQueue
NSOperation, NSOperationQueue是基于GCD更为高一层的对象封装。
1 可添加完整的代码块,在操作完成后执行
3 设置操作的优先级
4 可以方便取消操作
NSOperation: 操作,即GCD中的任务,将在线程中执行的代码块
NSOperationQueue:操作队列,不同与GCD的队列FIFO的原则。对于队列中的任务的操作,首先进入准备就绪状态(就绪状态取决于依赖关系),然后就绪状态的操作的开始执行顺序有操作之间的优先级决定。没有依赖关系的操作先进入就绪状态,根据优先级决定执行顺序;当前任务的依赖任务执行完毕,当前任务进入就绪状态。
通过最大并发数来控制并发和串行,默认是-1不做限制,可进行并发。为1时是串行,大于1是并发的。
暂停取消任务支队未执行的任务有效。如果任务正在执行和已执行的任务无效。
Runloop
默认情况下,线程执行完任务后就会退出,不再执行任务。我盟需要让线程能够不断的处理任务,并且不退出,所以有了runloop。runloop实际上是一个对象,这个对象在循环中用来处理程序运行过程中出现的各种事件(比如: touch事件,ui刷新,定时器,selector),从而保持程序的持续运行。runloop在没有处理事件时,会让线程进入休眠,只有在接收到事件才会被唤醒,然后在作出相应的处理。
一个线程对应一个runloop,主线程的runloop对象有系统自动创建。
runloop model
NSDefaultRunLoopModel:app默认Model,通常在主线程就是这个Model
执行。
NSTrackingRunLoopModel: 界面跟踪model。用于滚动视图在滚动的时候不受其他model影响。
UIInitiallizationRunLoopModel: 在刚启动app时的第一个model,启动完成后就不再调用。
GSEventReciveRunloopModel:接收系统事件的内部model。
NSRunloopCommonModel: 占位model, NSDefaultRunLoopModel和NSTrackingRunLoopModel的集合。
定时源,基于时间的触发器,基本上就是NSTimer。NSTimer默认在default模式下运行。
source1:基于port的源,通过内核和线程之间进行通信,接受,分发系统事件。
点击app内的某个按钮,先触摸到屏幕,屏幕就会把事件封装成Event传递给source1,source1唤醒runloop,然后将event分发给source0进行处理。
4处理source0
5如果有source1,跳动9
7线程进入睡眠,等待直到以下事件来唤醒线程:某一事件到达端口的源,定时器,runloop设置的时间超时
8通知观察者线程即将唤醒
9处理唤醒时收到的事件:如果用户定义的定时器,出来定时器的事件并重启runloop,跳会2;如果有输入源,传递相应的消息;如果Runloop被显示的唤醒且未超时,重启runloop跳回2。
性能优化
卡顿优化
屏幕显示的过程:CPU计数数据->GPU进行渲染->屏幕发出Vsync( 垂直同步)信号->成像。
假如屏幕已经发出了Vsync信号了,但是GPU还没渲染完成,那么只能显示上一个数据的成像,以致当前的帧数据无法显示丢失,这样产生了卡顿,当前计数好的数据只能等待下一个周期去渲染显示。由此解决卡顿的思路就是尽可能的减少CPU和GPU的消耗,60fps,16ms就会有一个垂直同步信号。
cpu优化
GPU优化
-
尽量减少视图数量和层次。
耗电优化
-
cpu处理
-
图像渲染
cup优化:尽量降低CPU,GPU的消耗,尽量减少定时器。优化读写,尽可能的避免频繁的读写操作,最好做到批量操作。读写大量重要数据时,可以用dispatch_io,它提供了基于GCD的异步操作文件的API,达到优化磁盘的访问。数据量大事,用数据库管理。
网络优化:多次访问请求的结果相同,尽量使用缓存,使用断点续传,否则网络不稳定时可能多少传输相同的数据,网络不可用时,不进行网络操作;让用户可以取消时间或者速度很慢的时候,设置请求超时。批量传输,如下载上传视频等。
定位优化:如果只是需要快速确定用户的位置,用CLLocationManager的requestLocation方法,定位硬件会自动断电。如不是导航降低定位的精准度,劲量不要实时更新定位,需要后台定位是,尽量设置pauseLocationUpdatesAutomatically为yes,不移动时,系统会自动暂停定位更新。
启动优化
冷启动:app不在系统中,用户点击启动app的过程,这是需要开启新的进程分配给app
app启动的最佳速度在400ms内,因此点击app图启动,然后Launch
Screen出现消失的时间就是400毫秒。启动最慢不能超过20s,否则app进程会被系统杀死。
冷启动的整个过程:app唤醒开始到AppDelegate中didFinshLauchWichOptions方法执行完毕,并执行main()函数的时机分界点,分pre–main和main()阶段。
冷启动优化:
1减少不必要的内置动态库
2代码瘦身,合并删除无效的objc类,分类,方法,c++静态全局变量等
3减少c++虚函数
5耗时操作不要在didFinshLauchWichOptions中执行
struct和class的区别
结构体是值类型,没有引用计数,不能因为循环引用出现内存泄漏。值类型是自动线程安全的。
内存分配在栈中,传递传递的相当于传递了一个副本,自动初始化构造函数
不能继承,不能被序列化为NSData对象。
class是引用类型,有引用类型,循环引用会导致内存泄漏
内存分配在堆中,地址是引用类型,引用传递
可以继承,可以序列化为NSData对象
swift关键词
open :修饰类可以在本模块或者引用了本模块的模块继承,如果是属性的话,可以被本模块或引入本模块重写。
public:修饰类(或者更低的privated),只能在本模块继承,如果是属性,也只能在本模块重写
internal:在本模块可以访问,在本模块外不可以访问。如果定义类或者是属性或者方法,不加修饰默认
private: 修饰属性只有本类可以访问。本类的扩展都无法访问
swift闭包
闭包是一个捕获全局上下文的常量或变量的函数。Swift 中的闭包与 C 和 Objective-C 中的代码块(blocks)
闭包的优点
2表达是闭包可以省略reture
3参数名称可以用$0$1来代替
4尾随闭包(函数最后一个参数是闭包)
值捕获:
非逃逸闭包:
逃逸闭包
闭包调用可能在函数结束后,调用逃离了函数的作用域。
在函数作用域内没有调用,而是赋值给一个变量,需要用escaping修饰。
逃逸闭包黑非逃逸闭包都是闭包作为函数的参数。
原文地址:https://blog.csdn.net/hblove321/article/details/129224418
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_23986.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!