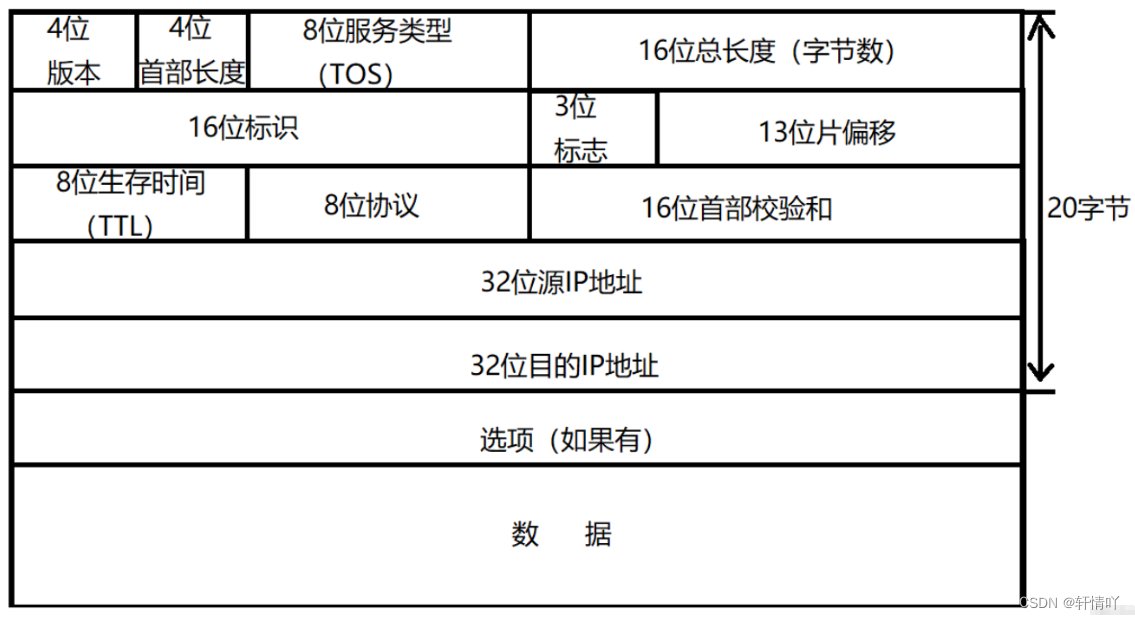
本文介绍: 在进行Python爬虫过程中,代理IP与访问控制是我们经常需要处理的问题。本文将介绍代理IP与访问控制相关的知识,并提供相应的代码案例。本文介绍了Python爬虫中代理IP与访问控制的知识,并提供了相应的代码案例。在进行爬虫时,需要遵守网站的Robots协议、设置访问时间间隔等,以避免被网站封禁IP或限制爬取速度。同时,使用代理IP也是爬虫过程中常用的手段,可以帮助我们顺利的爬取目标网站。
前言

一、代理IP
1.1.使用代理IP的步骤
1.2.寻找可用的代理IP
1.3.设置代理IP
1.4.验证代理IP的可用性
二、访问控制
2.1.遵守Robots协议
2.2.设置访问时间间隔
2.3.多线程爬取
总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。