本文介绍: 按照上面的方法,页面初始化的时候确实比之前快了很多,大概有一倍左右。不过直接跳转到最后一页,接口还是会有些缓慢。不过,对于上万条数据,也很少有人会直接跳转到最后一页进行搜索,毕竟上面也是有筛选条件可以进行筛选的。总而言之,也算是完成了性能优化。前端性能方案有很多种,比如 SSR,只是目前暂时还未了解,以后慢慢掌握。本篇文章介绍的方法只是其中比较特殊的一种,正常来说,我内心还是比较偏向于 gzip 压缩处理的。
前言
性能优化,是前端绕过不去的一道门槛,甚是重要。最近一年,也很少有机会在项目中进行前端性能优化,一直在忙于业务开发。
最近终于是来了机会,遇到了这样的场景,心里也甚是激动,写个随笔记录下性能优化的过程及逻辑,有需要的可以参考下。
场景
后端接口一下子返回了 9000 多条数据,而且不带分页参数,全部返回了。
说实话,刚联调接口的时候我也有点懵,也是第一次遇到这样的情况,于是询问后端同学为什么要这样。他回复我说是因为特殊需要,后端调的是大数据的接口,拿的是大数据团队的数据,技术方案评审时,要求数据不落表(我也不太懂后端这是什么意思)
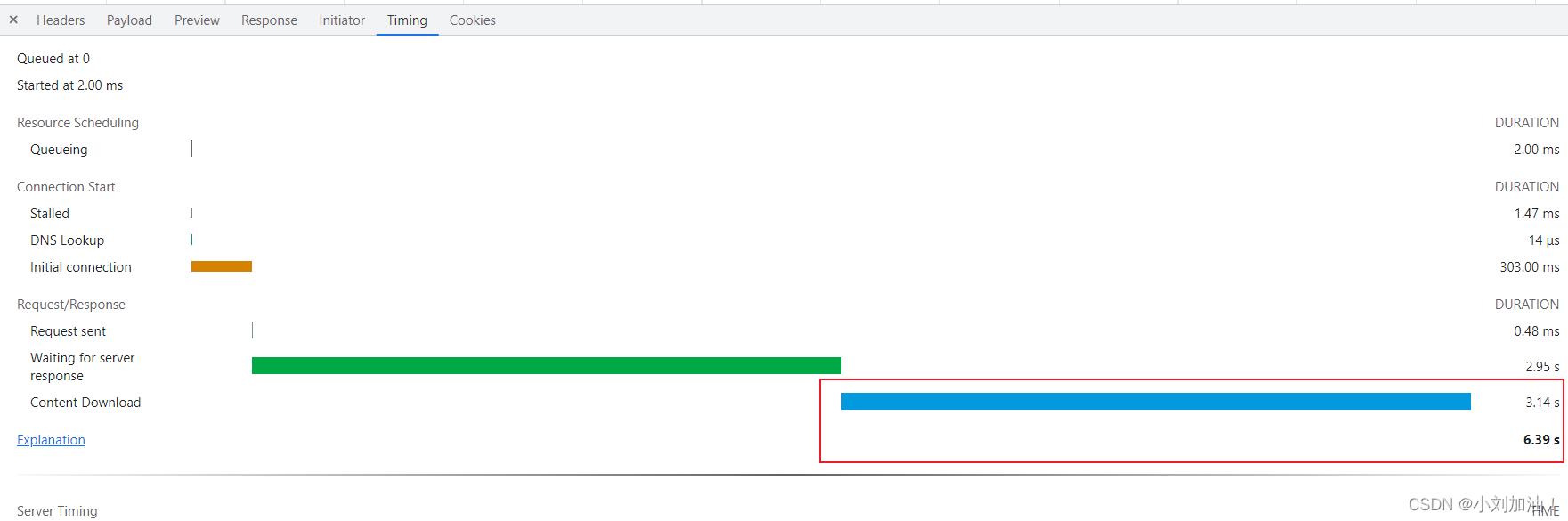
毫无疑问,将近一万条数据在前端渲染,百分之百的会造成卡顿。而且接口调用时间也会很长。
解决思路
1. 首先是前端分页
2. 优化返回字段
3. 最终优化(前端分页 + 后端分页)
思路:
总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。