SFD
Sparse Fuse Dense: Towards High Quality 3D Detection with Depth Completion
论文网址:SFD
论文代码:SFD
论文简读
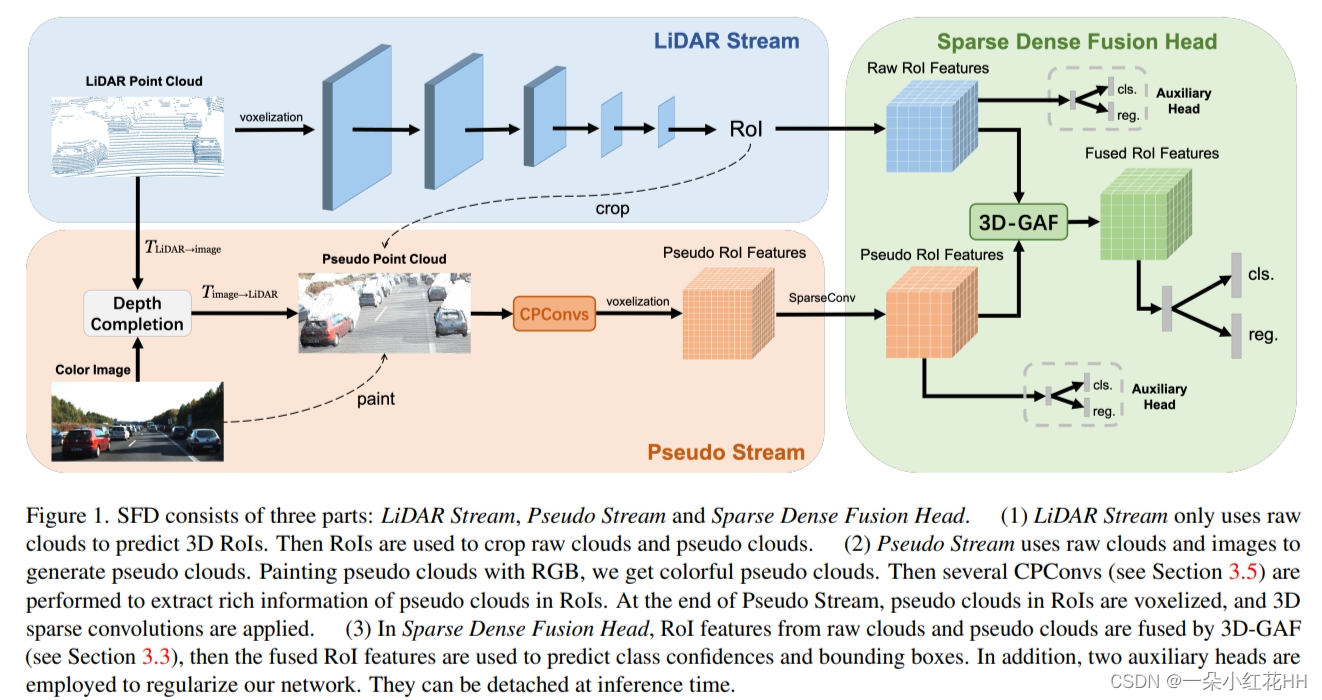
本文主要关注如何利用深度完成技术提高三维目标检测的质量。论文提出了一种名为 SFD(Sparse Fuse Dense)的新型多模态框架,以提高基于激光雷达(LiDAR)的三维目标检测性能。SFD 框架主要包括三个部分:激光雷达数据流、伪数据流和稀疏密集融合头。
论文的主要贡献包括:
这篇论文提出了一种新颖的多模态三维目标检测框架 SFD,通过深度完成技术生成伪点云,结合稀疏激光雷达点云数据,实现了高质量的三维目标检测。实验结果表明,SFD 在 KITTI 数据集上的性能优于其他先进方法。
摘要
当前仅使用 LiDAR 的 3D 检测方法不可避免地会受到点云稀疏性的影响。人们提出了许多多模态方法来缓解这个问题,而图像和点云的不同表示使得它们难以融合,从而导致性能不佳。本文提出了一种新颖的多模态框架SFD(稀疏融合密集),它利用深度补全生成的伪点云来解决上述问题。与之前的工作不同,本文提出了一种新的 RoI 融合策略 3D-GAF(3D Grid–wise Attentive Fusion),以更充分地利用来自不同类型点云的信息。具体来说,3D-GAF以网格方式融合来自点云对的3D RoI特征,粒度更细、更精确。此外,本文提出了 SynAugment(同步增强),使本文的多模式框架能够利用专为仅 LiDAR 方法量身定制的所有数据增强方法。最后,本文为伪点云定制了一个有效且高效的特征提取器CPConv(Color Point Convolution)。它可以同时探索伪点云的2D图像特征和3D几何特征。本文的方法在 KITTI 汽车 3D 目标检测排行榜上名列前茅,证明了 SFD 的有效性。
引言
近年来,深度学习和自动驾驶的兴起带动了3D检测的快速发展。目前的3D检测方法主要基于LiDAR点云,而点云的稀疏性极大地限制了其性能。稀疏的 LiDAR 点云在远处和遮挡区域提供的信息很差,因此很难生成精确的 3D 边界框。许多多模态方法被提出来解决这个问题。 MV3D 引入了RoI融合策略来融合第二阶段图像和点云的特征。 AVOD 建议融合图像特征图和 BEV 特征图的全分辨率特征裁剪,以实现高召回率。 MMF 利用 2D 检测、地面估计和深度补全来辅助 3D 检测。在MMF中,伪点云用于主干特征融合,深度补全特征图用于RoI特征融合。尽管他们取得了巨大的成功,但他们有两个缺点。
Coarse RoI Fusion Strategy. 在融合RoI特征时,如图2(a)所示,以前的RoI融合方法将从BEV LiDAR特征图裁剪的2D LiDAR RoI特征和从FOV图像特征图裁剪的2D图像RoI特征连接起来。本文注意到这种 RoI 融合策略是粗糙的。首先,2D 图像 RoI 特征通常与其他物体或背景的特征混合,这会混淆模型。其次,RoI 融合策略忽略了 2D 图像和 3D 点云中的对象部分对应关系。本文提出了一种更细粒度的RoI融合策略3D-GAF(3D Grid–wise Attentive Fusion),它融合3D RoI特征而不是2D RoI特征,如图2(b)所示。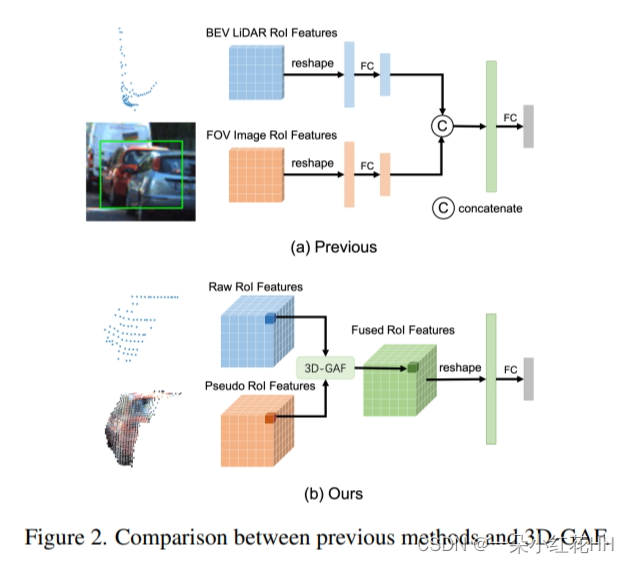
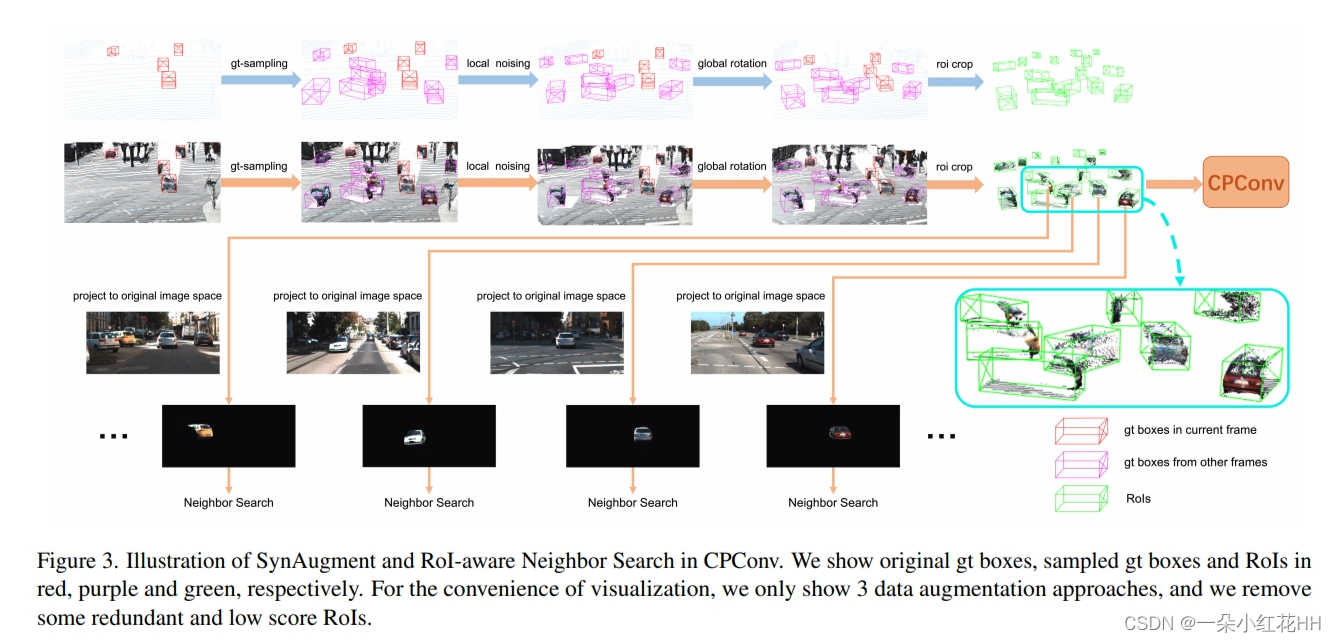
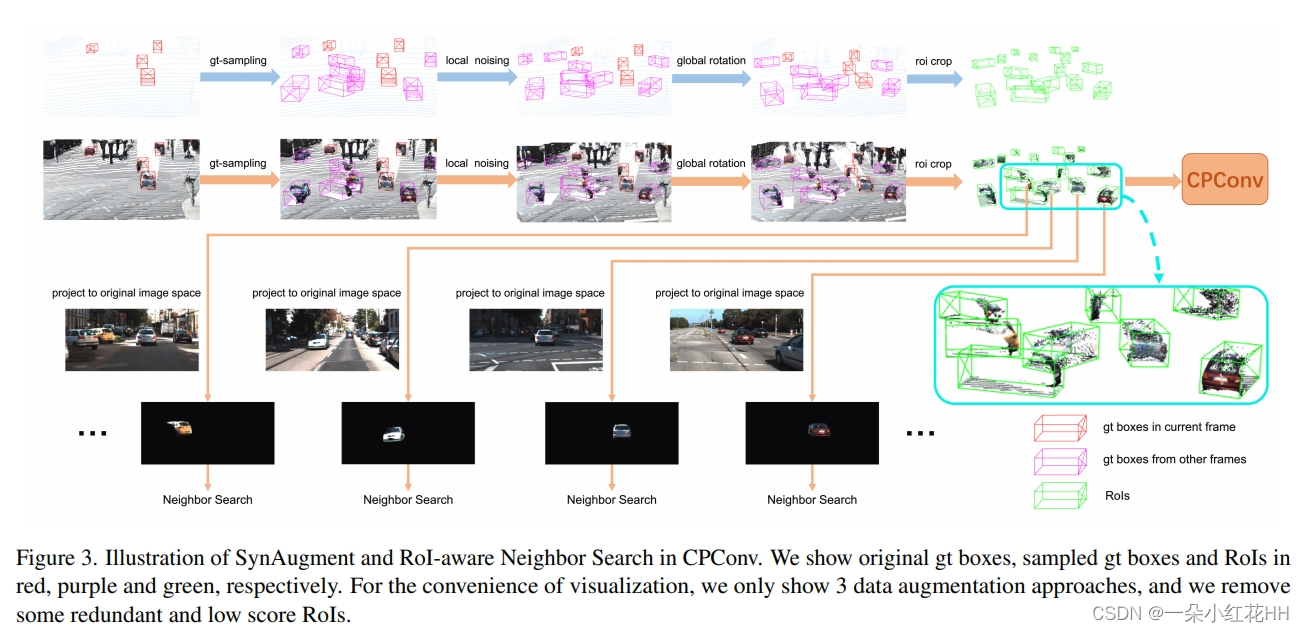
Insufficient Data Augmentation. 大多数多模态方法都存在这个缺点。由于 2D 图像数据无法像 3D LiDAR 数据一样进行操作,因此许多数据增强方法很难在多模态方法中部署。这是多模态方法通常不如单模态方法的一个关键原因。为此,本文引入了SynAugment(同步增强)。本文观察到,将 2D 图像转换为 3D 伪点云后,图像和原始点云的表示是统一的,这表明本文可以像操作原始点云一样操作图像。然而,这还不够。一些复杂的数据增强方法,例如 gt 采样 和局部旋转 可能会导致 FOV(前视)遮挡。这是一个不可忽视的问题,因为需要在 FOV 上提取图像特征。现在,是时候跳出思维定势了。将2D图像转换为3D伪点云后,为什么不直接提取3D空间中的图像特征呢?这样,就不再需要考虑FOV遮挡问题了。
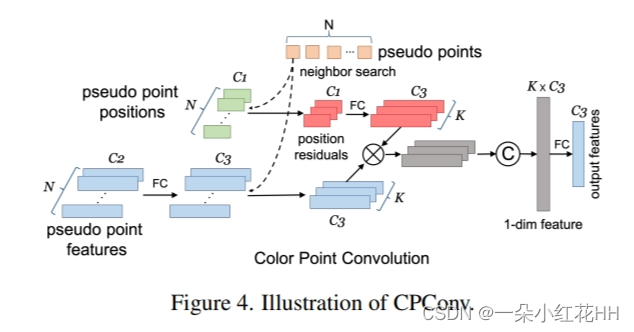
然而,在 3D 空间中提取伪点云特征并非易事。因此,本文提出了 CPConv(Color Point Convolution),它在图像域上搜索伪点的邻居。它使我们能够有效地提取伪点云的图像特征和几何特征。考虑到FOV遮挡问题,不能将所有伪点投影到当前帧的图像空间进行邻居搜索。在这里,本文提出了一种 RoI 感知邻居搜索,它将每个 3D RoI 中的伪点投影到其原始图像空间,如图 3 所示。因此,在执行邻居搜索时,FOV 上相互遮挡的伪点不会成为邻居。换句话说,它们的功能不会互相干扰。
总而言之,本文的贡献如下:
![[H数据结构] lc295. 数据流的中位数(对顶堆+技巧+思维+代码实现)](http://www.7code.cn/wp-content/uploads/2023/11/ee6748cbc735e6105405f8a984d954c804b93f34bc916-Z0IqTf_fw1200.png)



![[论文阅读]DeepFusion](https://img-blog.csdnimg.cn/direct/2b6ad8a8d2fd479eb49521c3d44a102b.png)
