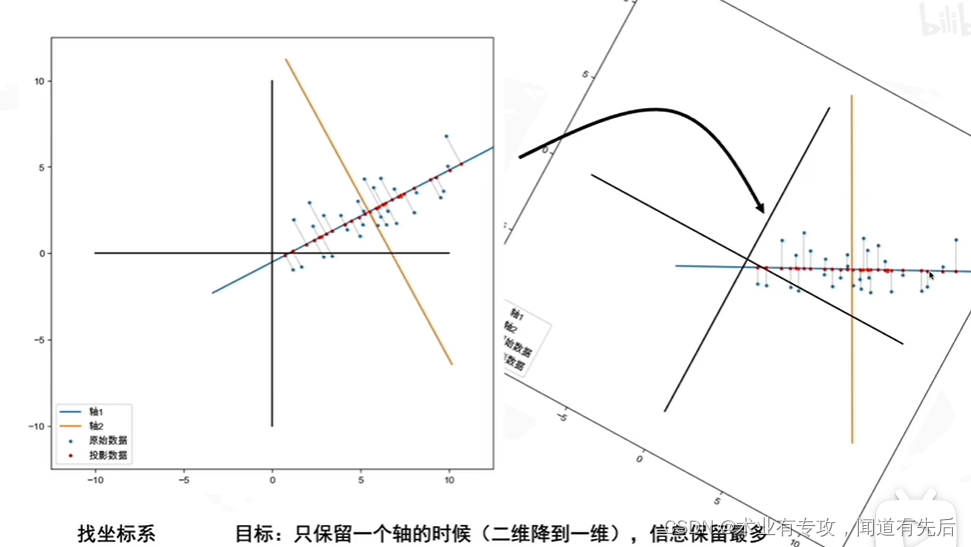
本文介绍: 具体来说,第一主成分是数据中方差最大的特征(即该特征下的值的方差最大),数据点在该方向有最大的扩散性(即在该方向上包含的信息量最多)。第二主成分与第一主成分正交(即与第一主成分无关),并在所有可能正交方向中,选择方差次大的方向。然后,第三主成分与前两个主成分正交,且选择在其余所有可能正交方向中有最大方差的方向,以此类推,中,紫色线方向上数据的方差最大(该方向上点的分布最分散,包含了更多的信息量),则可以将该方向上的特征作为第一主成分。表示已经中心化后的值),协方差矩阵的计算(二维)
即为降维后的数据。
3. 代码实践
from sklearn.neural_network import MLPClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report,confusion_matrix
import numpy as np
import matplotlib.pyplot as plt
# 载入手写体数据集并切分为训练集和测试集
digits = load_digits()
x_data = digits.data
y_data = digits.target
x_train, x_test, y_train, y_test = train_test_split(x_data,y_data)
x_data.shape
运行结果
(1797, 64)
# 创建神经网络模型,包含两个隐藏层,每个隐藏层的神经元数量分别为
# 100和50,最大迭代次数为500
mlp = MLPClassifier(hidden_layer_sizes=(100,50) ,max_iter=500)
mlp.fit(x_train,y_train)
# 数据中心化
def zeroMean(dataMat):
# 按列求平均,即各个特征的平均
meanVal = np.mean(dataMat, axis=0)
newData = dataMat - meanVal
return newData, meanVal
# PCA降维,top表示要将数据降维到几维
def pca(dataMat,top):
# 数据中心化
newData,meanVal=zeroMean(dataMat)
# np.cov用于求协方差矩阵,参数rowvar=0说明数据一行代表一个样本
covMat = np.cov(newData, rowvar=0)
# np.linalg.eig求矩阵的特征值和特征向量
eigVals, eigVects = np.linalg.eig(np.mat(covMat))
# 对特征值从小到大排序
eigValIndice = np.argsort(eigVals)
# 从eigValIndice中提取倒数top个索引,并按照从大到小的顺序返回一个切片列表
# 后一个 -1 表示切片的方向为从后往前,以负的步长(-1)进行迭代
n_eigValIndice = eigValIndice[-1:-(top+1):-1]
# 最大的n个特征值对应的特征向量
n_eigVect = eigVects[:,n_eigValIndice]
# 低维特征空间的数据
lowDDataMat = newData*n_eigVect
# 利用低纬度数据来重构数据
reconMat = (lowDDataMat*n_eigVect.T) + meanVal
# 返回低维特征空间的数据和重构的矩阵
return lowDDataMat,reconMat
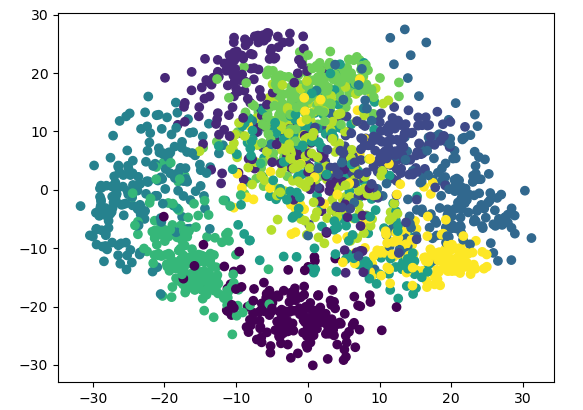
# 绘制降维后的数据及分类结果,共10个类
lowDDataMat, reconMat = pca(x_data, 2)
predictions = mlp.predict(x_data)
x = np.array(lowDDataMat)[:,0]
y = np.array(lowDDataMat)[:,1]
plt.scatter(x,y,c=y_data)
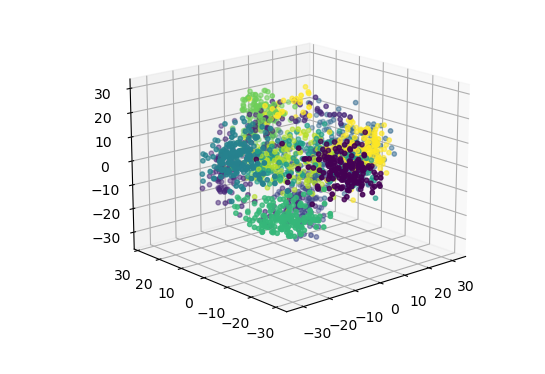
# 将数据降为3维
lowDDataMat, reconMat = pca(x_data,3)
# 绘制三维数据及分类结果,共10个类
x = np.array(lowDDataMat)[:,0]
y = np.array(lowDDataMat)[:,1]
z = np.array(lowDDataMat)[:,2]
ax = plt.figure().add_subplot(111, projection = '3d')
ax.scatter(x, y, z, c = y_data, s = 10) #点为红色三角形
原文地址:https://blog.csdn.net/m0_53062159/article/details/134606400
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_2501.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。

![[PyTorch][chapter 5][李宏毅深度学习][Classification]](http://www.7code.cn/wp-content/themes/ripro-v2/assets/img/thumb-ing.gif)