前言
深度学习pytorch系列第三篇啦,之前更了FC,NN,这篇是卷积神经网络(cNN)模型实现手写数字识别,依然是重在理解哈,具体的理解内容我都以注释的形式放在了代码中,我就直接放代码了,因为我把一些知识点和理解的东西用注释的形式写了
Q1:卷积网络和传统网络的区别
传统网络只适合结构化数据,不适合图像数据,由于图像数据的数据量大(表现为像素点多),传统网络需要使用的参数量太大
Q2:卷积神经网络的架构
卷积神经网络包括:输入层,卷积层,池化层,全连接层
重点介绍卷积层!!
卷积就是针对每个区域去计算特征。可以这样做的原因是:图片是有像素点构成的,针对每个像素点进行处理,需要的参数量过于庞大,并且相邻的像素点之间是存在联系的
特征图的个数与卷积核的个数一致。每个卷积核通过对输入特征图进行卷积操作,生成一个输出特征图。因此,卷积核的个数决定了输出的特征图的个数。
使用不同的卷积核学习同一个位置,可以得到不同的特征图,从而使特征多样化
卷积核的大小一般使用3*3
卷积核的大小规格一般是固定的,卷积核的数量理论上是越多越好
卷积层涉及的参数有:滑动窗口步长,卷积核尺寸,边缘填充,卷积核个数
卷积结果计算公式:长:h2=(h1-Fh+2p)/s +1 宽:w2=(w1-Fw+2p)/s +1
其中:w1,h1表示输入的宽度,长度;w2和h2表示输出特征图的宽度、长度,F表示卷积核的长和宽,s表示滑动窗口的补偿,p表示边界填充
经过卷积操作后,特征图的长和宽也可以保持不变
池化层的作用就是筛选好的特征,pool是只筛选位置的,channel是全部使用的
池化也称为下采样,(一次只能下采样原来的一半,不能直接224-16)
卷积神经网络由多个block组成,重点就在于怎么设计这个block的组成
关于卷积神经网络的层数,带权重参数的就算是一层,6个conn+1个fc,就可以说是7层网络结构
Q3:卷积神经网络中的参数共享,也是比传统网络的优势所在
同一个卷积核在各个位置上的参数都是一致的
权重参数的个数与输入数据的大小无关
4、 具体的实现代码+网络搭建
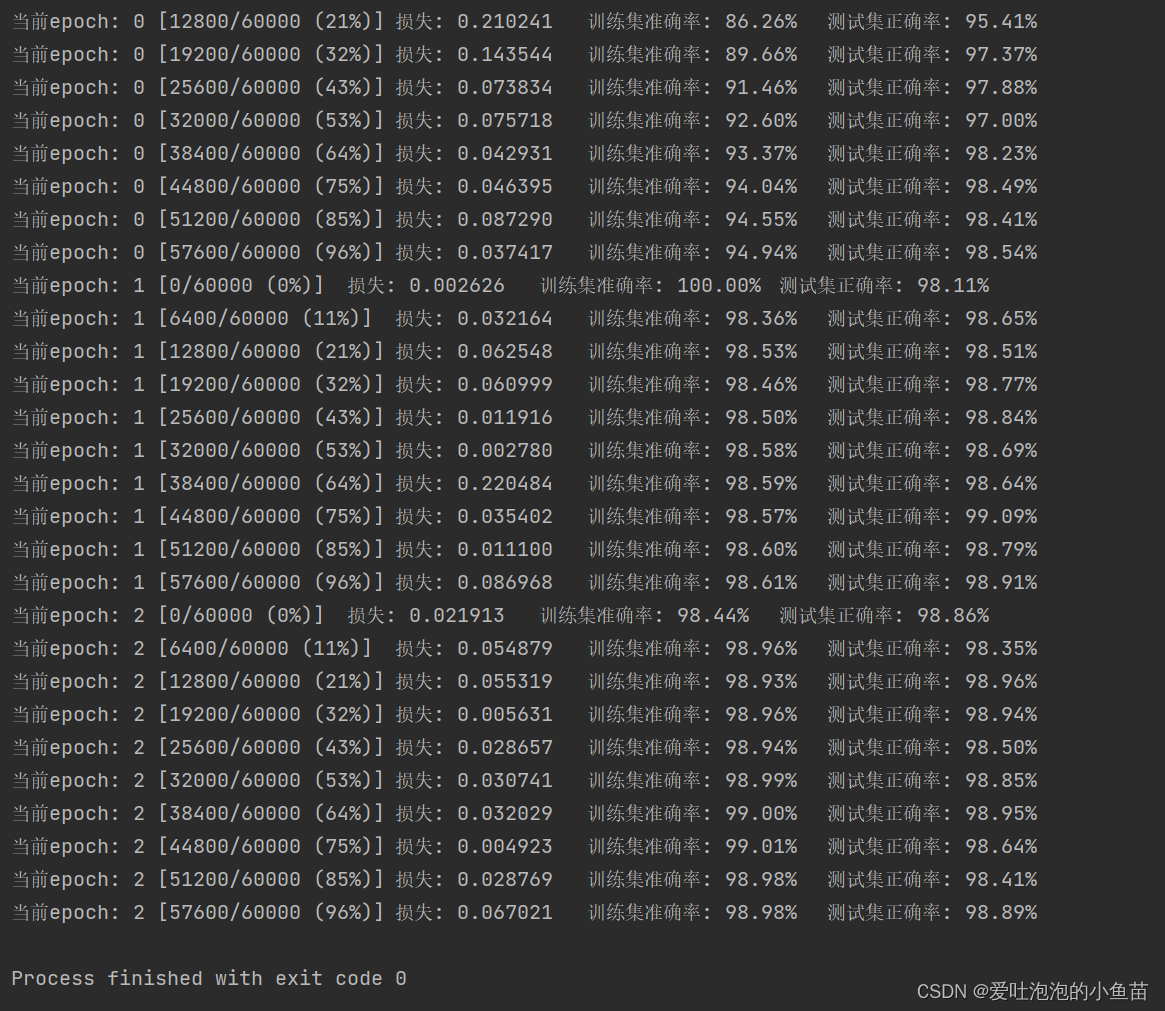
实现结果