目录
Part.01 关于HDP
Part.02 核心组件原理
Part.03 资源规划
Part.04 基础环境配置
Part.05 Yum源配置
Part.06 安装OracleJDK
Part.07 安装MySQL
Part.08 部署Ambari集群
Part.09 安装OpenLDAP
Part.10 创建集群
Part.11 安装Kerberos
Part.12 安装HDFS
Part.13 安装Ranger
Part.14 安装YARN+MR
Part.15 安装HIVE
Part.16 安装HBase
Part.17 安装Spark2
Part.18 安装Flink
Part.19 安装Kafka
Part.20 安装Flume
十五、安装HIVE
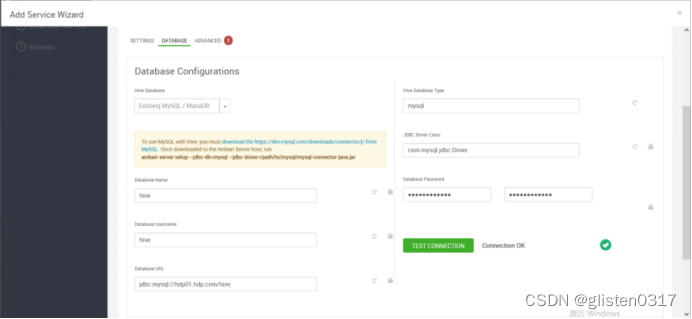
1.配置MetaStore
利用ambari创建的MySQL作为MetaStore,创建用户hive及数据库hive
2.安装
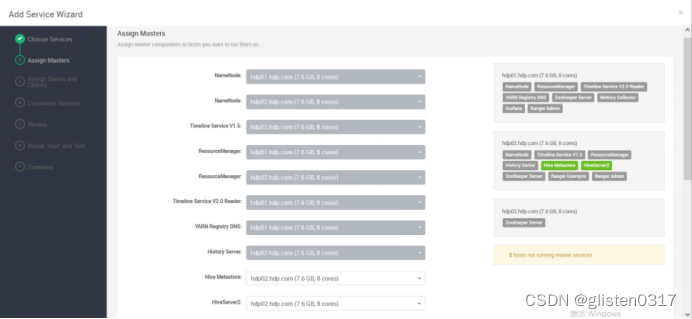
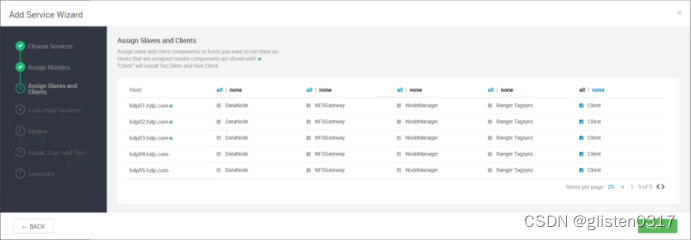
在服务中添加Hive
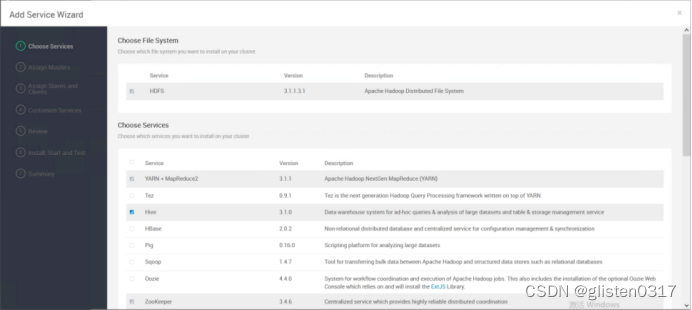
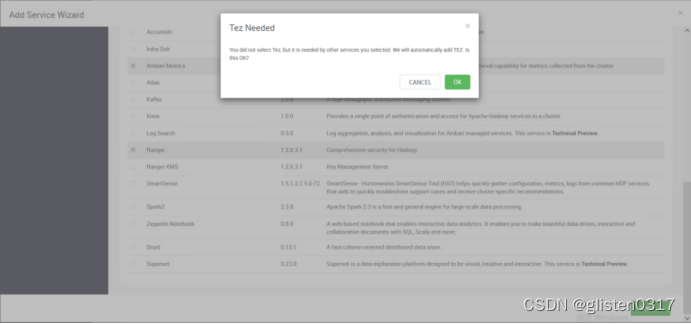
安装hive时需要同步安装Tez
DATABASE
Hive Database:Existing MySQL / MariaDB
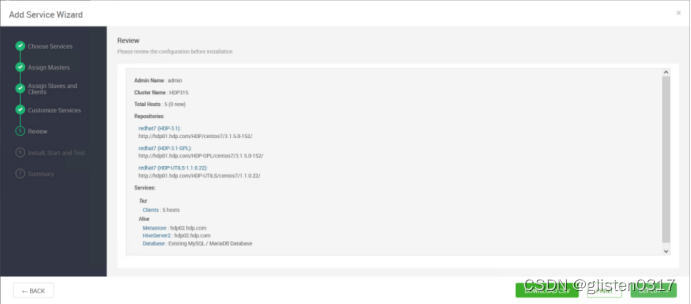
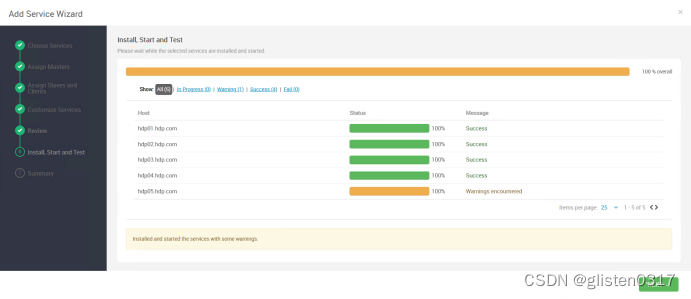

安装完成后,需要按照提示将hdfs、yarn等服务进行重启。
Ambari安装后,Hive使用了Tez作为计算引擎,也可以修改为MR或Spark,在配置文件中调整,/usr/hdp/3.1.5.0-152/hive/conf/hive-site.xml
3.高可用
(1)MetaSore HA
ACTIONS->Add Hive Metastore
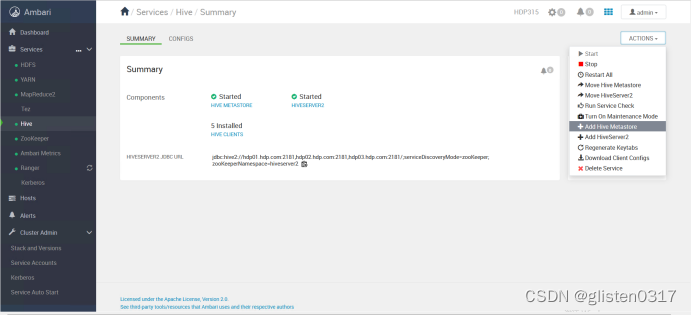
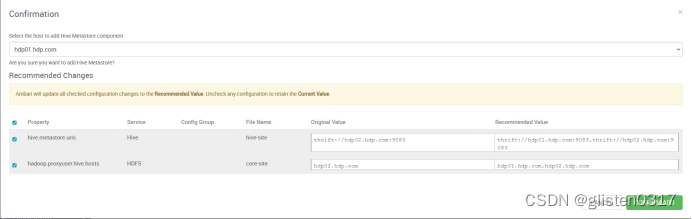
重启相关服务后完成HA启用。
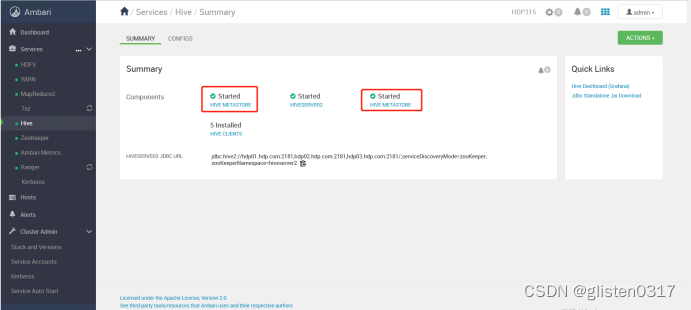
(2)HiveServer2 HA
ACTIONS->Add HiveServer2
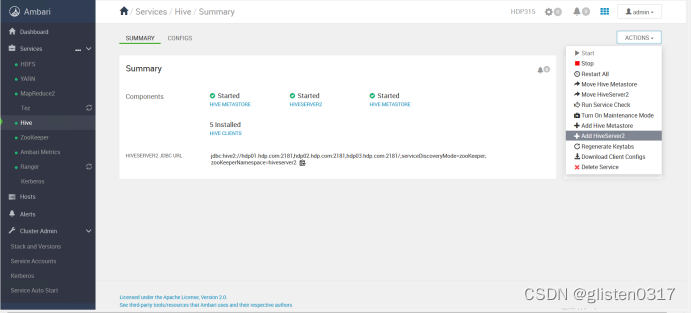
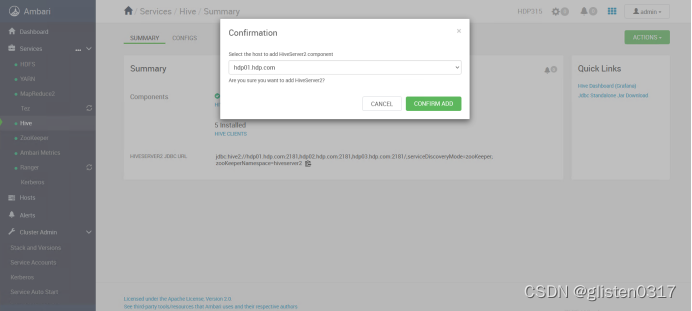
重启HIVE和Tez服务后完成HA启用。
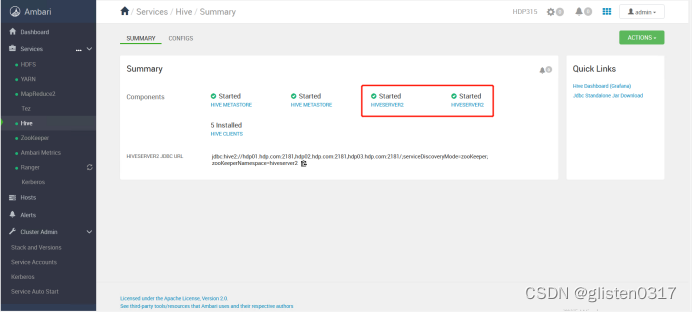
4.Ranger授权
在Ranger上新建策略完成对租户的授权
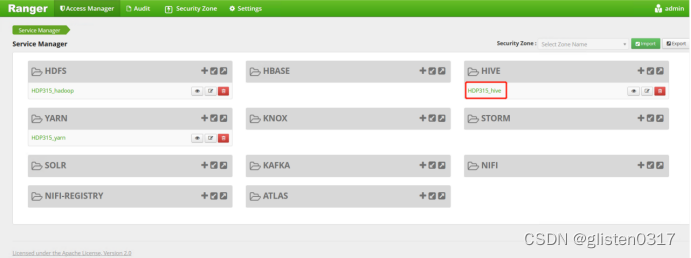

权限策略可以精细到列
5.常用指令
(1)CLI连接


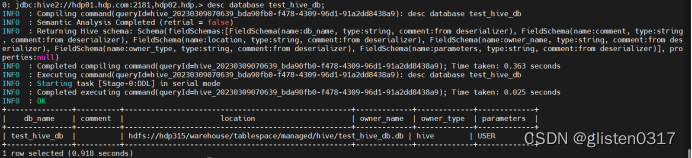
(2)Beeline连接
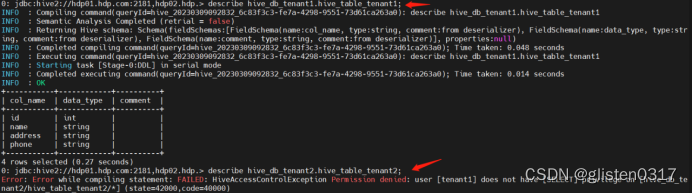
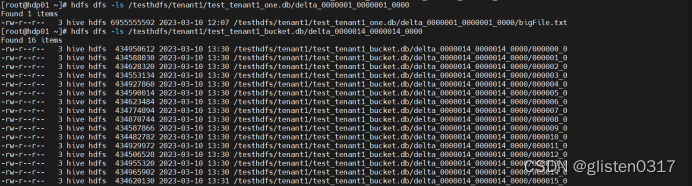
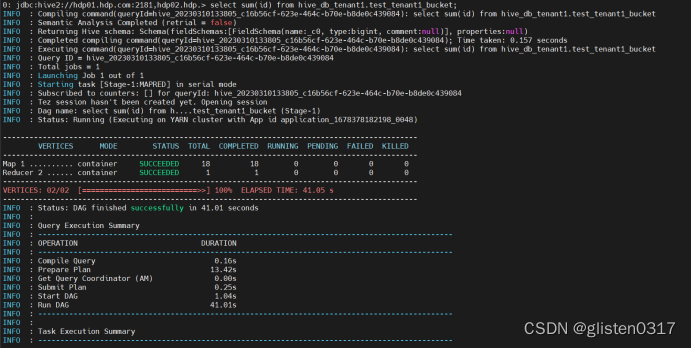
(3)导入数据等测试

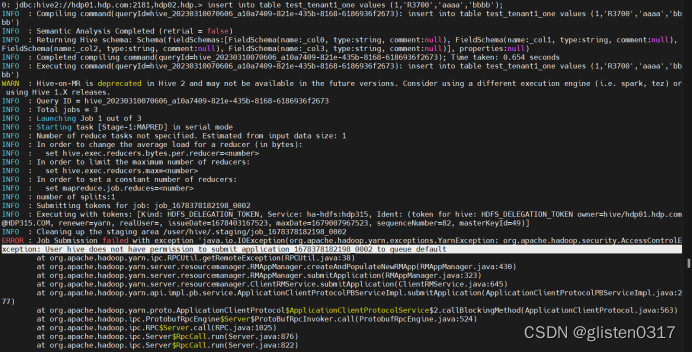
6.常见报错
(1)提示没有权限调用default队列
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。