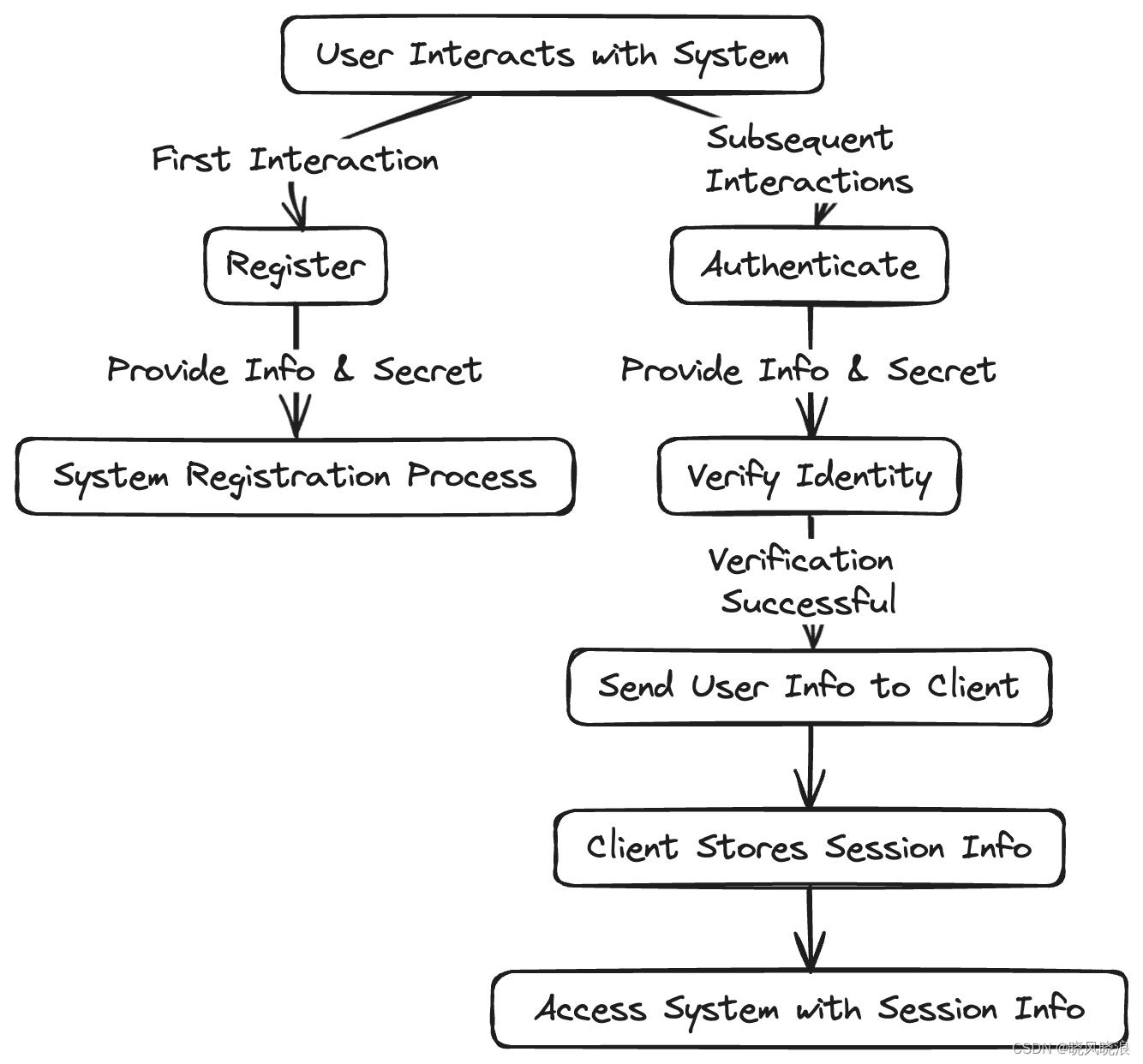
本文介绍: 1*HDp3_wvu78Vaa-4C9NFHaQ.gif你是否曾听说过避免在Kubernetes中运行数据库的建议?有人认为Kubernetes不适合有状态的应用程序,但这些说法是否属实?让我们深入探讨并挑战这些说法。Kubernetes:有关有状态工作负载的误解平台在涉及有状态应用程序时,Kubernetes经常受到不公平的抨击。这种误解源自早期阶段,当时我们的选择局限于部署(Deploymen…


声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。