NSDT工具推荐: Three.js AI纹理开发包 – YOLO合成数据生成器 – GLTF/GLB在线编辑 – 3D模型格式在线转换 – 可编程3D场景编辑器 – REVIT导出3D模型插件 – 3D模型语义搜索引擎
欢迎来到我们的强化学习系列的第三部分。 在上两篇博客中,我们介绍了强化学习中的一些基本概念,并研究了多臂bandit问题及其求解方法。 这篇博客会有点长,因为我们将首先学习一些新概念,然后应用深度学习来构建深度 RL 代理。 然后我们将训练该代理来平衡车杆。
1、车杆平衡问题
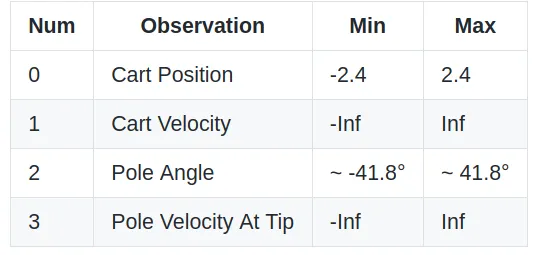
我们将使用 OpenAI GYM 提供的 CartPole-v0 环境。 为了完整起见,我仍然在此处包含完整的环境描述。
一根杆子通过非驱动接头连接到小车上,小车沿着无摩擦的轨道移动。 杆子开始时是直立的,目标是通过增加和降低小车的速度来防止杆子翻倒。

uua
动作空间:只有两种可能的动作:向左或向右,对应于智能体可以推动车杆的方向。
起始状态:所有观测值都分配有 ±0.05 之间的统一随机值。
求解要求:当 100 次连续试验的平均奖励大于或等于 195.0 时,视为已解决。
2、随机代理的行为
我们将首先检查随机代理可以获得的平均奖励。 我所说的随机代理是指随机选择动作的代理,即不使用任何环境信息。 在我的例子中,运行此代码片段的平均奖励为 23.3。 根据你的情况,它可能会略有不同。 但问题仍然远未解决。
from torch import randint
import gym
rew_arr = []
episode_count = 100
env = gym.make('CartPole-v0')
for i in range(episode_count):
obs, done, rew = env.reset(), False, 0
while (done != True) :
A = randint(0,env.action_space.n,(1,))
obs, reward, done, info = env.step(A.item())
rew += reward
rew_arr.append(rew)
print("average reward per episode :",sum(rew_arr)/ len(rew_arr))average reward per episode : 20.383、真正的问题!
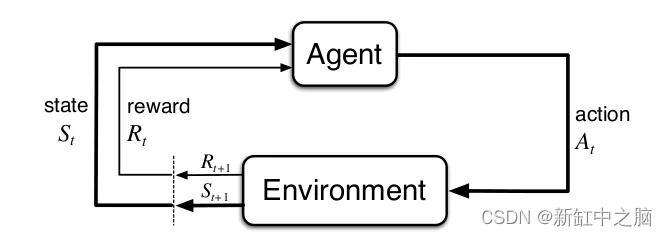
根据从环境中收到的观察结果和奖励,代理选择一些操作。 代理必须有一些策略,根据它来选择操作。 仅仅有一个策略是不够的,代理必须有一个机制来改进这个策略,因为它与环境的交互越来越多。 现在(其中一些)问题是:
4、深度学习的引入
理想情况下,我们应该首先用传统方法讨论这些问题,但这将使这篇博客变得很长。 总而言之,我们仍将使用传统方法,但使用深度神经网络作为函数逼近器。 在没有深度神经网络的情况下,要应用这些算法,我们需要存储一个尺寸为 S x A 的表,其中 S 是可能状态的数量,A 是在环境中可以采取的操作的数量。 即使有一个简单的环境,这个表也太大了,无法在实践中使用。
- 在深度学习中,我们使用神经网络作为函数逼近器。 我们可以通过深度神经网络来表示我们的策略。 该神经网络将查看给定的观察结果,并告诉我们在当前状态下最好采取哪种行动。 我们将此类深度神经网络称为策略网络(Policy Network)。
- 通过策略评估,我们的意思是检查当前的政策有多“好”或“有影响力”。 策略网络的损失值(Loss)可以用来检查这一点。 在本博客中,我们将使用预测回报和目标回报之间的均方误差来评估我们的策略网络。
- 策略评估步骤为我们提供了当前策略网络的损失值。 有了这些信息,我们可以使用梯度下降来优化策略网络的权重,以最大限度地减少这种损失。 这样可以完善策略网络。
5、Deep Q-Network
DQN 是 Q 值函数逼近器。 在每个时间步,我们将当前环境观察结果作为输入传递。 输出是与每个可能的动作(action)相对应的 Q 值。
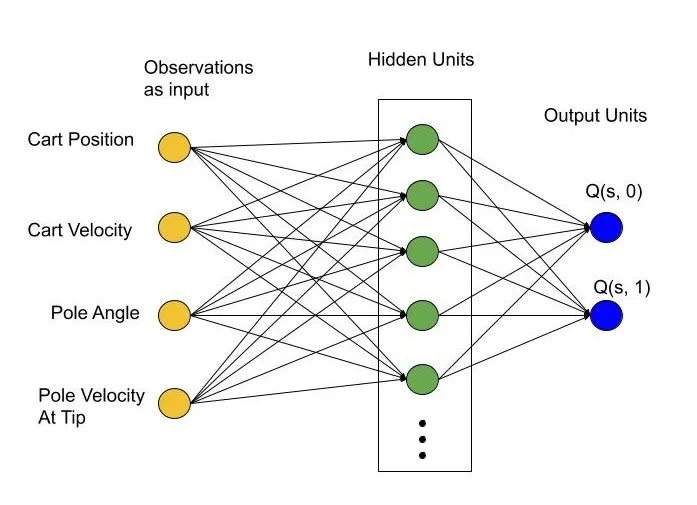
但是等等……基本事实在哪里???
在监督学习中,我们有一个与每个输入数据点相对应的基本事实(ground truth)。 可以将网络预测与相应的基本事实进行比较,以评估其性能。 但在这里我们没有基本事实,或者至少没有流行意义上的事实。
在大多数情况下,我们没有环境的确切动态。 这意味着即使环境动态已知,我们也不完全知道在某种状态下选择动作的价值,那么我们需要运行代理-环境交互足够长的时间,或者理想情况下直到情节(episode)结束。 然后我们可以返回并更新真实值。 请注意,这也意味着我们需要存储整个交互序列,这在大多数情况下是不可行的。
5.1 用奖励折扣作为基本事实
一种可行的方案是采用折扣奖励作为基本事实。在状态 s 采取动作 a的奖励值即 q(s, a) 可以写为:
q(s{t}, a{t} ) = R{t} + γ * R{t+1} + γ² * R{t+2} + γ³ * R{t+3} + …….其中γ为折扣因子,其值属于区间[0,1]。 这里的想法是,我们不仅关心眼前的奖励,而且还关心采取此行动后可能产生的未来奖励。
折扣率决定了未来奖励的现值:未来 k 个时间步收到的奖励的价值仅为 pow(γ ,k-1) 乘以立即收到的奖励的价值。
q(s{t}, a{t} ) = R{t} + γ * MAX-OVER-ACTION q( s(t+1), a)5.2 DQN的训练方法
- 初始化游戏状态并获得初始观察结果。
- 将观测值(obs)输入到Q-network,得到每个动作对应的Q-value。 将 q 值的最大值存储在 X 中。
- 以一定的概率epsilon选择随机动作,否则选择与最大 q 值相对应的动作。
- 在游戏状态下执行选定的动作并收集生成的奖励(r{t})和下一个状态观察(obs_next)。
- 通过 Q 网络传递这些下一个状态观测值,并将这些 Q 值的最大值存储在变量
q_next_state中。 如果折扣因子是 Gamma,则采用如下公式基本事实计算:Y = r{t} + Gamma * q_next_state - X为当前状态的预测收益,Y为实际收益。 计算损失并执行优化步骤。
- 设置
obs = obs_next。 - 步骤 2 到步骤 7重复 n 个情节。
5.3 平衡探索和利用
一开始,我们的代理不知道环境动态。 因此,我们应该让它探索,当它与环境互动时,它应该在探索的同时越来越多地利用其学习。 需要平衡这种探索和利用。 我们可以选择与最大 Q 值相对应的操作(exploitation),也可以选择小概率 epsilon 的随机操作(exploration)。 在该智能体的训练中,我们从 epsilon = 1 开始,即 100% 探索,然后慢慢将其减少到 0.05。
5.4 用重放缓冲区解决灾难性遗忘问题
上述训练过程存在严重问题。 在智能体与环境交互的每个步骤之后,我们都会执行优化步骤。 这可能会导致灾难性遗忘 :
当今的深度学习方法很难在增量在线环境中快速学习,而这对于本书强调的强化学习算法来说是最自然的。 该问题有时被描述为“灾难性干扰”或“相关数据”之一。 当学习新东西时,它往往会取代以前学到的东西,而不是增加它,结果是失去了旧学习的好处。 “重放缓冲区”等技术通常用于保留和重播旧数据,以便其优势不会永久丢失。
正如你现在可能已经猜到的,我们将使用重放缓冲区来解决这个问题。 代理将在重放缓冲区中收集经验,然后从此缓冲区中随机抽取一批经验。 该批次将用于使用小批量梯度下降来训练代理。
5.5 用两个相同的Q网络解决训练不稳定的问题
到目前为止,我们使用同一个 Q 网络用于预测当前状态和下一个状态的 Q 值。 然后使用下一个状态的 Q 值来计算基本事实。 简单来说,
解决方案是建立一个目标网络(target network),它是主网络的精确副本。 该目标网络用于生成目标值或基本事实。 该网络的权重在一定数量的训练步骤中保持固定,之后用主网络的权重进行更新。 通过这种方式,我们的目标奖励的分布对于一些固定的迭代也保持固定,从而提高了训练的稳定性。
另请注意,我们几乎互换使用术语策略网络(policy network)和 Q网络,但这是两种不同类型的网络。 给定一个状态,策略网络生成动作的概率分布,而 Q 网络生成与每个动作相对应的 Q 值。
5.6 DQN 代理实现代码
将我们的代理包装在一个类中似乎很自然。 代理从环境中接收状态观察和奖励。 然后它根据当前的观察对环境采取行动。 深度 Q 网络是我们智能体的大脑。 代理从交互中学习并相应地调整 Q 网络的权重。 让我们快速浏览一下代码:
init 函数构建两个相同的深度神经网络。 在此之前,我们首先设置torch随机生成器的种子。 这样,神经网络的权重就被确定性地初始化了。
如果你的计算机上不支持 Cuda,请从此代码中删除所有出现的 .cuda()。 变量 network_sync_freq 提供在使用主网络的权重更新目标网络之前要采取的训练步数。 变量 network_sync_counter 在 train() 函数中的每个训练步骤后递增,并在达到 network_sync_freq 时重置为 0。 变量 experience_replay 是一个双端队列。 在 train() 函数中,使用主 Q 网络估计当前状态的 Q 值。 使用目标网络计算下一个状态的 Q 值,然后使用该值计算目标回报。
class DQN_Agent:
def __init__(self, seed, layer_sizes, lr, sync_freq, exp_replay_size):
torch.manual_seed(seed)
self.q_net = self.build_nn(layer_sizes)
self.target_net = copy.deepcopy(self.q_net)
self.q_net.cuda()
self.target_net.cuda()
self.loss_fn = torch.nn.MSELoss()
self.optimizer = torch.optim.Adam(self.q_net.parameters(), lr=lr)
self.network_sync_freq = sync_freq
self.network_sync_counter = 0
self.gamma = torch.tensor(0.95).float().cuda()
self.experience_replay = deque(maxlen = exp_replay_size)
return
def build_nn(self, layer_sizes):
assert len(layer_sizes) > 1
layers = []
for index in range(len(layer_sizes)-1):
linear = nn.Linear(layer_sizes[index], layer_sizes[index+1])
act = nn.Tanh() if index < len(layer_sizes)-2 else nn.Identity()
layers += (linear,act)
return nn.Sequential(*layers)
def get_action(self, state, action_space_len, epsilon):
# We do not require gradient at this point, because this function will be used either
# during experience collection or during inference
with torch.no_grad():
Qp = self.q_net(torch.from_numpy(state).float().cuda())
Q,A = torch.max(Qp, axis=0)
A = A if torch.rand(1,).item() > epsilon else torch.randint(0,action_space_len,(1,))
return A
def get_q_next(self, state):
with torch.no_grad():
qp = self.target_net(state)
q,_ = torch.max(qp, axis=1)
return q
def collect_experience(self, experience):
self.experience_replay.append(experience)
return
def sample_from_experience(self, sample_size):
if(len(self.experience_replay) < sample_size):
sample_size = len(self.experience_replay)
sample = random.sample(self.experience_replay, sample_size)
s = torch.tensor([exp[0] for exp in sample]).float()
a = torch.tensor([exp[1] for exp in sample]).float()
rn = torch.tensor([exp[2] for exp in sample]).float()
sn = torch.tensor([exp[3] for exp in sample]).float()
return s, a, rn, sn
def train(self, batch_size ):
s, a, rn, sn = self.sample_from_experience( sample_size = batch_size)
if(self.network_sync_counter == self.network_sync_freq):
self.target_net.load_state_dict(self.q_net.state_dict())
self.network_sync_counter = 0
# predict expected return of current state using main network
qp = self.q_net(s.cuda())
pred_return, _ = torch.max(qp, axis=1)
# get target return using target network
q_next = self.get_q_next(sn.cuda())
target_return = rn.cuda() + self.gamma * q_next
loss = self.loss_fn(pred_return, target_return)
self.optimizer.zero_grad()
loss.backward(retain_graph=True)
self.optimizer.step()
self.network_sync_counter += 1
return loss.item()5.7 驱动实现代码
驱动程序代码非常简单。 我们首先初始化环境和代理。 然后重放缓冲区将被填满,在本例中为 256。 然后我们将其固定为 4 个训练步骤,并且在每个训练步骤期间,从该缓冲区中随机采样一批长度为 16 的样本。 然后,代理在接下来的 128 个时间步长内与环境进行交互,并在缓冲区中收集经验。 请注意,由于它在填满容量后是一个双端队列(我们在主训练循环之前执行此操作),因此每次插入新经验时,前面的一个元素也会被删除。
为了平衡探索和利用,我们使用 epsilon-greedy 策略。 我们首先通过设置 epsilon =1 来促进全面探索,并在每个情节后更新它以缓慢地将其减少到 0.05。
env = gym.make('CartPole-v0')
input_dim = env.observation_space.shape[0]
output_dim = env.action_space.n
exp_replay_size = 256
agent = DQN_Agent(seed = 1423, layer_sizes = [input_dim, 64, output_dim], lr = 1e-3, sync_freq = 5, exp_replay_size = exp_replay_size)
# initiliaze experiance replay
index = 0
for i in range(exp_replay_size):
obs = env.reset()
done = False
while(done != True):
A = agent.get_action(obs, env.action_space.n, epsilon=1)
obs_next, reward, done, _ = env.step(A.item())
agent.collect_experience([obs, A.item(), reward, obs_next])
obs = obs_next
index += 1
if( index > exp_replay_size ):
break
# Main training loop
losses_list, reward_list, episode_len_list, epsilon_list = [], [], [], []
index = 128
episodes = 10000
epsilon = 1
for i in tqdm(range(episodes)):
obs, done, losses, ep_len, rew = env.reset(), False, 0, 0, 0
while(done != True):
ep_len += 1
A = agent.get_action(obs, env.action_space.n, epsilon)
obs_next, reward, done, _ = env.step(A.item())
agent.collect_experience([obs, A.item(), reward, obs_next])
obs = obs_next
rew += reward
index += 1
if(index > 128):
index = 0
for j in range(4):
loss = agent.train(batch_size=16)
losses += loss
if epsilon > 0.05 :
epsilon -= (1 / 5000)
losses_list.append(losses/ep_len), reward_list.append(rew), episode_len_list.append(ep_len), epsilon_list.append(epsilon)
5.8 一些图表
下图显示了随着我们在训练中取得进展,奖励如何变化。 大约6500个情节后,绘制每个情节的最高得分:

奖励随情节的变化

x 轴:epoch,y 轴:epsilon
5.9 动画时间!!!
下面的动画展示了我们的代理如何优雅地平衡车杆。 北极看上去几乎是静止的。 我每次尝试它都获得最高分。 尽管对大量情节取平均值是一个更好的主意:

上面的动画是由以下代码片段生成的:
env = gym.make('CartPole-v0')
env = gym.wrappers.Monitor(env, "record_dir")
for i in tqdm(range(2)):
obs, done, rew = env.reset(), False, 0
while (done != True) :
A = agent.get_action(obs, env.action_space.n, epsilon = 0)
obs, reward, done, info = env.step(A.item())
rew += reward
sleep(0.01)
env.render()
print("episode : {}, reward : {}".format(i,rew)) 6、已知的局限性
- 用了太多黑技巧:你可以轻松观察到,获得正确的超参数值需要进行大量实验。 甚至神经网络的初始化方式也会对网络训练产生重大影响。
- 不支持在线训练:由于需要目标网络来稳定训练并使用重放缓冲区来解决灾难性遗忘,因此我们的代理无法以在线方式进行训练。f
- 泛化情况不好:我无法在其他环境中获得相同的代理工作。 原因是我们的代理是一个非常基本的代理。 然而,原始 DQN 论文中描述的代理能够在不同的环境中进行泛化。
7、结束语
深度学习和强化学习的结合非常令人着迷。 构建这个 DQN 并让它发挥作用是一次奇妙的经历。 但这种方法仍然存在很多限制。 DQN 于 2013 年推出。我们在本博客中实现的 DQN 是所提出的 DQN 的简单得多的版本。
2013年之后,深度强化学习取得了很大的进展。 此链接提供了丰富的资源汇编。 通过这个博客,我只是试图触及表面。 距离这里还有很长的路要走。 所以我们会继续探索!!!
原文地址:https://blog.csdn.net/shebao3333/article/details/134747916
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_25588.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!