本文介绍: 1、Master(standalone):资源管理的主节点(进程)2、Cluster Manager:在集群上获取资源的外部服务(例如:standalone,Mesos,Yarn)3、Worker Node(standalone):资源管理的从节点(进程)或者说管理本机资源的进程4、Driver Program:用于连接工作进程(Worker)的程序。
一、术语与宽窄依赖
1、术语解释
1、Master(standalone):资源管理的主节点(进程)
2、Cluster Manager:在集群上获取资源的外部服务(例如:standalone,Mesos,Yarn)
3、Worker Node(standalone):资源管理的从节点(进程)或者说管理本机资源的进程
4、Driver Program:用于连接工作进程(Worker)的程序
5、Executor:是一个worker进程所管理的节点上为某Application启动的一个进程,该进程负责运行任务,并且负责将数据存在内存或者磁盘上。每个应用都有各自独立的executors
2、窄依赖和宽依赖
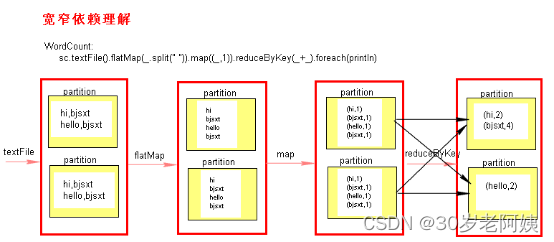
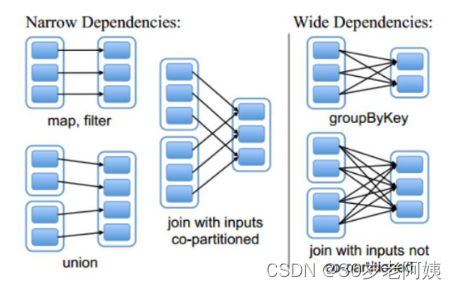
二、Stage的计算模式
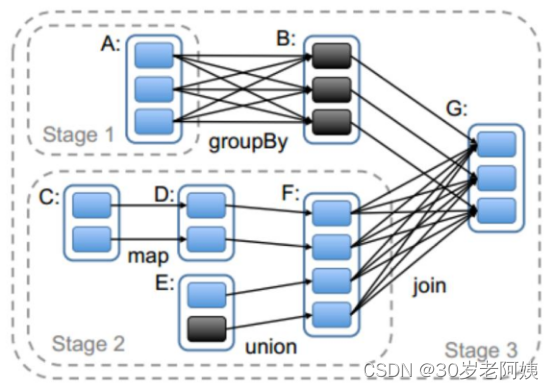
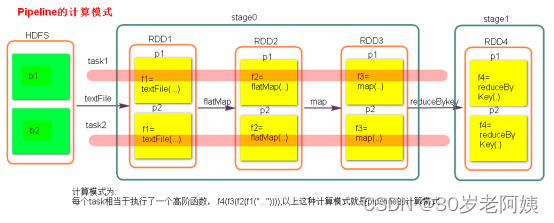
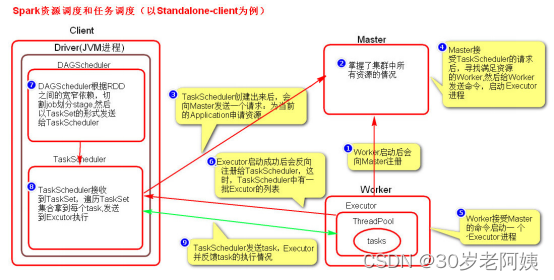
三、Spark资源调度和任务调度
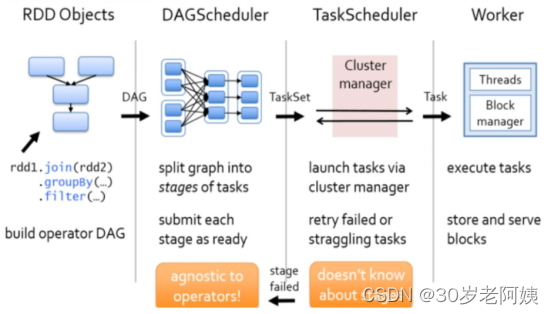
2、图解Spark资源调度和任务调度的流程
3、粗粒度资源申请和细粒度资源申请
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。


![[Linux 进程控制(二)] 写时拷贝 – 进程终止](https://img-blog.csdnimg.cn/direct/3dbeb6ece1be48c5ab271f177538e475.gif#pic_center)



