本文介绍: 缓存击穿,缓存穿透 随机时间, 缓存NULL(NULL过期时间不用太长), 布隆过滤器。2. 多级缓存(加一层JVM缓存),encache设置过期时间, mq广播更新本地缓存。3. 热点缓存系统, 客户端只查JVM缓存, 服务端更新JVM缓存。1. RedLoack解决主从切换锁失效问题,以及遗留缺陷。4. 缓存击穿,缓存穿透,缓存雪崩问题以及解决方案。冷门数据突变成热点数据问题 分布式锁 双重检查。2. 优化减库存场景 > 分段锁降低锁粒度。冷热数据分离 > 查数据时,锁延期。
如果用普通的分布式锁实现, 最后抢到的人,要等前面99个人抢完
优化方案:可用分段锁, 降低锁的粒度, 比如1-10库存用锁product:101_1,11-20库存用锁product:101_2等, 提高并发性能
代码:==
场景2: 商品的增删改查,如何用高并发缓存架构实现?针对各种并发场景,如何优化
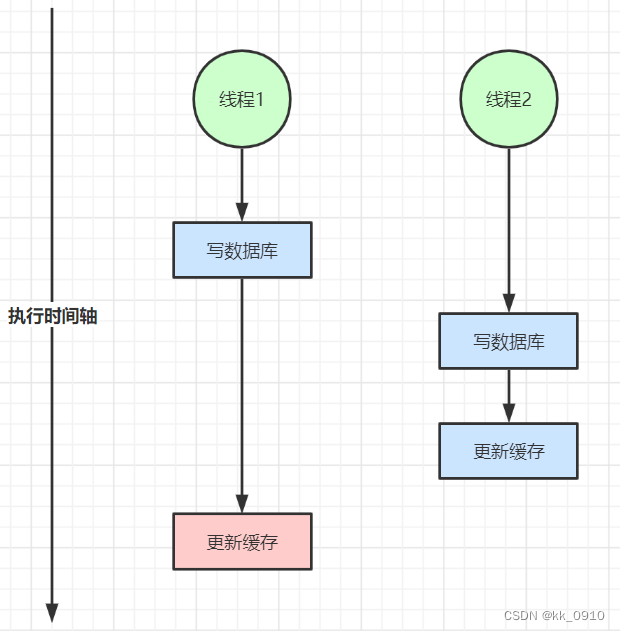
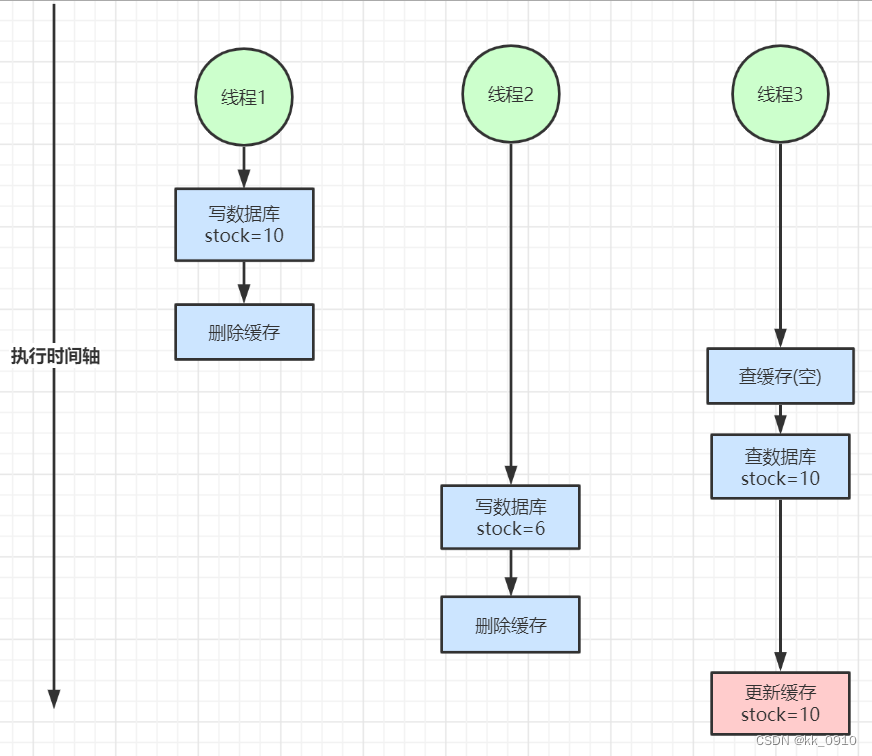
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。