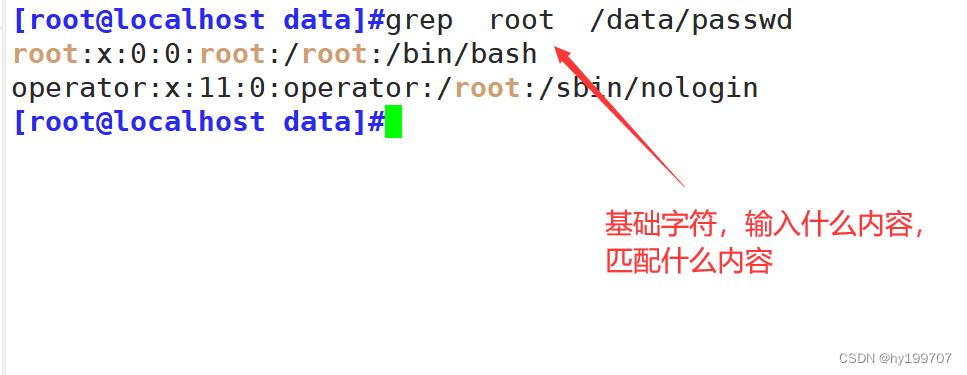
背景
爬取某天气网站数据,使用 Selenium 能够得到渲染数据后的页面源代码。特定日期的真实数据肯定只有1份,展示在页面表格中,但是源代码中提供了3个都有数据的 Table,而其中2个Table 的数据是通过 math.random 生成后填充,然后通过 css 样式设置了隐藏。
为了拿到真实数据,要么直接提取包含真实数据的 Table,要么剔除2个伪数据 Table,然后才能进一步提取 tr 以及 td 标签内的文本。鉴于使用了Scrapy框架,函数之间传递的是 HtmlResponse, 所以我们采用剔除2个伪数据 Table的方式,保留网页源代码其余部分,而没有提取真实数据再封装或者改用String 传递。
不管哪种方式,关键是要找出真数据 Table 和 伪数据 Table 之间的差异。
经过反复对比,我们发现用伪造数据填充的2个 Table, 都有在 class 中设置了 position : absolute 属性,所以可以用正则表达式来匹配出全部Table,然后直接将这2个 Table,替换为空。
实现
2步走方案
其实最开始是打算一步到位的,但是实在搞不定1步到位的正则表达式,所以决定还是先用笨办法,拿到结果再看怎么优化。所以用了2步,
- 第1步,正则匹配得到3个 Table,这里的正则表达式有2种写法
- 第2步,在3个 Table 基础上,进行 position 匹配,然后 replace 为空。这里的匹配就很简单了,只匹配是否包含 position 字符串即可
# 先匹配table 标签
# regex_table = r"<table([sS]*?)</table>"
# regex_table = r"<table[sS]*?</table>"
# 中间有括号是设置分组,但是这里只需要确认有没有匹配,不需要分组
# ?= 在开头是包含,在结尾是不包含
# ?<= 在开头是不包含,在结尾是包含
regex_table = r"(?=<table)[sS]*?(?<=</table>)"
tables = re.findall(regex_table, page_source)
print('{} tables been matched.'.format(len(tables)))
# 样式中没有设置 position 的Table,就是包含真实数据的,保留
# 另外2个 替换为空
regex_table_class = r"position"
for table in tables:
if re.findall(regex_table_class, table):
page_source = page_source.replace(table, '')1步到位方案
在2步走方案成功拿到数据后,还是忍不住对效率提升,方案简化的渴望,于是又开始折腾,不断查找资料,甚至还无助地到知乎 发帖 求助 [笑哭] —— 是的,网上能找到很多理论,但是没有现成可借鉴方案。
在花了近一天时间付出数百次失败尝试理解高深理论最终头昏脑胀后,我终于还是 —— 没有放弃。借助无意间发掘出的新工具 Regex Debugger,对正则匹配的逻辑有了进一步认识,终于在工具加持以及半小时休息神智稍微清醒后,写出了这个匹配开头、结尾、中间 —— 简直前不见古人,后不见来者的正则表达式
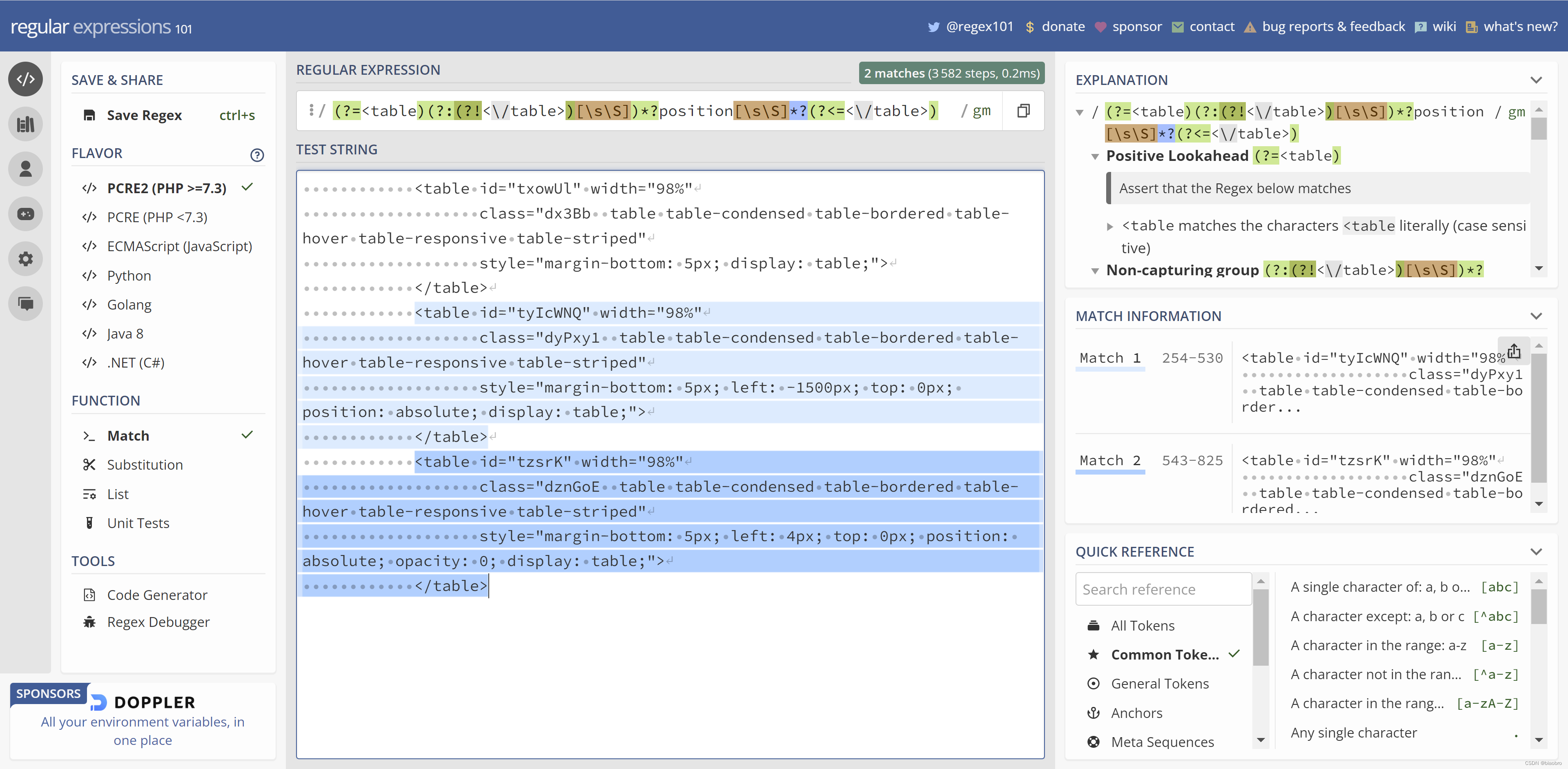
我在 知乎 上自问自答,对这个正则表达式做了解释。这里再赘述一遍,也能让自己再加深一遍印象。
开头和结尾的圆括号,其实和2步走方案一致,匹配以 <table 开头和以 </table> 结尾。
中间部分,因为要匹配包含 position 的字符串,所以最简单的写法就是 [sS]*?position[sS]*? —— [sS]*? 用来做非贪婪匹配任意字符,因为html 代码中是有换行的,所以不能用 . 来匹配 。
但是这么写是拿不到正确结果的,如下图。第1个实际没有包含 position 的 table 标签也被包含了进来。所以需要在 以 <table 开头到遇到 position 之间,再加1个条件,把</table> 过滤掉

于是把<table 后面,position 前面的部分改为 (?:(?!</table>)[sS])*? —— 其中
(?!</table>) 表示不包含字符串 </table>,
(?!</table>)[sS] 表示不包含字符串 </table>的任意字符串
(?:(?!</table>)[sS]) 表示匹配但不提取

因为<table 的闭合尖括号 > 也能把前面的这个 table 分割出来,所以正则可以简化成: (?=<table)(?:(?!>)[sS])*?position[sS]*?(?<=</table>) —— 就是我们在代码里使用的形式。是的,1步到位,就是这么清爽。
# 一步到位的正则表达式
re_one_step = r"(?=<table)(?:(?!>)[sS])*?position[sS]*?(?<=</table>)"
res_one_step = re.sub(re_one_step,'', page_source)我把替换前的原始 html 代码(下图左)和替换后的代码(下图右)保存到了本地,可以对比看到,处理后的代码只保留了1个 Table,另外2个被成功移除。
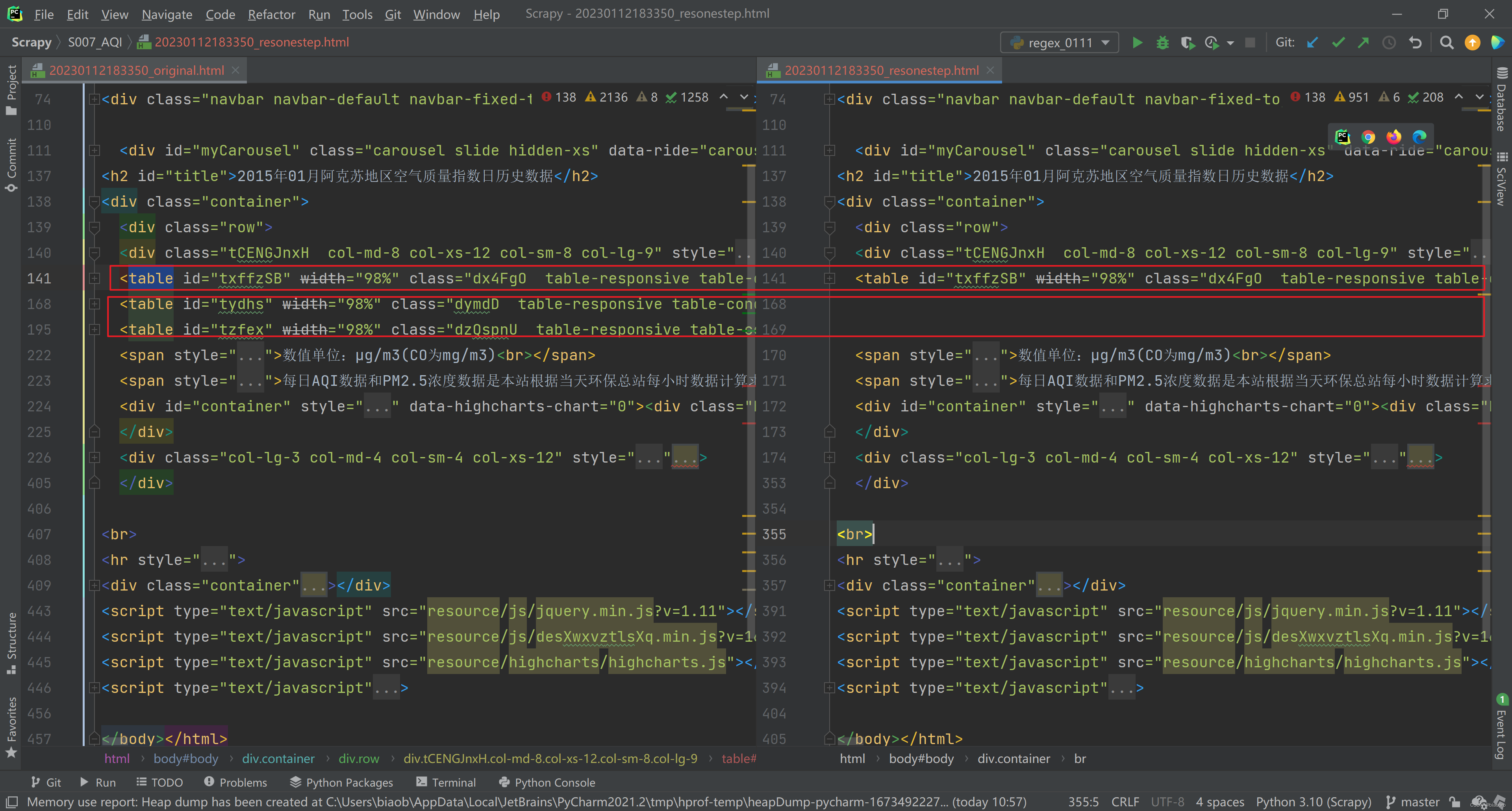
方案对比
从代码简洁度看,毫无疑问,1步到位方案的代码最简洁,只有2行,而2步走方案用了6行代码。
那性能上呢?直观上,1步到位方案是直接全文匹配,2步走方案是不断缩小匹配范围 —— 感觉上2步走似乎应该快。
但做了2次程序运行时间的粗略计算,实际还是1步到位方案更快。
第1次:
solution 2 exhaust 0.004988193511962891s
solution 1 exhaust 0.0019943714141845703s
第2次:
solution 2 exhaust 0.007024049758911133s
solution 1 exhaust 0.001960277557373047s
鉴于我们纯粹出于好奇求知学习的目的,所以性能就先步考虑了。无论如何,我们成功实现了对伪数据的剔除,拿到了包含真实数据的 Table。
这里留个引子,因为拿到的只是包含真实数据的 Table,并不代表里面全是真实数据。后面会再写一篇文章来分析如何从包含真实数据的 Table 里进一步剔除伪数据。不要问我怎么会有这种网站…… 我只想给网站的前端程序员点赞。
原文地址:https://blog.csdn.net/biaobro/article/details/128664316
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_25860.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!