一、过期策略
一、前言
Redis 所有的数据结构都可以设置过期时间,时间一到,就会自动删除。可以想象里面有一个专门删除过期数据的线程,数据已过期就立马删除。这个时候可以思考一下,会不会因为同一时间太多的 key 过期,以至于线程忙不过来。同时因为 Redis 是单线程的,删除的时间也会占用线程的处理时间,如果删除的太过于繁忙,会不会导致线上读写指令出现卡顿。
二、立即删除
它会在设置键的过期时间的同时,创建一个定时器, 当键到了过期时间,定时器会立即对键进行删除。 这个策略能够保证过期键的尽快删除,快速释放内存空间。
1、优点:
立即删除能保证内存中数据的最大新鲜度,因为它保证过期键值会在过期后马上被删除,其所占用的内存也会随之释放。对内存来说是非常友好的。
2、缺点:
立即删除对cpu是最不友好的。因为删除操作会占用cpu的时间,如果刚好碰上了cpu很忙的时候,比如正在做交集或排序等计算的时候,就会给cpu造成额外的压力。
3、总结:立即删除对cpu不友好,但是对内存友好,实际性质就是用处理器性能换区内存空间。
三、惰性删除
1、优点 :
2、缺点:
如果一个键已经过期,而这个键又仍然保留在redis中,那么只要这个过期键不被删除,它所占用的内存就不会释放。因此对于内存是很不友好的。
在使用惰性删除策略时,如果数据库中有非常多的过期键,而这些过期键又恰好没有被访问到的话,那么它们也许永远也不会被删除(除非用户手动执行FLUSHDB),我们甚至可以将这种情况看作是一种内存泄漏–无用的垃圾数据占用了大量的内存,而服务器却不会自己去释放它们,这对于运行状态非常依赖于内存的Redis服务器来说,肯定不是一个好消息
四、定期删除
定期删除策略是前两种策略的折中:
1、过期key的集合
redis 会将每个设置了过期时间的 key 放入到一个独立的字典中,以后会定时遍历这个 字典来删除到期的 key。除了定时遍历之外,它还会使用惰性策略来删除过期的 key。定期删除是集中处理,惰性删除是零散处理。
2、定时扫描策略
Redis 默认会每秒进行十次过期扫描,过期扫描不会遍历过期字典中所有的 key,而是 采用了一种简单的贪心策略。
而这就会出现一种需要特别注意的情况:
设想一个大型的 Redis 实例中所有的 key 在同一时间过期了。Redis 会持续扫描过期字典 (循环多次),直到过期字典中过期的 key 变得稀 疏,才会停止 (循环次数明显下降)。这就会导致线上读写请求出现明显的卡顿现象。导致这 种卡顿的另外一种原因是内存管理器需要频繁回收内存页,这也会产生一定的 CPU 消耗。
即使算法还增加了扫描时间的上限,也是会出现卡顿现象。假如有 101 个客户端同时将请求发过来了,然后前 100 个请求的执行时间都是 25ms,那么第 101 个指令需要等待多久才能执行?2500ms,这个就是客户端的卡顿时间,是由服务器不间断的小卡顿积少成多导致的(假如每次都达到了扫描上线25ms)。
3、定期删除注意事项:
- 如果删除操作执行次数过多、执行时间太长,就会导致和定时删除同样的问题:占用大量cpu资源去进行删除操作
- 如果删除操作次数太少、执行时间短,就会导致和惰性删除同样的问题:内存资源被持续占用,得不到释放。
所以定时删除最关键的就在于执行时长和频率的设置,可在redis的配置文件中配置

对于hz参数,官方不建议超过100,否则会把cpu造成比较大的压力
二、缓存淘汰策略
1、当 Redis 内存超出物理内存限制时,内存的数据会开始和磁盘产生频繁的交换,交换会让 Redis 的性能急剧下降,对于访问量比较频繁的 Redis 来说,这样龟速的存取效率 基本上等于不可用。
2、一般生产上的redis内存都会设置一个内存上限(maxmemory),如果有许多没有加过期时间的数据,长期下来就会把redis内存打满,出现OOM异常。
3、定期删除是使用简单的贪心算法,会出现一些没有被抽查到的数据,而惰性删除也会出现一些长时间没有访问得数据,这就会导致大量过期的key堆积在内存中,导致redis内存空间紧张或者很快耗尽。所以必须要有一个兜底方案。这个方案就是缓存淘汰策略。
一、八种缓存淘汰策略
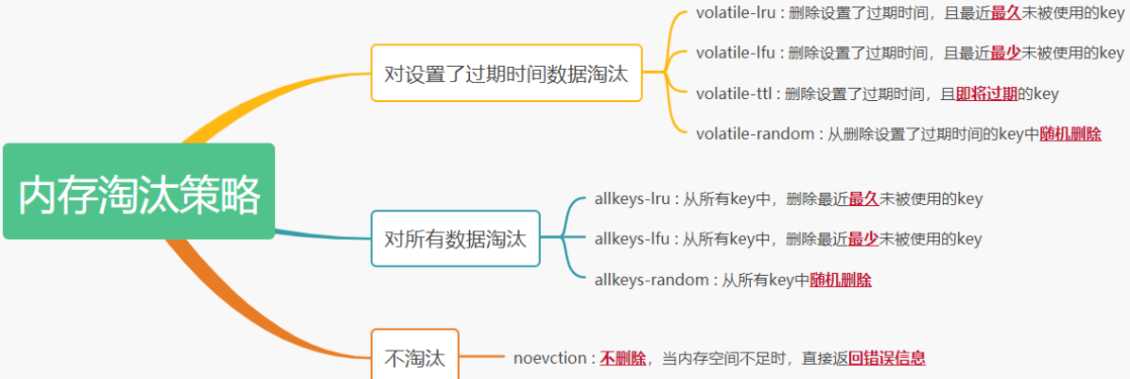
1、noeviction:不会继续服务写请求 (DEL 请求可以继续服务),读请求可以继续进行。这样 可以保证不会丢失数据,但是会让线上的业务不能持续进行。这是默认的淘汰策略。
2、volatile-lru:尝试淘汰设置了过期时间的 key,最少使用的 key 优先被淘汰。没有设置过 期时间的 key: 不会被淘汰,这样可以保证需要持久化的数据不会突然丢失。
3、allkeys-lru: 区别于 volatile-lru,这个策略要淘汰的 key 对象是全体的 key 集合,而不 只是过期的 key 集合。这意味着没有设置过期时间的 key 也会被淘汰。
4、volatile-ttl: 跟上面一样,除了淘汰的策略不是 LRU,而是 key 的剩余寿命 ttl 的值,ttl 越小越优先被淘汰。
5、volatile-random:对所有设置了过期时间的key随机淘汰。
7、volatile-lfu:对设置了过期时间的key使用lfu算法进行删除
8、allkeys-lfu:对所有key使用lfu算法进行删除
总结:volatile-xxx: 策略只会针对带过期时间的 key 进行淘汰,allkeys-xxx 策略会对所有的 key 进行淘汰。如果你只是拿 Redis 做缓存,那应该使用 allkeys-xxx,客户端写缓存时 不必携带过期时间。如果你还想同时使用 Redis 的持久化功能,那就使用 volatile-xxx 策略,这样可以保留没有设置过期时间的 key,它们是永久的 key 不会被 LRU 算法淘 汰。
二、LRU和LFU
1、区别:
LRU:最近最少使用页面置换算法,淘汰最长时间未被使用的页面,看页面最后一次被使用到发生调度的时间长短,首先淘汰最长时间未被使用的页面。
LFU:最近最不常用页面置换算法,淘汰一定时期内被访问次数最少的页,看一定时间段内页面被使用的频率,淘汰一定时期内被访问次数最少的页
举个栗子
某次时期Time为10分钟,如果每分钟进行一次调页,主存块为3,若所需页面走向为2 1 2 1 2 3 4
若按LRU算法,应换页面1(1页面最久未被使用),但按LFU算法应换页面3(十分钟内,页面3只使用了一次)
2、手写LRU算法
/** * @Description : * @Author : huangcong * @Date : 2023/6/28 9:48 **/ public class LinkedHashMapLru<K, V> extends LinkedHashMap<K, V> { private Integer initialCapacity; public LinkedHashMapLru(Integer initialCapacity) { super(initialCapacity, 0.75F, Boolean.FALSE); this.initialCapacity = initialCapacity; } @Override protected boolean removeEldestEntry(Map.Entry<K, V> eldest) { return super.size() > initialCapacity; } public Object getValue(Object key) { Object v = super.get(key); if (Objects.isNull(v)) { return -1; } return v; } public static void main(String[] args) { LinkedHashMapLru<Object, Object> hashMapLru = new LinkedHashMapLru<>(3); hashMapLru.put(1, "a"); hashMapLru.put(2, "b"); hashMapLru.put(3, "c"); System.out.println(hashMapLru.entrySet()); // key存在变更其数据 hashMapLru.put(3, "l"); System.out.println(hashMapLru.entrySet()); // 当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值 hashMapLru.put(4, "d"); System.out.println(hashMapLru.entrySet()); hashMapLru.put(5, "f"); System.out.println(hashMapLru.entrySet()); // 获取数据 get(key) - 如果关键字 (key) 存在于缓存中,则获取关键字的值(总是正数),否则返回 -1 Object value =hashMapLru.getValue(1); System.out.println(value); } }
/** * @Description : 构造一个node节点,承载数据 * @Author : hc * @Date : 2023/6/28 12:14 **/ public class Node<K, V> { K key; V value; Node<K, V> pre; Node<K, V> next; public Node() { } public Node(K key, V value) { this.key = key; this.value = value; this.pre = this.next = null; } public void setKey(K key) { this.key = key; } public void setValue(V value) { this.value = value; } }
/** * @Description :双向链表 * @Author : hc * @Date : 2023/6/28 12:23 **/ public class LruCache <K,V>{ Node<K,V> head; Node<K,V> tail; public LruCache() { head = new Node<>(); tail = new Node<>(); head.next = tail; tail.pre = head; } // 头插法,靠近头部的是最新的数据 public void add(Node<K,V> node){ node.next = head.next; node.pre = head; head.next.pre = node; head.next = node; } public void delete(Node<K,V> node){ node.next.pre =node.pre; node.pre.next = node.next; node.next = null; node.pre = null; } public Node getNode(){ return tail.pre; } // 打印链表 public String getCache(){ StringBuffer stringBuffer = new StringBuffer(); Node<K, V> node = head.next; while (node != tail){ stringBuffer.append(node.key+"="+node.value + "rn"); node = node.next; } return stringBuffer.toString(); } }
/** * @Description : * hash表:通过hash函数计算出hash值,然后(hash值 % 数组大小)得到对应数组中的位置 * @Author : hc * @Date : 2023/6/28 16:23 **/ public class Lru { private Integer cacheSize; // 规定容器大小 private Map<Integer,Node<Integer,Integer>> map; // hash表,方便查找 private LruCache<Integer,Integer> doubleLinkedMap;// 双向链表,方便插入以及删除 public Lru(Integer cacheSize) { this.cacheSize = cacheSize; map = new HashMap<>(); doubleLinkedMap = new LruCache<>(); } public int get(Integer key){ if (!map.containsKey(key)){ return -1; } Node<Integer, Integer> node = map.get(key); doubleLinkedMap.delete(node); doubleLinkedMap.add(node); return node.value; } public Integer put(Integer key,Integer value){ // 如果哈希表中有,替换节点的value值 if (map.containsKey(key)){ Node<Integer, Integer> node = map.get(key); node.setValue(value); doubleLinkedMap.delete(node); doubleLinkedMap.add(node); return key; } Node<Integer, Integer> node = new Node<>(key, value); // 如果hash没有,且容器中数据已经达到了规定大小,删除最后一个数据,在头部添加一个最新数据 if (map.size() >= cacheSize){ Node lastNode = doubleLinkedMap.getNode(); doubleLinkedMap.delete(lastNode); doubleLinkedMap.add(node); map.remove(key); map.put(key,node); return key; } // 如果hash没有,且容器中数据未达到了规定大小,直接在头部添加一个最新数据 doubleLinkedMap.add(node); map.put(key,node); return key; } // 删除节点 public Integer delete(Integer key){ if (!map.containsKey(key)){ return -1; } Node<Integer, Integer> node = map.get(key); doubleLinkedMap.delete(node); map.remove(key); return key; } public static void main(String[] args) { Lru lru = new Lru(3); lru.put(1,1); lru.put(2,2); lru.put(3,3); System.out.println(lru.doubleLinkedMap.getCache()); lru.put(2,4); System.out.println(lru.doubleLinkedMap.getCache()); lru.put(4,4); System.out.println(lru.doubleLinkedMap.getCache()); int i = lru.get(3); System.out.println(i); System.out.println(lru.doubleLinkedMap.getCache()); } }
3=3
2=2
1=12=4
3=3
1=14=4
2=4
3=33
3=3
4=4
2=4
原文地址:https://blog.csdn.net/weixin_42972832/article/details/131410757
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_25866.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!






