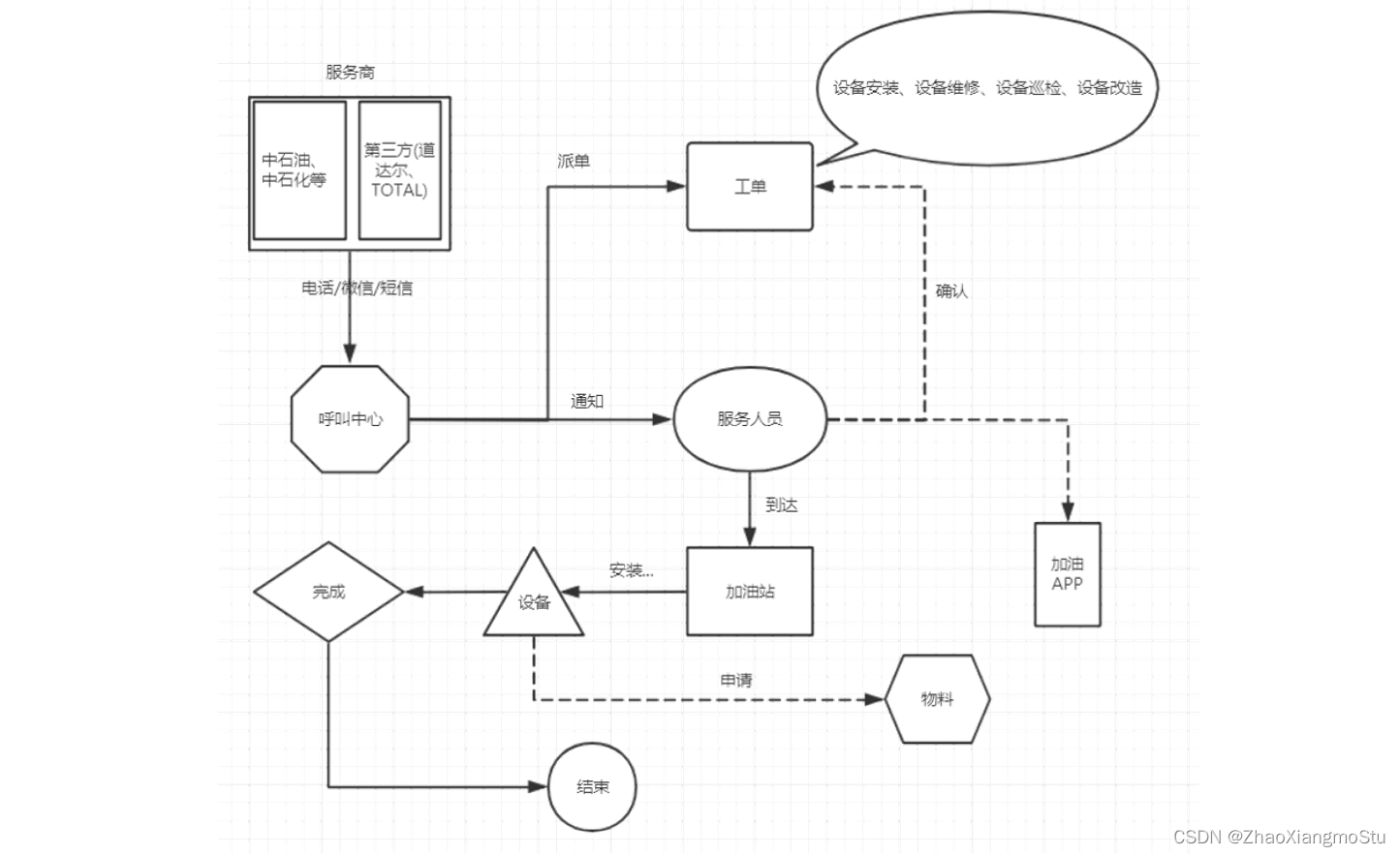
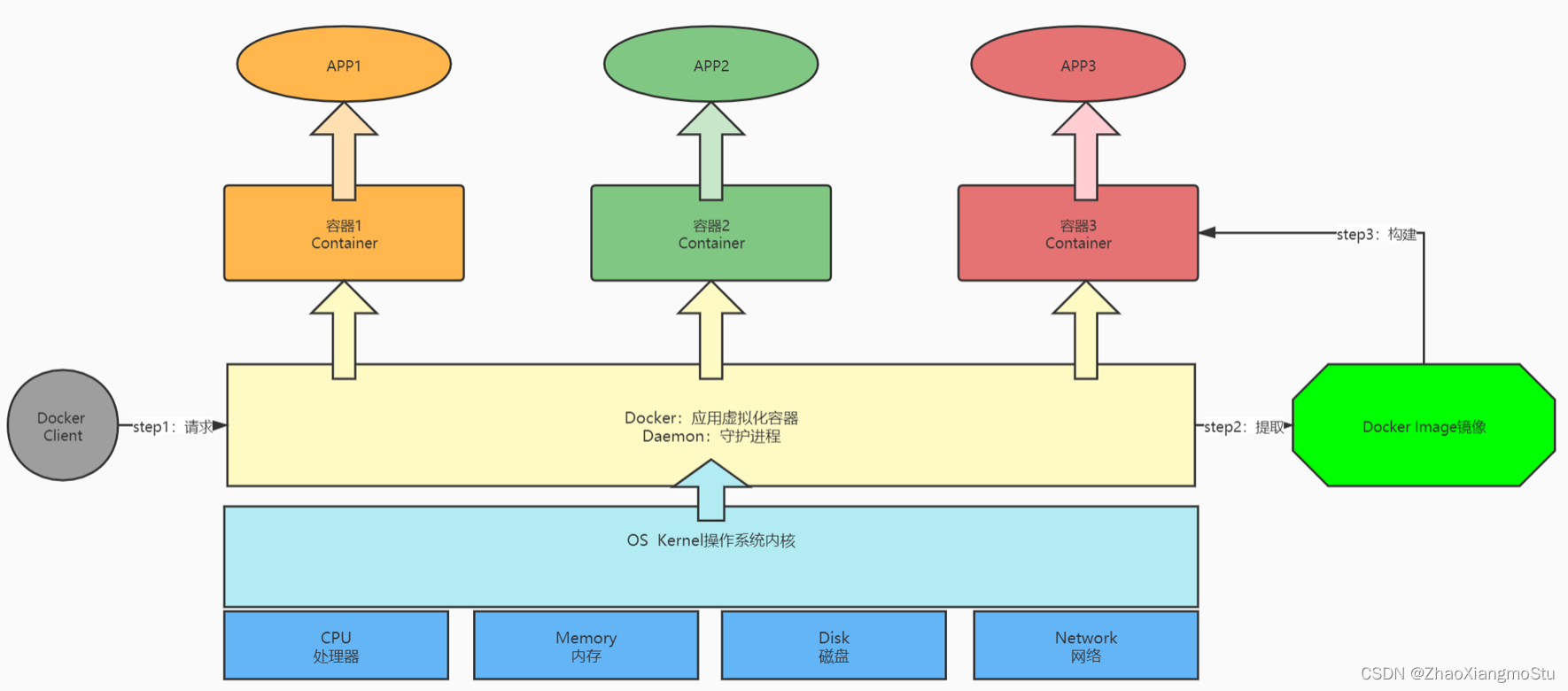
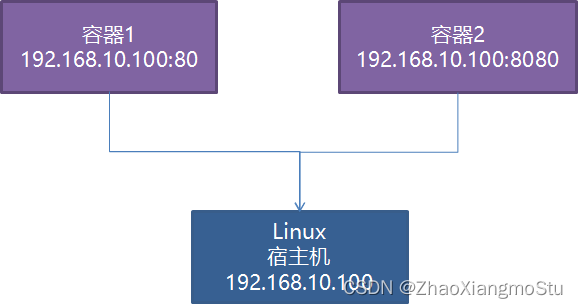
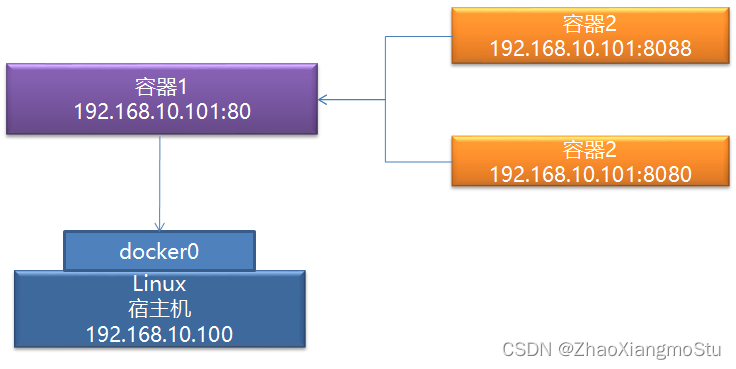
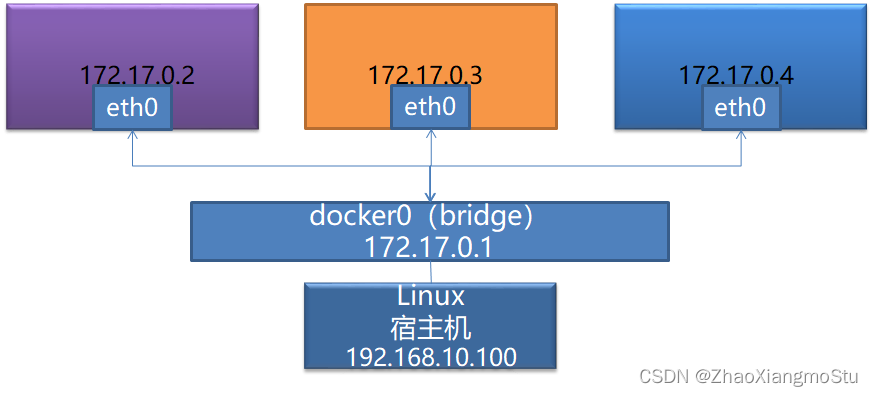
本文介绍: Docker是一个开源的应用容器引擎,使用GO语言开发,基于Linux内核的cgroup,namespace,Union FS等技术,对应用程序进行封装隔离,并且独立于宿主机与其他进程,这种运行时封装的状态称为容器。通过对应用组件的封装,分发,部署,运行等生命周期的管理,达到应用组件级别的一次封装,多次分发,到处部署。step6:如果为维修或者改造服务,需要向服务站点申请物料,物料到达,实施结束,则服务完成。container模式:第一个容器构建一个独立的虚拟网络,其他的容器与第一个容器共享网络。
1. 项目目标
一站制造
企业中项目开发的落地:代码开发
代码开发:SQL【DSL + SQL】
SparkCore
SparkSQL
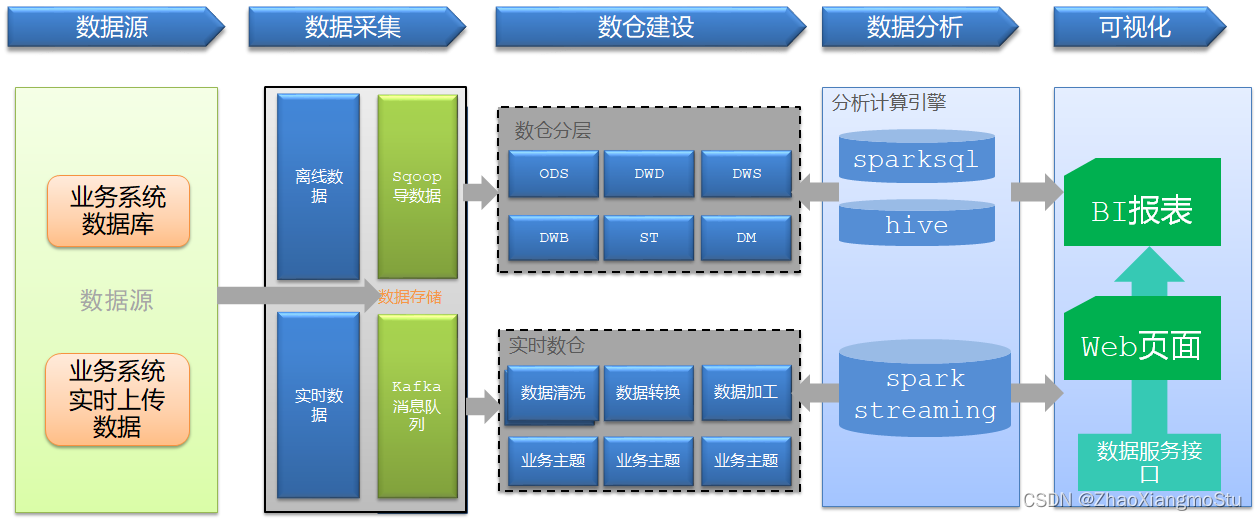
数仓的一些实际应用:分层体系、建模实现
2. 内容目标
项目业务介绍:背景、需求
项目技术架构:选型、架构
项目环境测试
实施
项目行业:工业大数据
项目名称:加油站服务商数据运营管理平台
中石化,中石油,中海油、壳牌,道达尔……
整体需求
基于加油站的设备安装、维修、巡检、改造等数据进行统计分析
支撑加油站站点的设备维护需求以及售后服务的呼叫中心数据分析
提高服务商服务加油站的服务质量
保障零部件的仓储物流及供应链的需求
实现服务商的所有成本运营核算
具体需求
运营分析:呼叫中心服务单数、设备工单数、参与服务工程师个数、零部件消耗与供应指标等
设备分析:设备油量监控、设备运行状态监控、安装个数、巡检次数、维修次数、改造次数
呼叫中心:呼叫次数、工单总数、派单总数、完工总数、核单次数
员工分析:人员个数、接单次数、评价次数、出差次数
报销统计分析、仓库物料管理分析、用户分析
报表

项目具体需求
提高服务质量,做合理的成本预算
需求一:对所有工单进行统计分析
安装工单、维修工单、巡检工单、改造工单、回访分析
需求二:付费分析、报销分析
安装人工费用、安装维修材料费用、差旅交通费用

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。