前言
Redis 是我们目前大规模使用的缓存中间件,由于它强大高效而又便捷的功能,得到了广泛的使用。单节点的Redis已经就达到了很高的性能,为了提高可用性我们可以使用Redis集群。本文参考了Rdis的官方文档和使用Redis官方提供的Redis Cluster工具搭建Rdis集群。
21
Redis集群的概念
介绍
Redis 集群是一个可以在多个 Redis 节点之间进行数据共享的设施(installation)。
Redis 集群不支持那些需要同时处理多个键的 Redis 命令, 因为执行这些命令需要在多个 Redis 节点之间移动数据, 并且在高负载的情况下, 这些命令将降低 Redis 集群的性能, 并导致不可预测的错误。
Redis 集群通过分区(partition)来提供一定程度的可用性(availability): 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
Redis 集群提供了以下两个好处:
数据分片
Redis 集群使用数据分片(sharding)而非一致性哈希(consistency hashing)来实现: 一个 Redis 集群包含 16384 个哈希槽(hash slot), 数据库中的每个键都属于这 16384 个哈希槽的其中一个, 集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽, 其中 CRC16(key) 语句用于计算键 key 的 CRC16 校验和 。
集群中的每个节点负责处理一部分哈希槽。 举个例子, 一个集群可以有三个哈希槽, 其中:
这种将哈希槽分布到不同节点的做法使得用户可以很容易地向集群中添加或者删除节点。 比如说:
我现在想设置一个key,叫my_name:
按照Redis Cluster的哈希槽算法,CRC16(‘my_name’)%16384 = 2412 那么这个key就被分配到了节点A上
同样的,当我连接(A,B,C)的任意一个节点想获取my_name这个key,都会转到节点A上
再比如
如果用户将新节点 D 添加到集群中, 那么集群只需要将节点 A 、B 、 C 中的某些槽移动到节点 D 就可以了。
增加一个D节点的结果可能如下:
与此类似, 如果用户要从集群中移除节点 A , 那么集群只需要将节点 A 中的所有哈希槽移动到节点 B 和节点 C , 然后再移除空白(不包含任何哈希槽)的节点 A 就可以了。
因为将一个哈希槽从一个节点移动到另一个节点不会造成节点阻塞, 所以无论是添加新节点还是移除已存在节点, 又或者改变某个节点包含的哈希槽数量, 都不会造成集群下线。
所以,Redis Cluster的模型大概是这样的形状
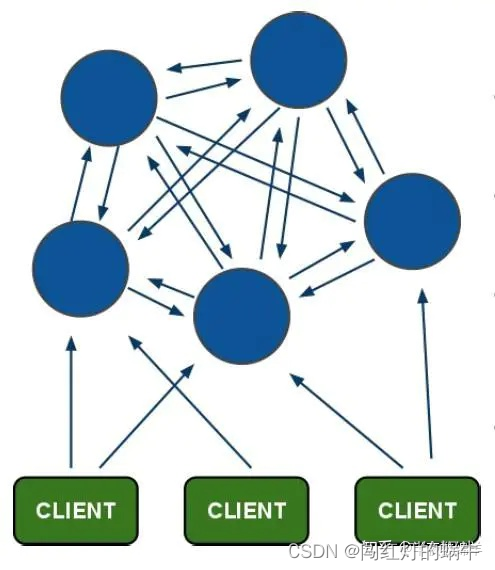
主从复制模型
为了使得集群在一部分节点下线或者无法与集群的大多数(majority)节点进行通讯的情况下, 仍然可以正常运作, Redis 集群对节点使用了主从复制功能: 集群中的每个节点都有 1 个至 N 个复制品(replica), 其中一个复制品为主节点(master), 而其余的 N-1 个复制品为从节点(slave)。
在之前列举的节点 A 、B 、C 的例子中, 如果节点 B 下线了, 那么集群将无法正常运行, 因为集群找不到节点来处理 5501 号至 11000号的哈希槽。
另一方面, 假如在创建集群的时候(或者至少在节点 B 下线之前), 我们为主节点 B 添加了从节点 B1 , 那么当主节点 B 下线的时候, 集群就会将 B1 设置为新的主节点, 并让它代替下线的主节点 B , 继续处理 5501 号至 11000 号的哈希槽, 这样集群就不会因为主节点 B 的下线而无法正常运作了。
不过如果节点 B 和 B1 都下线的话, Redis 集群还是会停止运作。
Redis一致性保证
Redis 并不能保证数据的强一致性. 这意味这在实际中集群在特定的条件下可能会丢失写操作:第一个原因是因为集群是用了异步复制. 写操作过程:
主节点对命令的复制工作发生在返回命令回复之后, 因为如果每次处理命令请求都需要等待复制操作完成的话, 那么主节点处理命令请求的速度将极大地降低 —— 我们必须在性能和一致性之间做出权衡。 注意:Redis 集群可能会在将来提供同步写的方法。 Redis 集群另外一种可能会丢失命令的情况是集群出现了网络分区, 并且一个客户端与至少包括一个主节点在内的少数实例被孤立。
举个例子 假设集群包含 A 、 B 、 C 、 A1 、 B1 、 C1 六个节点, 其中 A 、B 、C 为主节点, A1 、B1 、C1 为A,B,C的从节点, 还有一个客户端 Z1 假设集群中发生网络分区,那么集群可能会分为两方,大部分的一方包含节点 A 、C 、A1 、B1 和 C1 ,小部分的一方则包含节点 B 和客户端 Z1 .
Z1仍然能够向主节点B中写入, 如果网络分区发生时间较短,那么集群将会继续正常运作,如果分区的时间足够让大部分的一方将B1选举为新的master,那么Z1写入B中得数据便丢失了.
注意, 在网络分裂出现期间, 客户端 Z1 可以向主节点 B 发送写命令的最大时间是有限制的, 这一时间限制称为节点超时时间(node timeout), 是 Redis 集群的一个重要的配置选项
搭建Redis集群
要让集群正常工作至少需要3个主节点,在这里我们要创建6个redis节点,其中三个为主节点,三个为从节点,对应的redis节点的ip和端口对应关系如下(为了简单演示都在同一台机器上面)
127.0.0.1:7000
127.0.0.1:7001
127.0.0.1:7002
127.0.0.1:7003
127.0.0.1:7004
127.0.0.1:7005
安装和启动Redis
下载安装包
mkdir /usr/local/redis
cd /usr/local/redis
wget http://download.redis.io/releases/redis-6.0.8.tar.gz
tar zxvf redis-6.0.8.tar.gz
cd redis-6.0.8.tar.gz
mv redis-6.0.8/* .
make && make PREFIX=/usr/local/redis install
yum install gcc -y
yum install tcl -y
这里如果报sh:./mkreleasehdr.sh权限不够错误
chmod -R 755 /usr/local/redis/src/mkreleasehdr.sh
执行make命令报错struct redisServer’没有名为‘sentinel_mode’的成员
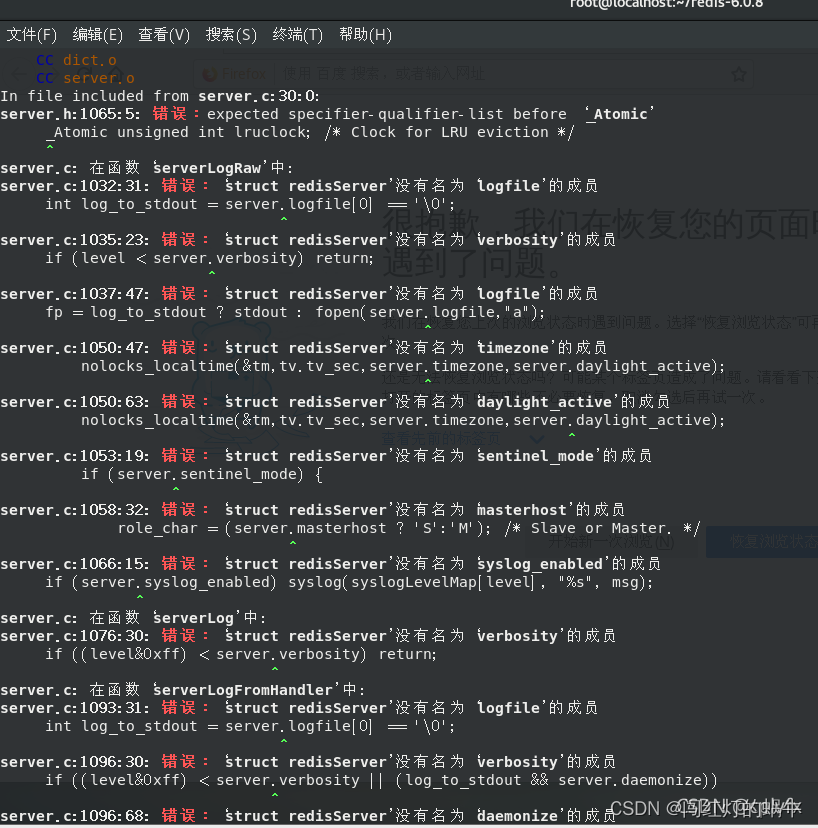
解决方案:
gcc -v
如果当前的gcc版本不是5.3以上,执行下面命令更新gcc版本
yum -y install centos-release-scl
yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
scl enable devtoolset-9 bash
再进入到redis的解压目录下的src目录,执行
make && make PREFIX=/usr/local/redis install即可编译成功
创建目录
cd /usr/local/redis
mkdir redis_cluster
cd redis_cluster
mkdir 7000 7001 7002 7003 7004 7005
cp redis-6.0.8/redis.conf /usr/local/redis/cluster/6000
bind 0.0.0.0
# 端口号
port 7000
# 后台启动
daemonize yes
# 开启集群
cluster-enabled yes
#集群节点配置文件
cluster-config-file nodes-7000.conf
# 集群连接超时时间
cluster-node-timeout 5000
# 进程pid的文件位置
pidfile /var/run/redis-7000.pid
# 开启aof
appendonly yes
# aof文件路径
appendfilename "appendonly-7000.aof"
# rdb文件路径
dbfilename dump-7000.rdb
创建启动脚本
在/usr/local/redis目录下创建一个redis_start.sh
[root@localhost redis]# touch redis_start.sh
[root@localhost redis]# vim redis_start.sh
#!/bin/bash
bin/redis-server redis_cluster/7000/redis.conf
bin/redis-server redis_cluster/7001/redis.conf
bin/redis-server redis_cluster/7002/redis.conf
bin/redis-server redis_cluster/7003/redis.conf
bin/redis-server redis_cluster/7004/redis.conf
bin/redis-server redis_cluster/7005/redis.conf
[root@localhost redis]# chmod -R 755 redis_start.sh
开启集群
这里我们只是开启了6个redis进程而已,它们都还只是独立的状态,还么有组成集群这里我们使用官方提供的工具redis-trib,不过这个工具是用ruby写的,要先安装ruby的环境
redis-cli --cluster create --cluster-replicas 1 0.0.0.0:7000 0.0.0.0:7001 0.0.0.0:7002 0.0.0.0:7003 0.0.0.0:7004 0.0.0.0:7005
原文地址:https://blog.csdn.net/m0_46168595/article/details/127420758
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_26006.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!





