本文介绍: 理解“映射”映射是一种键(索引)和值(数据)的对应字典类型是“映射”的体现键值对:键是数据索引的扩展字典是键值对的集合,键值对之间无序采用大括号{}和dict()创建,键值对用冒号: 表示{:,:}可以通过键拿到值我们在之前的的集合中说声明一个空集合要使用set(),而不是直接用{}这是因为,如果使用{}默认为集合。
字典类型及操作
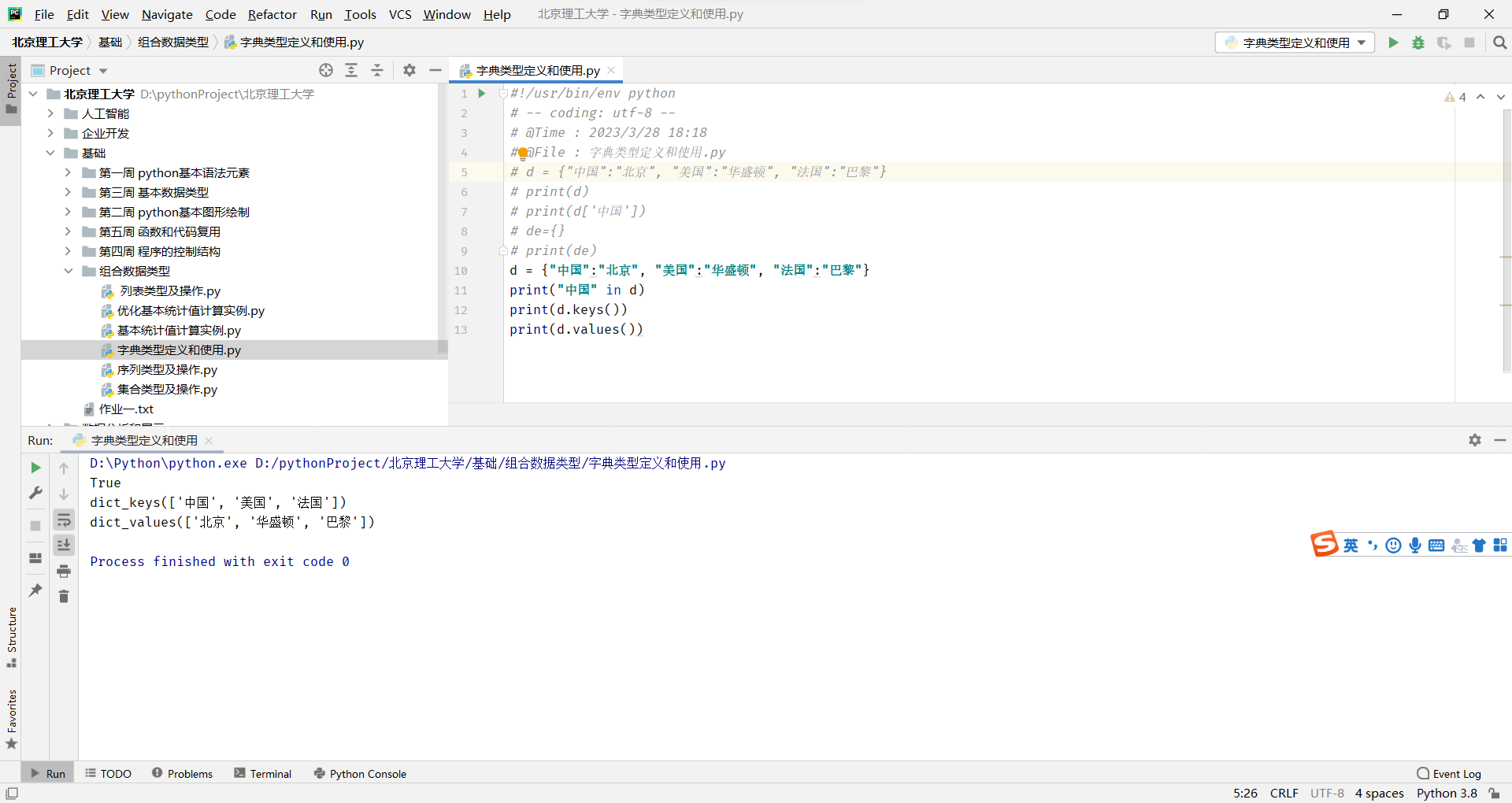
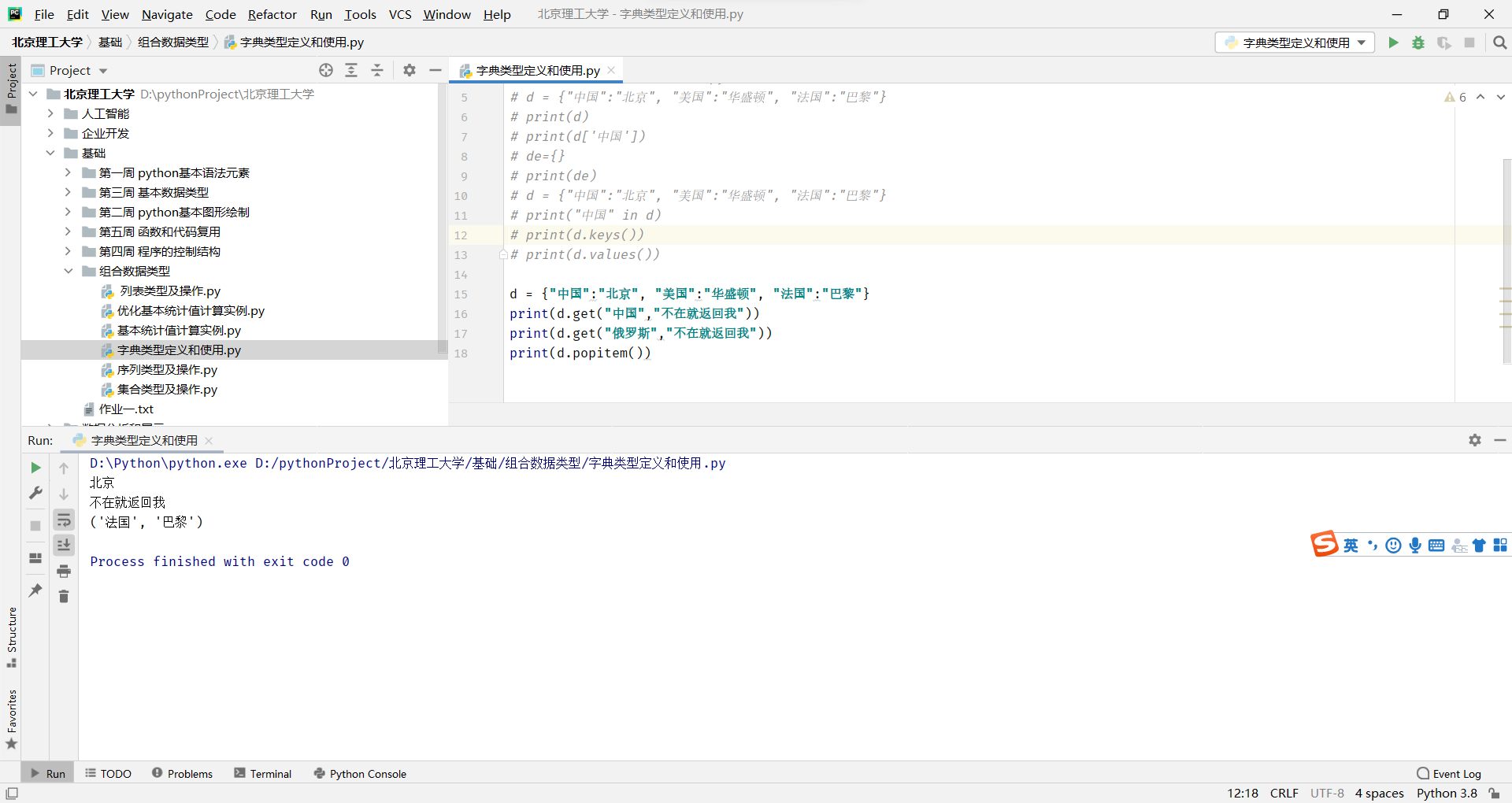
字典的定义

字典的处理函数及方法


Jieba库的使用

jieba分词的原理


文本词频统计—英文

文本词频统计–中文


声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。