本文介绍: 例如,每次从数据库获取 id 时,获取一个号段,如[1,2999],这个范围表示3000 个 ID,业务应用在请求获取 id 时,只需要在本地从 1 开始自增并返回(注意线程安全问题,使用原子类来做自增操作),而不用每次去请求数据库,一直到本地自增到 2999 时,再去数据库重新获取新的号段,后续流程循环往复。分布式ID生成系统需要具有较高的可用性,因为业务数据的唯一标识都由该系统分配,若系统不可用,将直接影响用户、订单这些强依赖于ID生成系统的模块。如果id乱序,将不利于数据库的写入和排序操作。
为什么需要分布式唯一id?
在开发项目时,我们需要给每一个”角色“都打上唯一的标签,比如用户、订单、消息等都需要唯一的标识,以此来区分不同的用户、订单及消息。单体项目中使用数据库的自增主键作为唯一标识可能就绰绰有余了,但分布式系统下可以使用这种方案吗?显然不行,此时就需要用到分布式id了。
分布式唯一id需要具有哪些特性?
(1)全局唯一:最基本的要求,必须保证全局不会出现重复ID。
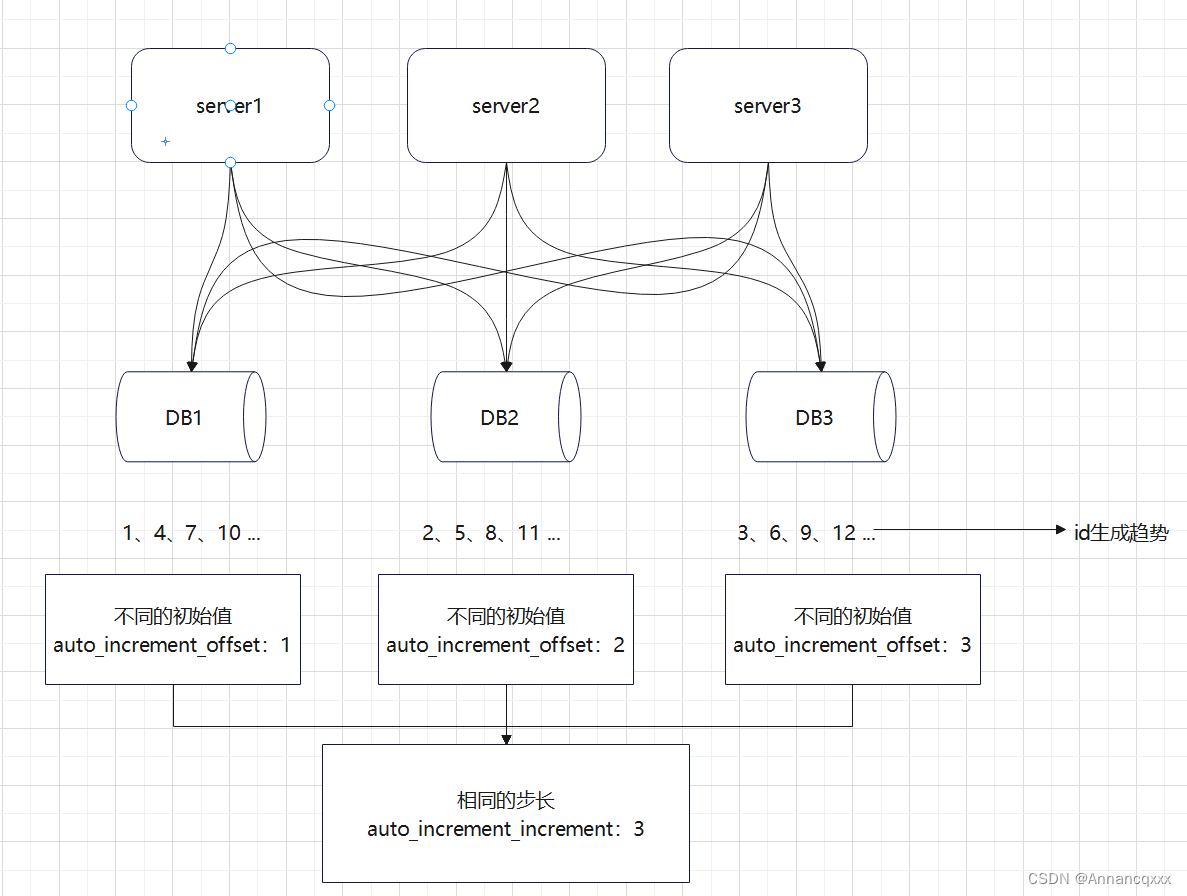
(2)有序:id作为唯一标识肯定是字段之一,要随业务数据写入数据库的;如果id乱序,将不利于数据库的写入和排序操作。
(3)高可用:分布式ID生成系统需要具有较高的可用性,因为业务数据的唯一标识都由该系统分配,若系统不可用,将直接影响用户、订单这些强依赖于ID生成系统的模块。
分布式唯一ID的生成方案有哪些?

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。