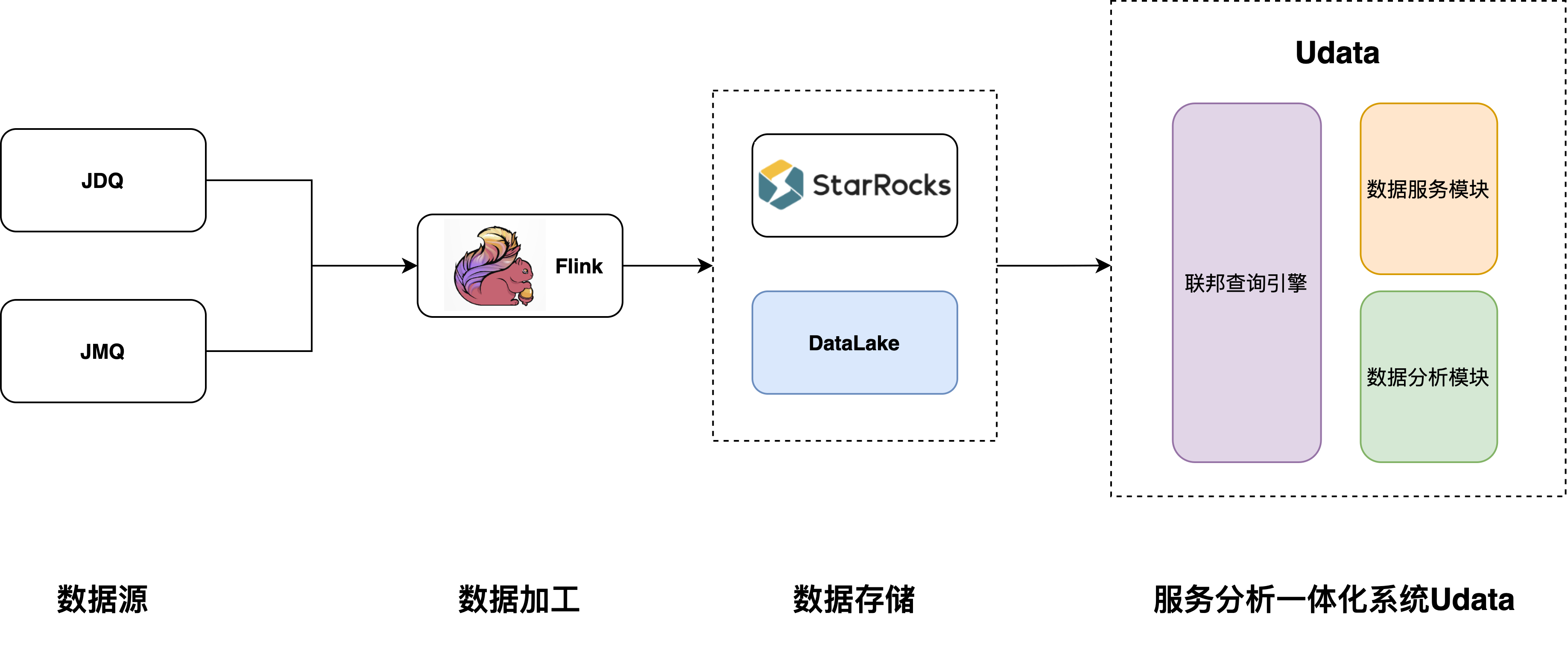
本文介绍: 联邦查询可以很好的解决这个问题,使用统一的查询引擎屏蔽了不同olap的引擎的专有DSL,大大提升了开发效率和学习成本,同时可以用ONE SQL方式整合来自不同数据源的指标形成新的指标,从而提高了指标的复用性。改造后,我们在数据存储层引入了StarRocks,StarRocks提供了极速的单表和多表查询能力,同时以StarRocks为基础我们打造了统一查询引擎,统一查询引擎根据京东的业务特点增加数据源和聚合下推等功能,UData在统一查询引擎的基础上统一了数据分析和数据服务功能。
1 背景
数据服务与数据分析场景是数据团队在数据应用上两个大的方向,行业内大家有可能会遇到下面的问题:
1.1 数据服务
1.2 数据分析
除了以上问题,数据服务和数据分析系统也是无法统一,分析产生的数据结果往往是离线的,需要额外开发数据服务,无法快速转化为线上服务赋能外部系统,使得分析和服务之间难以快速形成闭环。而且在以往数据加工过程中存储往往只考虑了当时的需求,当后续需求场景扩展,最初的存储引擎可能不适用,导致一份数据针对不同的场景要存储到不同的存储引擎,带来数据一致性隐患和成本浪费问题。
2 基于StarRocks 的数据服务分析一体化实践
基于以上这些业务痛点京东物流运营数据产品团队研发了服务分析一体化系统——UData(Universal Data),UData系统是以StarRocks引擎为技术基础的实现的。UData把数据指标生成的过程抽象出来,用配置的方式低代码化生成数据服务,大大降低的开发复杂性和难度,让非研发同学也可以根据自己的需求配置和发布自己数据服务,指标的开发时间由之前的一两天缩短为30分钟,大大解放了研发力。平台化的指标管理体系和数据地图的功能,让用户更加直观和方便地查找与维护指标,同时也让指标复用变成可能。
在数据分析方面,我们用基于StarRocks的联邦查询方案打造了UData统一查询引擎,解决了查询引擎不统一和数据孤岛问题,同时StarRocks提供了强悍的数据查询性能,无论是大宽表还是多表关联查询性能都十分出色。StarRocks提供数据实时摄入的能力和多种实时数据模型,可以很好的支持数据实时更新场景。UData系统把分析和服务结合在一起,让分析和服务不再是分割的两个过程,用户分析出有价值的数据后可以立即生成对应的数据服务,让服务分析快速闭环。
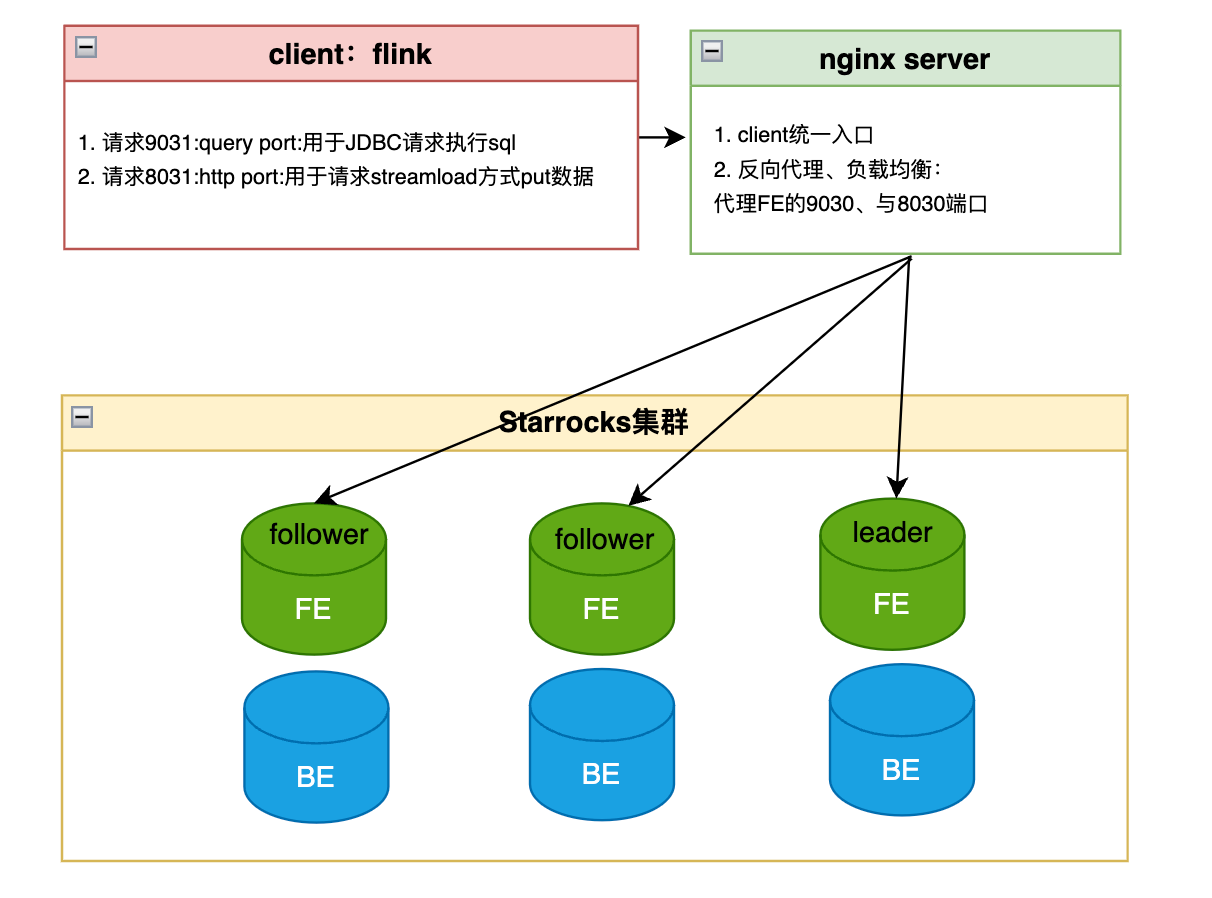
改造前的架构:


2.1 StarRocks极速的查询性能的原因
2.2 对StarRocks联邦查询的改造

2.3 实时场景的实践
3 后续方向
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。