本文部分内容参考文章:https://juejin.cn/post/7251391372394053691,https://zhuanlan.zhihu.com/p/563661713,感谢博主的辛苦工作,本文尽量去繁就简去理解DDPM的原理
论文地址: http://arxiv.org/abs/2006.11239
代码地址1: https://github.com/hojonathanho/diffusion (论文对应代码 tensorflow)
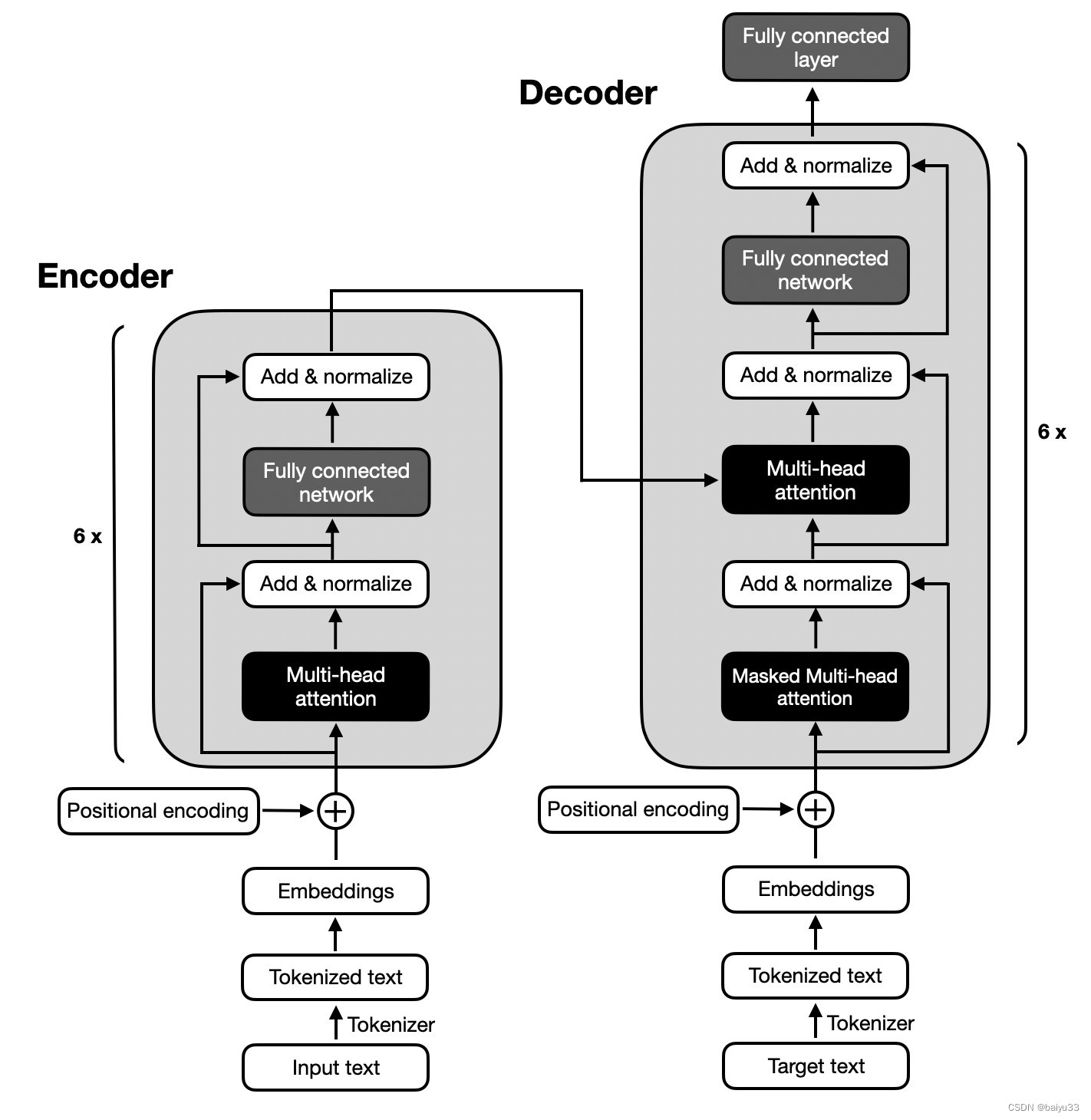
DDPM基本原理
DDPM(Denoising Diffusion Probalistic Models)的目标是学习训练数据的分布,产出尽可能符合训练数据分布的真实图片。训练过程分为两步:
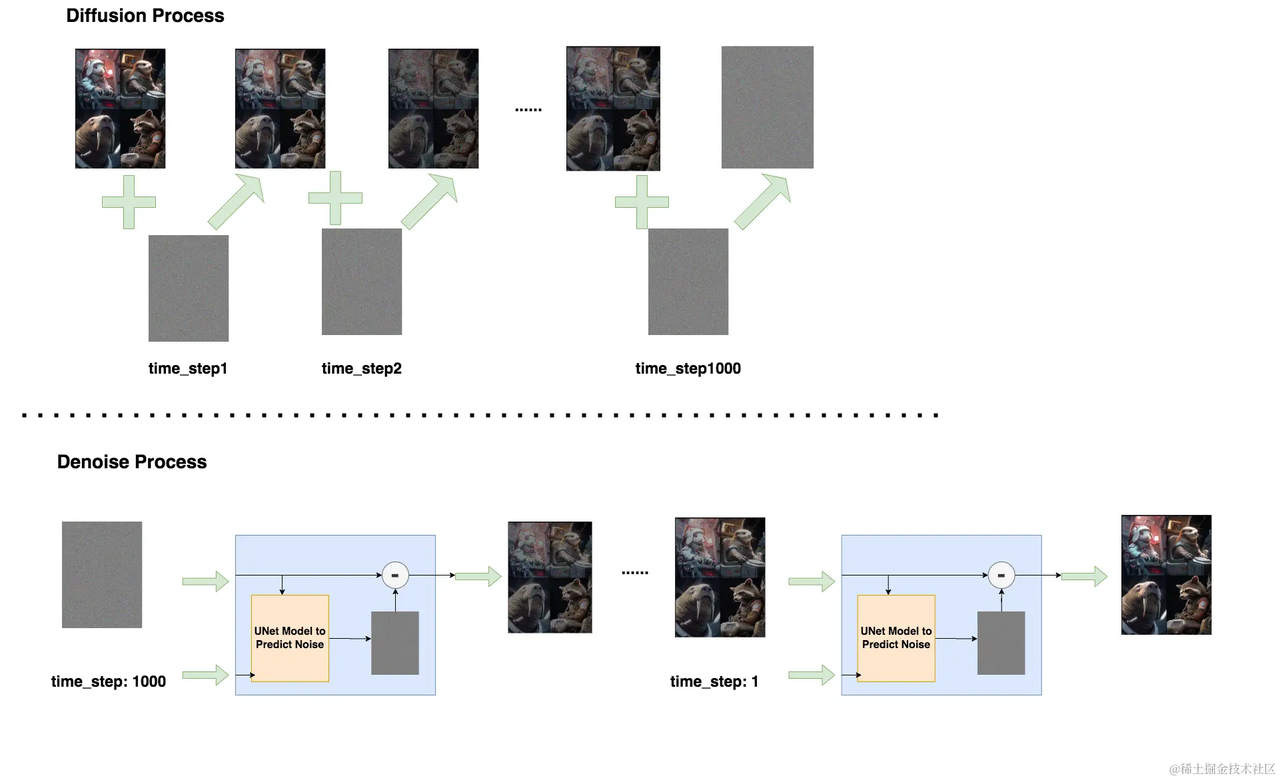
如下图,正向扩散的过程进行了1000步的加噪,每一步time_step都往图片上加入一个高斯分布的噪声,直到图片变为一个纯高斯分布的噪声。完成Dif fusion Process过程。
如下图,逆向去噪的过程从第T个timestep开始,模型的输入为加噪后的图像xt与当前timestep。输入timestep的目的是由于模型每一步去噪用的都是同一个模型,所以需要告诉模型进行的是哪一步去噪。因此,timestep类似于transformer中的位置编码,将一个常数转换为一个向量再和输入的图片进行相加。模型中蕴含一个噪声预测器(UNet),它会根据当前的输入预测出噪声,然后,将当前图片减去预测出来的噪声,就可以得到去噪后的图片。重复这个过程,直到还原出原始图片x0为止。
DDPM中的Unet模块
Unet模块介绍
在Encoder部分中,UNet模型会逐步压缩图片的大小;在Decoder部分中,则会逐步还原图片的大小。同时在Encoder和Deocder间,还会使用“残差连接”,确保Decoder部分在推理和还原图片信息时,不会丢失掉之前步骤的信息。Unet模块的输入为加噪的图像和当前的TimeStep, 示意图如下:
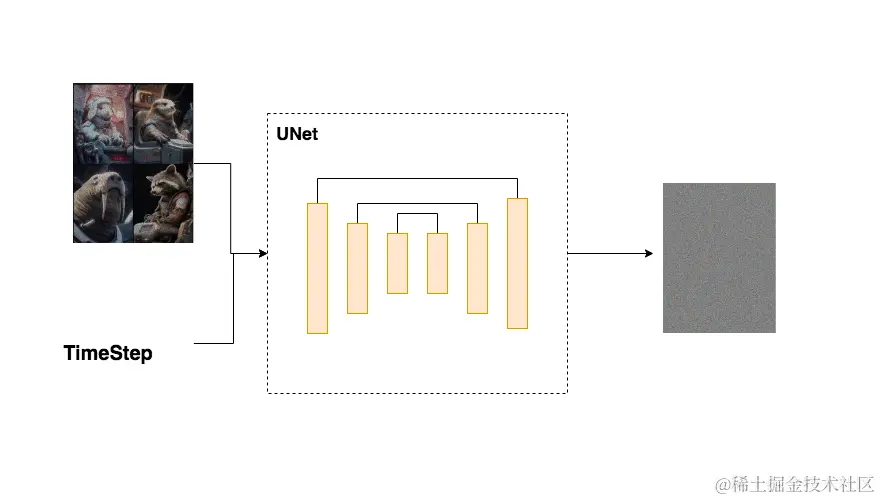
Unet流程示意图
如下图,左半边为UNet的Encoder部分,右半边为UNet的Deocder部分,最下面为MiddleBlock。输入为一张32*32*3大小的图片,在Encoder部分的第二行,输入是一个16*16*64的图片,它是由上一行最右侧32*32*64的图片压缩而来(DownSample)。对于这张16*16*64大小的图片,在引入time_embedding后,让它们一起过一层DownBlock,得到大小为16*16*128的图片。再引入time_embedding,再过一次DownBlock,得到大小同样为16*16*128的图片。对该图片做DowSample,就可以得到第三层的输入,也就是大小为8*8*128的图片。由此不难知道,同层间只做channel上的变化,不同层间做图片的压缩处理。
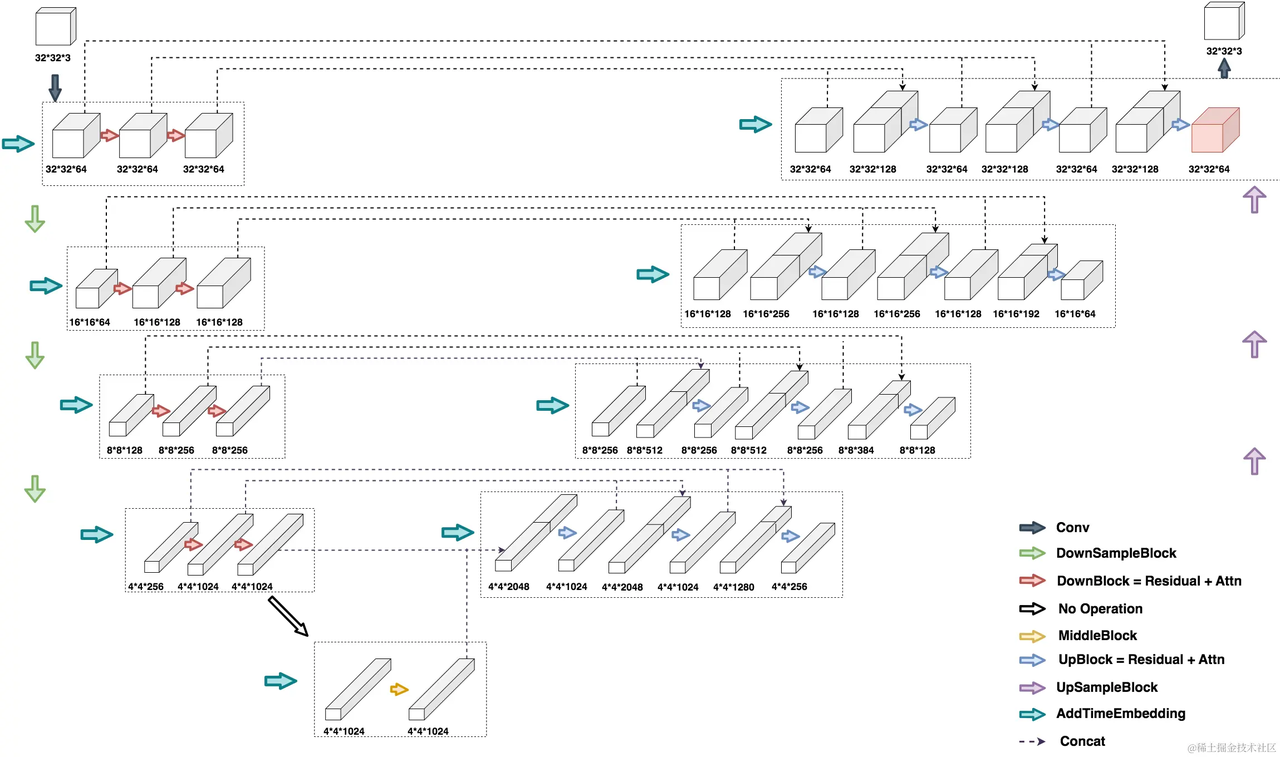
DownBlock和UpBlock
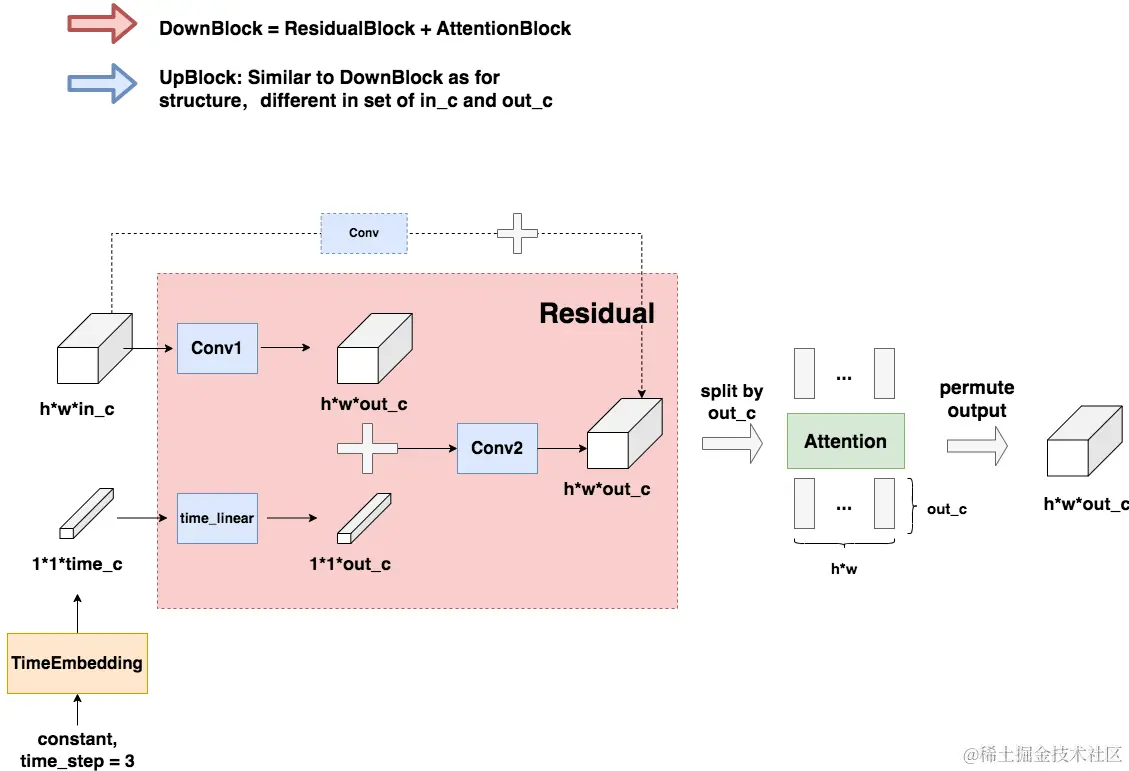
这个模块非常重要,已知Unet模块的输入为图像和timestep,那么就需要将timestep转换为一个向量并和图像相加,才外还需要用Attention机制。那么这两个trick是怎么发挥作用的呢?如下图所示,TimeEmbedding层采用和Transformer一致的三角函数位置编码,将常数转变为向量。Attention层则是沿着channel维度将图片拆分为token,做完attention后再重新组装成图片(注意Attention层不是必须的,是可选的)。虚线部分即为“残差连接”(Residual Connection) ,而残差连接之上引入的虚线框Conv的意思是,如果in_c = out_c,则对in_c做一次卷积,使得其通道数等于out_c后,再相加;否则将直接相加。
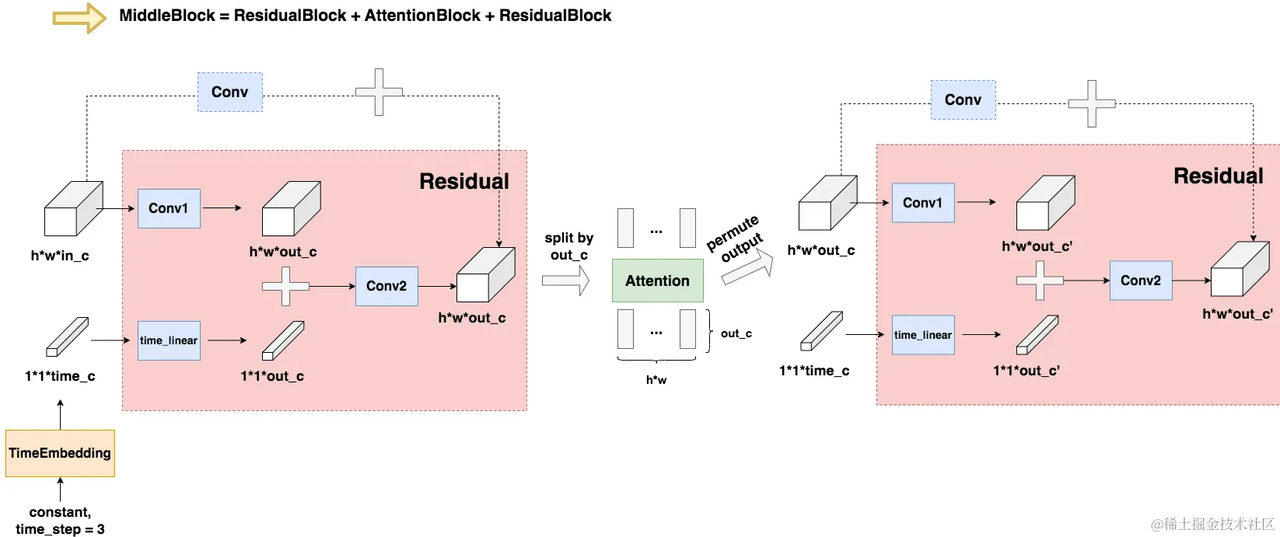
MiddleBlock
和DownBlock与UpBlock过程类似,接在下采样和上采样的中间。
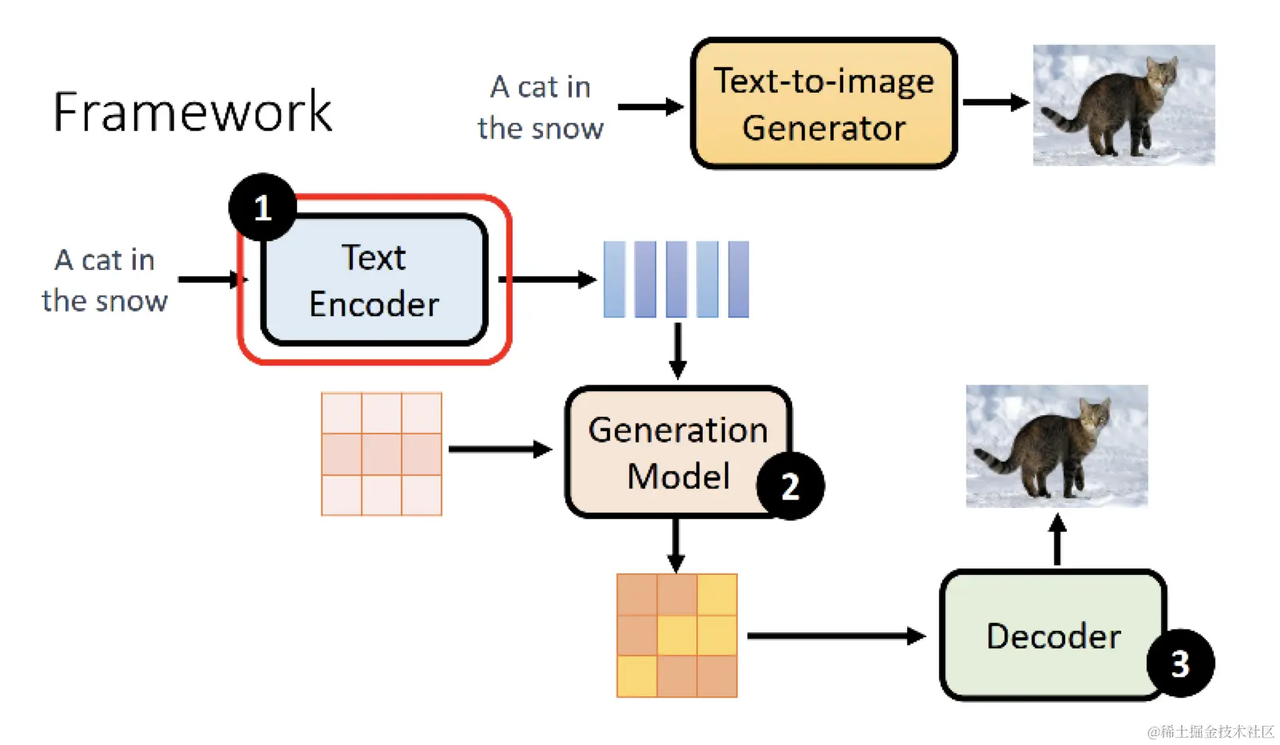
文生图模型的一般公式
训练完成的DDPM模型可以产生逼真的图片,然后就可以进一步用文字信息去引导它产生符合我们意图的模型了。通常来说,文生图模型遵循以下公式
-
Text Encoder: 一个能对输入文字做语义解析的Encoder,一般是一个预训练好的模型。在实际应用中,CLIP模型由于在训练过程中采用了图像和文字的对比学习,使得学得的文字特征对图像更加具有鲁棒性,因此它的text encoder常被直接用来做文生图模型的text encoder(比如DALLE2)
-
Generation Model: 输入为文字token和图片噪声,输出为一个关于图片的压缩产物(latent space)。这里通常指的就是扩散模型,采用文字作为引导(guidance)的扩散模型原理,如DDPM、DDIM等扩散模型。
-
Decoder: 用图片的中间产物作为输入,产出最终的图片。Decoder的选择也有很多,同样也能用一个扩散模型作为Decoder。
总结
-
VAE模块:Variational Auto Encoder, ELBO loss, KL loss, GAN,Variational Auto Encoder
-
Unet模块:Unet, DDPM, DDIM, Cross Attention, Residual connectDDPM
-
CLIP模块:CLIP, OpenCLIP, Transformer, Vision TransformerCLIP和OpenCLIP Transformer Vision Transformer
每一个模块都包含着一些模型和所需要的一些先验知识,模块之间共同协作完成文生图任务,目前像DALL2, DALL3, Midjourney以及Stable Diffusion都是由这样的基本思路和模块组成,也统一颠覆了之前的图像生成方式。
此外,为了保证生图的稳定性和可控性,Stable Diffusion也可以和一些插件结合使用,如GroundingDINO, Segment Anything, Roop, ADetailer, ControlNet等ControlNet原理及应用 Grounding DINO调研 Segment anything调研 AI换脸技术调研
至此,我们系统总结了关于Stable Diffusion的每一个模块的构成和原理,此外还对一些需要掌握的先验知识以及一些控制生图稳定性和可控性的插件也进行了详细介绍。
原文地址:https://blog.csdn.net/xs1997/article/details/134651497
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_26642.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!