本文介绍: VAE(变分自编码器)是一种生成模型,结合了自编码器和概率图模型的思想。它通过学习数据的潜在分布,可以生成新的数据样本。VAE通过将输入数据映射到潜在空间中的分布,并在训练过程中最大化数据与潜在变量之间的条件概率来实现。其关键思想在于编码器将输入数据编码成潜在分布的参数,解码器则从这个分布中采样生成新的数据。这种生成方式不仅能够生成新的数据,还能够在潜在空间中进行插值和操作,提供了强大的特征学习和数据生成能力
σ11e−2σ12(x−μ1)2dx=2σ22σ12+μ12−2μ1μ2+μ22=2σ22σ12+(μ1−μ2)2
对上述式子进行汇总:
K
L
(
N
代码部分
损失函数
Encoder部分
Decoder部分
VAE整体架构
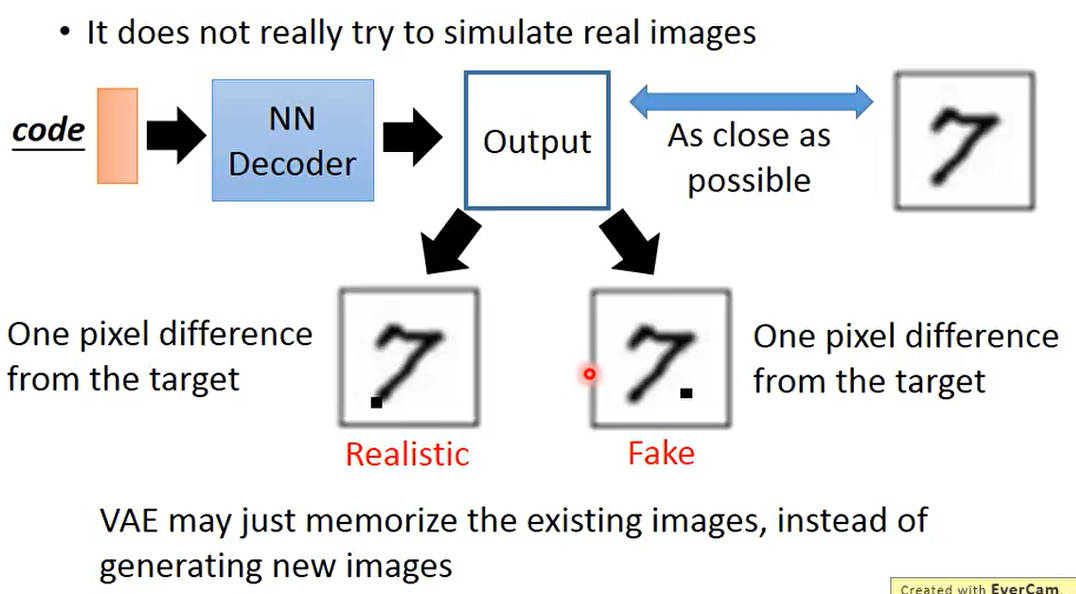
VAE问题
参考资料
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。