本文介绍: 在开源 LLM 与 ChatGPT 的详细性能比较中,作者深挖了一些现象背后的原因。然而,我们应该认识到文章的关键并非仅是简单的性能数值比较,更在于作者对背后现象的深刻剖析。因为在不同的规则或标准下,这些比较都不尽全面。而在我们研究的道路上,理解“为什么”比“是什么”更为重要,所有的研究都致力于不断改进,而未来的关键更在于应该探讨“怎么办”。尽管开源是广大研究者一致追求的目标,但要实现这一目标需要面对 LLM 训练和创新所需的高昂成本。
就在11月30日,ChatGPT 迎来了它的问世一周年,这个来自 OpenAI 的强大AI在过去一年里取得了巨大的发展,迅速吸引各个领域的用户群体。
我们首先回忆一下 OpenAI和ChatGPT这一年的大事记(表格由ChatGPT辅助生成):
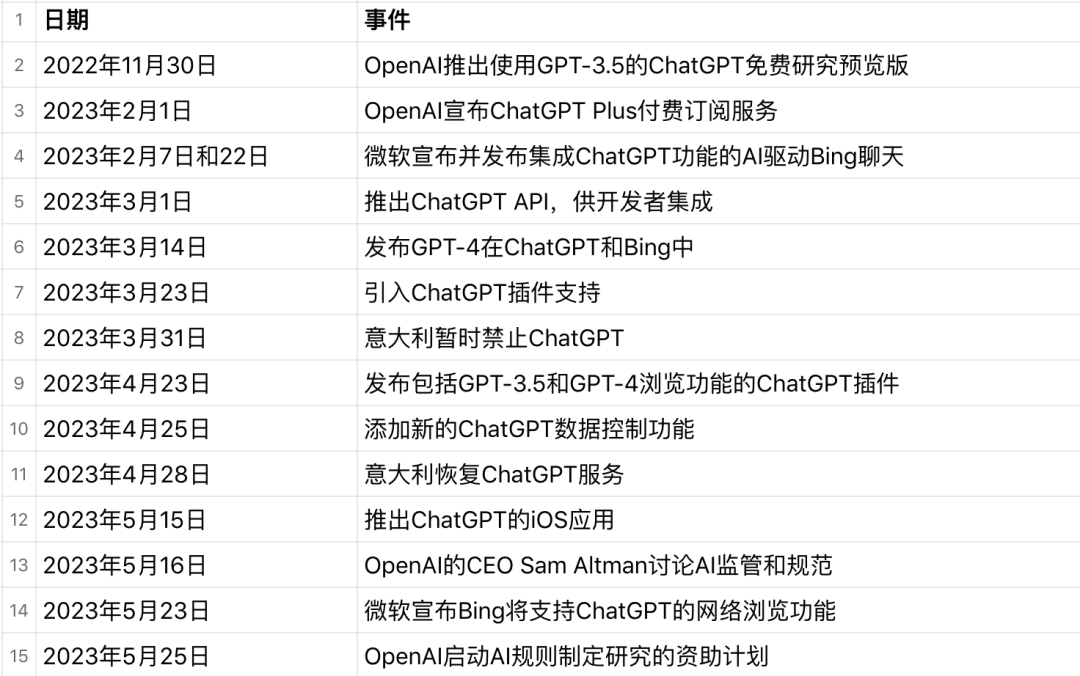
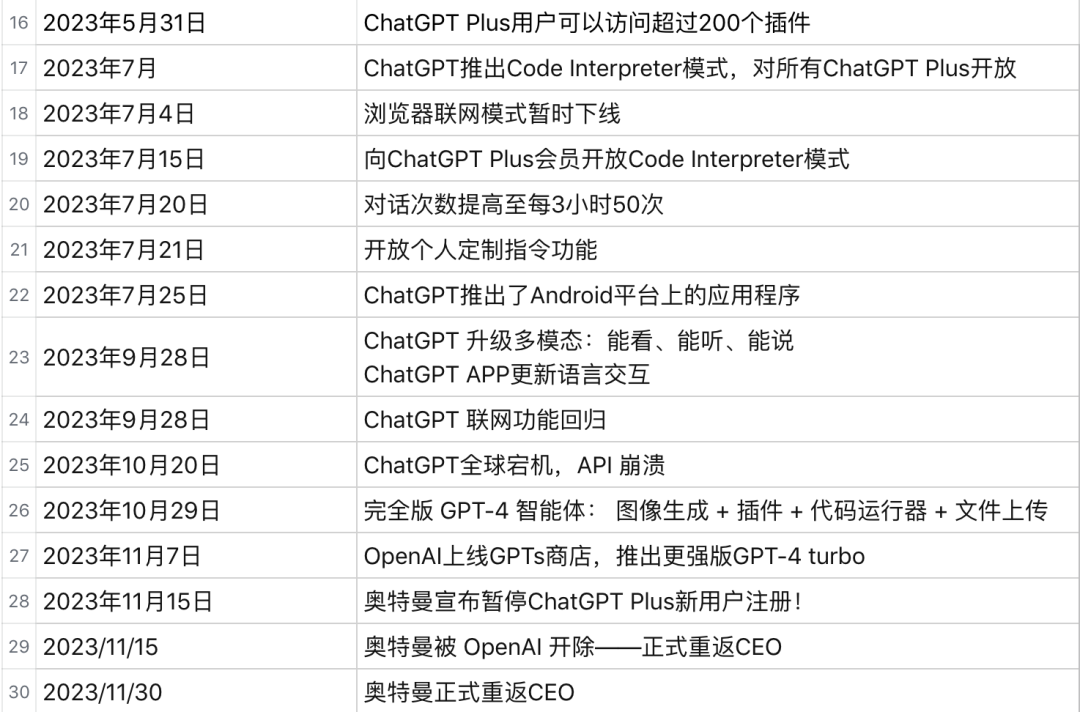
在这个具有里程碑意义的时刻,我们在回顾这一引领变革的产品的同时,也需要注意到新一代的开源大语言模型也在崛起。
不开源的 ChatGPT VS 开源 LLM
ChatGPT 不开源的缺点
开源 LLM 有何好处?
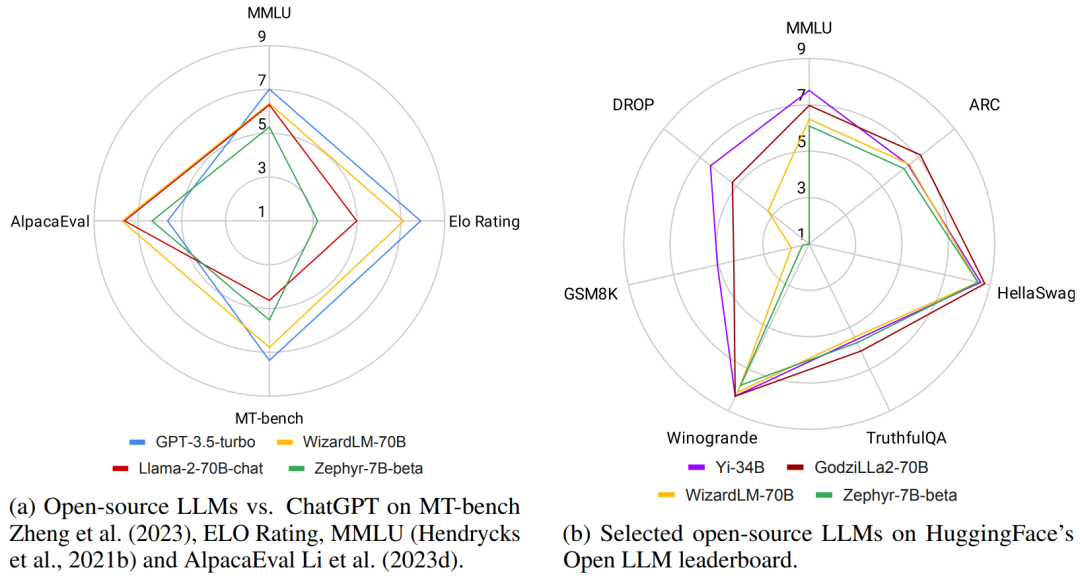
开源 LLM 与 ChatGPT 的比较
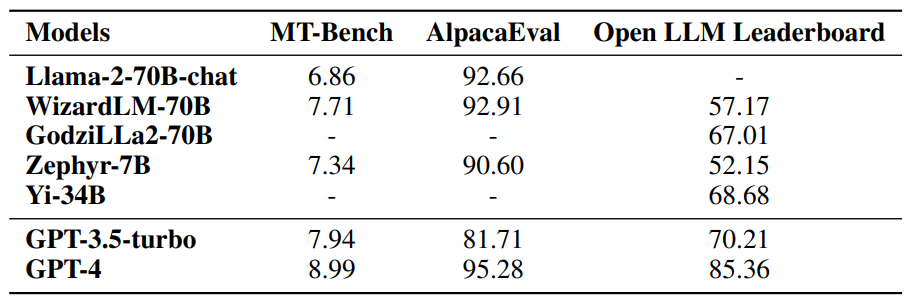
1. 通用能力上的对比
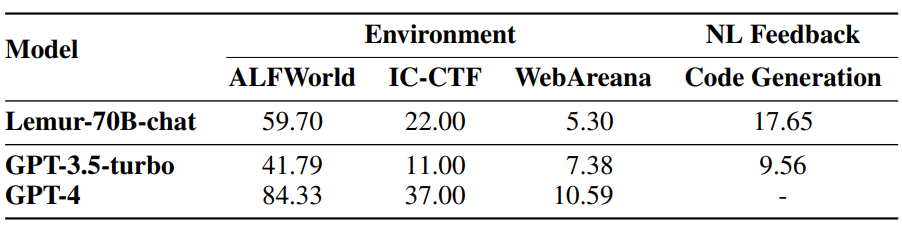
2. 智能体能力上的对比
3. 逻辑推理能力上的对比
4. 长序列建模能力
5. 特定应用能力的对比
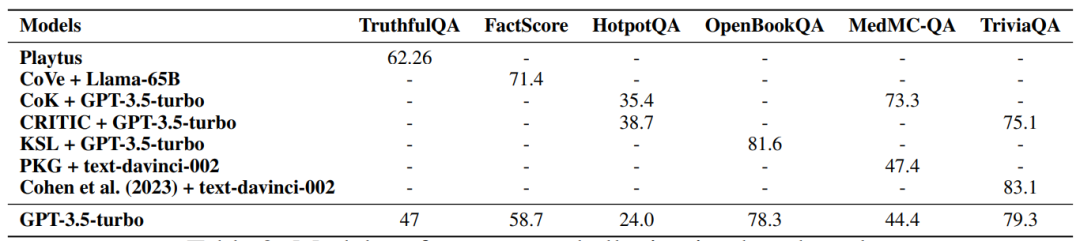
6. 可信度方面的比较
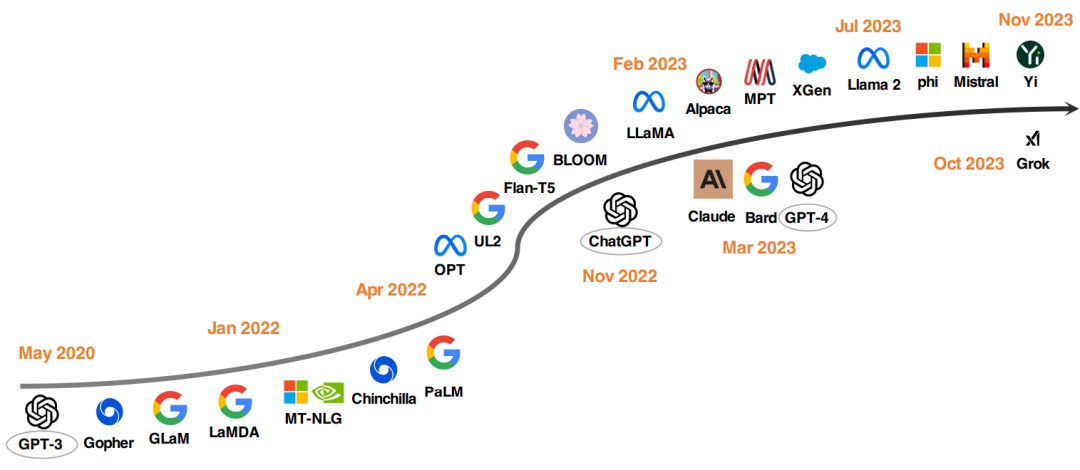
LLM 的发展趋势
最佳的开源 LLM 配置
待改进之处
总结

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。