官方文档https://clickhouse.com/docs/en/engines/table–engines
MergerTree引擎家族,只要带MergerTree的就是
MergerTree
ReplicatedMergeTree
ReplicatedAggregatingMergeTree
ReplicatedReplacingMergeTree
ReplicatedSummingMergeTree
ReplacingMergeTree
SummingMergeTree
AggregatingMergeTree
其他引擎
Distributed
Merge
MaterializedView
最佳实践:
4节点的集群,1-2节点为分片1,且1-2互为对方副本,3-4节点为分片2,且3-4互为对方副本,集群配置文件中的子配置项分片权重的配置不用配置会直接使用默认值1即数据平分到2个现有分片,集群配置文件中的子配置项<internal_replication></internal_replication>数据是否同时写入多个副本的配置配置为true即写操作只选一个正常的副本写入数据然后数据的复制工作交给实际需要写入数据的表本身而不是分布式表。
创建Distributed分布式表其中该分布式表使用ReplicatedMergeTree引擎的表作为子表,分布式表不再需要配置sharding_key,数据插入Distributed分布式表后,此时在4个节点上查看到的分布式表数据都是一样的
创建Distributed分布式表其中该分布式表使用ReplicatedMergeTree引擎的表作为子表,分布式表不再需要配置sharding_key,数据插入各个节点的ReplicatedMergeTree引擎子表,此时在4个节点上查看到的分布式表数据是一样的
创建Distributed分布式表其中该分布式表使用MergeTree引擎的表作为子表,数据库插入Distributed分布式表或各个节点的MergeTree引擎子表后,在4个节上看到的分布式表数据不一致,且经常错乱无章
仅仅使用ENGINE = MergeTree()表引擎的话,Clickhouse缺少了两个功能————数据高可用(HA)和横向扩展。HA的目的是为了如果有一个数据副本丢失或者损坏不至于完全丢失数据,至于横向扩展自然是为了提高数据存储能力了。数据高可用(HA)的实现需要使用ReplicatedMergeTree表引擎,横向扩展的实现需要使用Distributed表引擎,Clickhouse github上有一段总结
if your data is too big to fit/ to process on one server – use sharding
to balance the load between replicas and to combine the result of selects from different shards – use Distributed table.
MergeTree表引擎
https://clickhouse.com/docs/zh/engines/table–engines/mergetree–family/mergetree
ENGINE = MergeTree()括号里面没有参数,所以不受宏配置macros的影响。但是ENGINE = MergeTree()有setting选项enable_mixed_granularity_parts,如果您的表里有很大的行,可以开启enable_mixed_granularity_parts这项配置来提升SELECT查询的性能。
MergeTree 系列的引擎被设计用于插入极大量的数据到一张表当中。数据可以以数据片段的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合并。相比在插入时不断修改(重写)已存储的数据,这种策略会高效很多。其实就是批量数据快速插入和后台并发处理的两大优势。
CREATE TABLE lukestest1.table_mergetree ON CLUSTER cluster_2shared2replicas(id String,create_time datetime) ENGINE = MergeTree() ORDER BY id;
insert into lukestest1.table_mergetree (id ,create_time) values ('1','2020-11-17'),('2','2020-11-17'),('3','2020-11-17'),('4','2020-11-17') ('5','2020-11-17'),('6','2020-11-17'),('7','2020-11-17'),('8','2020-11-17'),('9','2020-11-17'),('10','2020-11-17'),('11','2020-11-17'),('12','2020-11-17');
CREATE TABLE lukestest2.table_mergetree ON CLUSTER cluster_2shared2replicas(id String,create_time datetime) ENGINE = MergeTree() ORDER BY id;
insert into lukestest2.table_mergetree (id ,create_time) values ('1','2020-11-17'),('2','2020-11-17'),('3','2020-11-17'),('4','2020-11-17') ('5','2020-11-17'),('6','2020-11-17'),('7','2020-11-17'),('8','2020-11-17'),('9','2020-11-17'),('10','2020-11-17'),('11','2020-11-17'),('12','2020-11-17');
以下结果只在节点1可以查询到结果12行,其他节点查询的结果都是0行
select * from lukestest1.table_mergetree;
select * from lukestest2.table_mergetree;
`create table lukestest1.table1 (country String, province String, value String ) engine=MergeTree() partition by (country, province) order by value;`
–不指定cluster cluster_2shared2replicas表示只在当前节点创建表
insert into lukestest1.table1 (country, province, value) values ('China','JXi','good'), ('China','SXi','good'), ('China','SD','good'), ('China','JS','good');
–engine=MergeTree()只在当前节点insert数据
在节点1创建表,发现节点2,3,4都没有这张表,数据也只在节点1有
create table lukestest1.table2 on cluster cluster_2shared2replicas (country String, province String, value String ) engine=MergeTree() partition by (country, province) order by value;
指定cluster cluster_2shared2replicas表示只在所有节点创建表
insert into lukestest1.table2 (country, province, value) values ('China','JXi','good'), ('China','SXi','good'), ('China','SD','good'), ('China','JS','good');
–engine=MergeTree()只在当前节点insert数据
在节点1创建表并插入数据,发现节点2,3,4有这张表,但是只有节点1有数据,节点2,3,4都没有数据
ReplicatedMergeTree表引擎
https://clickhouse.com/docs/zh/engines/table-engines/mergetree–family/replication
ENGINE = ReplicatedMergeTree()括号里面没有cluster但是有shard和replica参数,所以受宏配置macros的影响
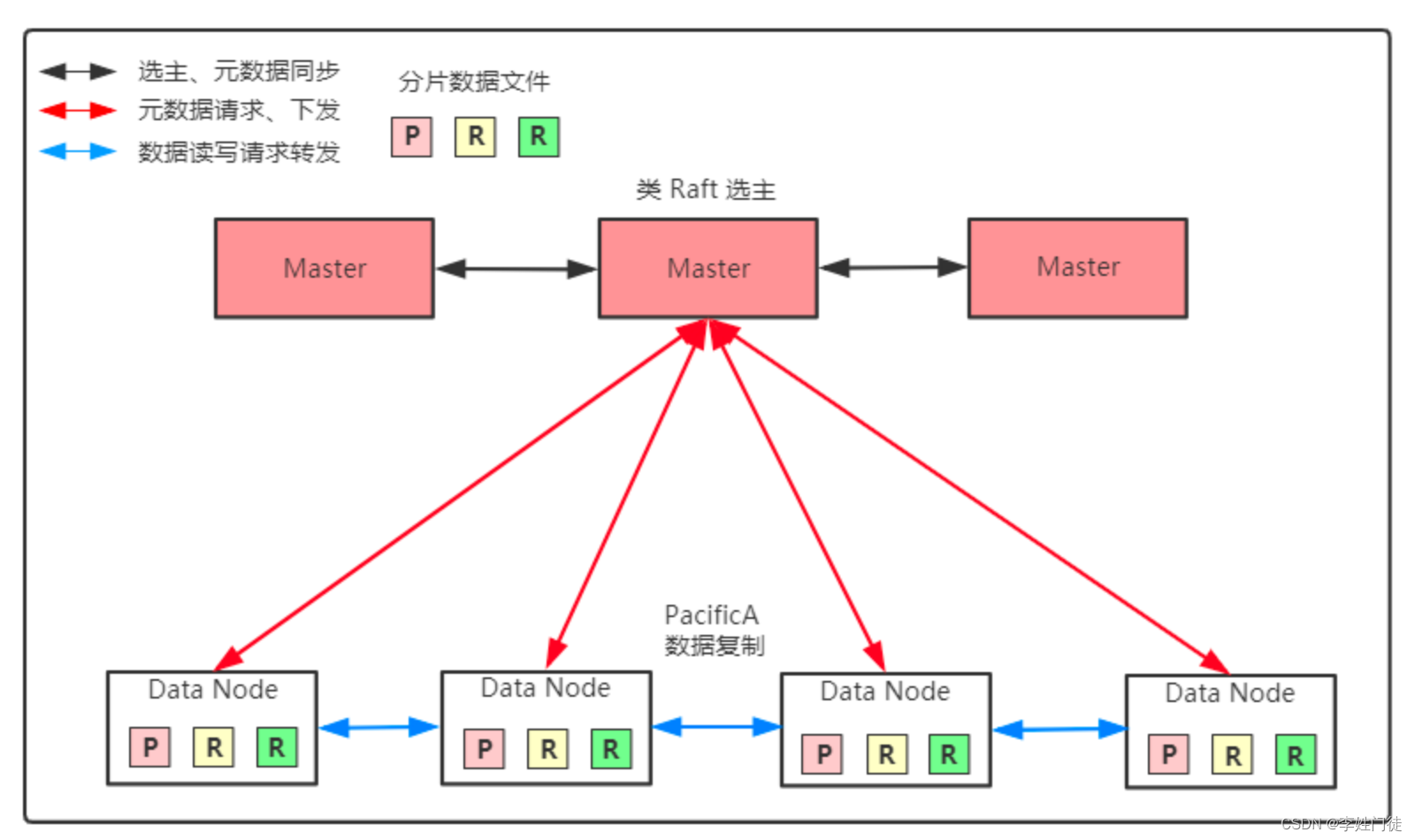
Clickhouse只有MergeTree 系列里的表可支持副本, 其中可以是Summing,Replacing,Aggregating等名称的ReplicatedMergeTree的表就是MergeTree系列里面支持副本的引擎,ReplicatedMergeTreez只是其中可支持数据副本的一种引擎,副本是表级别的,不是整个服务器级的。所以,服务器里可以同时有复制表和非复制表。副本不依赖分片。每个分片有它自己的独立副本。ClickHouse 使用 Apache ZooKeeper 存储副本的元信息。请使用 ZooKeeper 3.4.5 或更高版本。要使用副本,需在 Zookeeper 服务器的配置部分设置相应参数。
Replicated*MergeTree 参数和建表语句
zoo_path — ZooKeeper 中该表的路径。–见下例中的/clickhouse/tables/{layer}-{shard}/table_name
replica_name — ZooKeeper 中的该表的副本名称。 –见下例中的{replica}
示例:
CREATE TABLE table_name
(
EventDate DateTime,
CounterID UInt32,
UserID UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/table_name', '{replica}')
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID)
/clickhouse/tables/ 是公共前缀,我们推荐使用这个。
{layer}-{shard} 是分片标识部分。
table_name 是该表在 ZooKeeper 中的名称。
{replica}副本名称用于标识同一个表分片的不同副本。
你也可以显式指定这些参数,而不是使用宏macros替换。使用大型集群时,我们建议使用宏替换,因为它可以降低出错的可能性。我个人环境中的宏macros配置如下(1-2节点配置01,3-4节点配置02,的话每个节点配置为自己的服务器名即可比如DAILACHDBUD001配置为DAILACHDBUD001)。
<macros>
<shard>01</shard>
<replica>DAILACHDBUD001</replica>
</macros>
CREATE TABLE lukestest1.table_ReplicatedMergeTree ON CLUSTER cluster_2shared2replicas(id String,create_time datetime) ENGINE = ReplicatedMergeTree() PARTITION BY toYYYYMM(create_time) ORDER BY id;
insert into lukestest1.table_ReplicatedMergeTree (id ,create_time) values ('1','2020-11-17'),('2','2020-11-17'),('3','2020-11-17'),('4','2020-11-17') ('5','2020-11-17'),('6','2020-11-17'),('7','2020-11-17'),('8','2020-11-17'),('9','2020-11-17'),('10','2020-11-17'),('11','2020-11-17'),('12','2020-11-17');
CREATE TABLE lukestest2.table_ReplicatedMergeTree ON CLUSTER cluster_2shared2replicas(id String,create_time datetime) ENGINE = ReplicatedMergeTree() PARTITION BY toYYYYMM(create_time) ORDER BY id;
insert into lukestest2.table_ReplicatedMergeTree (id ,create_time) values ('1','2020-11-17'),('2','2020-11-17'),('3','2020-11-17'),('4','2020-11-17') ('5','2020-11-17'),('6','2020-11-17'),('7','2020-11-17'),('8','2020-11-17'),('9','2020-11-17'),('10','2020-11-17'),('11','2020-11-17'),('12','2020-11-17');
以下结果在节点1和节点2可以查询到结果12行,节点3和节点4查询的结果都是0行,原因是因为节点1和节点2是同一个shard分片下面的replica,也就是节点1和节点2互为对方的副本
select * from lukestest1.table_ReplicatedMergeTree;
select * from lukestest2.table_ReplicatedMergeTree;
ReplicatedReplacingMergeTree表引擎
Clickhouse集群4节点,在节点1执行如下
CREATE TABLE lukestest1.table_ReplicatedReplacingMergeTree ON CLUSTER cluster_2shared2replicas(id String,create_time datetime) ENGINE = ReplicatedReplacingMergeTree() PARTITION BY toYYYYMM(create_time) ORDER BY id;
insert into lukestest1.table_ReplicatedReplacingMergeTree (id ,create_time) values ('1','2020-11-17'),('2','2020-11-17'),('3','2020-11-17'),('4','2020-11-17') ('5','2020-11-17'),('6','2020-11-17'),('7','2020-11-17'),('8','2020-11-17'),('9','2020-11-17'),('10','2020-11-17'),('11','2020-11-17'),('12','2020-11-17');
CREATE TABLE lukestest2.table_ReplicatedReplacingMergeTree ON CLUSTER cluster_2shared2replicas(id String,create_time datetime) ENGINE = ReplicatedReplacingMergeTree() PARTITION BY toYYYYMM(create_time) ORDER BY id;
insert into lukestest2.table_ReplicatedReplacingMergeTree (id ,create_time) values ('1','2020-11-17'),('2','2020-11-17'),('3','2020-11-17'),('4','2020-11-17') ('5','2020-11-17'),('6','2020-11-17'),('7','2020-11-17'),('8','2020-11-17'),('9','2020-11-17'),('10','2020-11-17'),('11','2020-11-17'),('12','2020-11-17');
以下结果在节点1和节点2可以查询到结果12行,节点3和节点4查询的结果都是0行,原因是因为节点1和节点2是同一个shard分片下面的replica,也就是节点1和节点2互为对方的副本
select * from lukestest1.table_ReplicatedReplacingMergeTree;
select * from lukestest2.table_ReplicatedReplacingMergeTree;
ReplicatedAggregatingMergeTree表引擎
Clickhouse集群4节点,在节点1执行如下
CREATE TABLE lukestest1.table_ReplicatedAggregatingMergeTree ON CLUSTER cluster_2shared2replicas(id String,create_time datetime) ENGINE = ReplicatedAggregatingMergeTree() PARTITION BY toYYYYMM(create_time) ORDER BY id;
insert into lukestest1.table_ReplicatedAggregatingMergeTree (id ,create_time) values ('1','2020-11-17'),('2','2020-11-17'),('3','2020-11-17'),('4','2020-11-17') ('5','2020-11-17'),('6','2020-11-17'),('7','2020-11-17'),('8','2020-11-17'),('9','2020-11-17'),('10','2020-11-17'),('11','2020-11-17'),('12','2020-11-17');
CREATE TABLE lukestest2.table_ReplicatedAggregatingMergeTree ON CLUSTER cluster_2shared2replicas(id String,create_time datetime) ENGINE = ReplicatedAggregatingMergeTree() PARTITION BY toYYYYMM(create_time) ORDER BY id;
insert into lukestest2.table_ReplicatedAggregatingMergeTree (id ,create_time) values ('1','2020-11-17'),('2','2020-11-17'),('3','2020-11-17'),('4','2020-11-17') ('5','2020-11-17'),('6','2020-11-17'),('7','2020-11-17'),('8','2020-11-17'),('9','2020-11-17'),('10','2020-11-17'),('11','2020-11-17'),('12','2020-11-17');
以下结果在节点1和节点2可以查询到结果12行,节点3和节点4查询的结果都是0行,原因是因为节点1和节点2是同一个shard分片下面的replica,也就是节点1和节点2互为对方的副本
select * from lukestest1.table_ReplicatedAggregatingMergeTree;
select * from lukestest2.table_ReplicatedAggregatingMergeTree;
Distributed引擎
https://clickhouse.com/docs/zh/engines/table-engines/special/distributed
ENGINE = Distributed()括号里面有cluster和sharding_key参数,不受宏配置macros的影响,但是受集群配置中指定集群的影响,比如个人案例受cluster_2shared2replicas这个指定集群的影响
ENGINE = Distributed()分布式表引擎本身不存储数据,但可以在多个服务器上进行分布式查询,实际上ENGINE = Distributed()分布式表是一种view,映射到ClickHouse集群的本地表。读是自动并行的。读取时,远程服务器表的索引(如果有的话)会被使用。
通过分布式引擎可以像使用本地服务器一样使用集群。但是,集群不是自动扩展的:你必须编写集群配置到集群环境下的所有服务器的配置文件中。
查询一个Distributed表时,SELECT查询被发送到所有的分片,不管数据是如何分布在分片上的(它们可以完全随机分布)。当您添加一个新分片时,您不必将旧数据传输到它。相反,您可以使用更重的权重向其写入新数据——数据的分布会稍微不均匀,但查询将正确有效地工作。
向集群写数据的方法有两种:
一,自已指定要将哪些数据写入哪些服务器,并直接在每个分片上执行写入。换句话说,在ENGINE = Distributed()分布式表上执行select,在数据表(ENGINE = Distributed()分布式表的子表)上INSERT。 这是最灵活的解决方案,也是最佳解决方案,因为数据可以完全独立地写入不同的分片。
二,在ENGINE = Distributed()分布式表上执行INSERT。在这种情况下,分布式表会跨服务器分发插入数据。 为了写入分布式表,必须要配置分片键sharding_key。当然,如果只有一个分片,则写操作在没有分片键的情况下也能工作,因为这种情况下分片键没有意义。每个分片的写入权重可以在集群配置文件中的子配置项中定义。默认情况下,权重等于1。数据依据分片权重按比例分发到分片上。例如,如果有两个分片,第一个分片的权重是9,而第二个分片的权重是10,则发送9/19的行到第一个分片,10/19的行到第二个分片。分片数据该写入一个副本还是写入所有副本,可在集群配置文件中的子配置项<internal_replication></internal_replication>中定义。此参数设置为true时,写操作只选一个正常的副本写入数据。如果分布式表的子表是复制表(*ReplicaMergeTree),请使用此方案。换句话说,这其实是把数据的复制工作交给实际需要写入数据的表本身而不是分布式表。若此参数设置为false(默认值),写操作会将数据写入所有副本。
备注:在创建ENGINE = Distributed()表时指定sharding_key或不指定sharding_key或随意指定sharding_key值,并不会影响各个节点执行select count(*) from ENGINE = Distributed()表的总行数
Clickhouse集群4节点,在节点1执行如下
CREATE TABLE lukestest1.table_Distributed_mergetree ON CLUSTER cluster_2shared2replicas(id String,create_time datetime) ENGINE = Distributed(cluster_2shared2replicas, lukestest1, table_mergetree,rand());
insert into lukestest1.table_Distributed_mergetree (id ,create_time) values ('21','2020-11-17'),('22','2020-11-17'),('23','2020-11-17'),('24','2020-11-17'),('25','2020-11-17'),('26','2020-11-17'),('27','2020-11-17'),('28','2020-11-17');
CREATE TABLE lukestest1.table_Distributed_ReplicatedMergeTree ON CLUSTER cluster_2shared2replicas(id String,create_time datetime) ENGINE = Distributed(cluster_2shared2replicas, lukestest1, table_ReplicatedMergeTree,rand());
insert into lukestest1.table_Distributed_ReplicatedMergeTree (id ,create_time) values ('21','2020-11-17'),('22','2020-11-17'),('23','2020-11-17'),('24','2020-11-17'),('25','2020-11-17'),('26','2020-11-17'),('27','2020-11-17'),('28','2020-11-17');
CREATE TABLE lukestest2.table_Distributed_mergetree ON CLUSTER cluster_2shared2replicas(id String,create_time datetime) ENGINE = Distributed(cluster_2shared2replicas, lukestest2, table_mergetree,rand());
insert into lukestest2.table_Distributed_mergetree (id ,create_time) values ('21','2020-11-17'),('22','2020-11-17'),('23','2020-11-17'),('24','2020-11-17'),('25','2020-11-17'),('26','2020-11-17'),('27','2020-11-17'),('28','2020-11-17');
CREATE TABLE lukestest2.table_Distributed_ReplicatedMergeTree ON CLUSTER cluster_2shared2replicas(id String,create_time datetime) ENGINE = Distributed(cluster_2shared2replicas, lukestest2, table_ReplicatedMergeTree,rand());
insert into lukestest2.table_Distributed_ReplicatedMergeTree (id ,create_time) values ('21','2020-11-17'),('22','2020-11-17'),('23','2020-11-17'),('24','2020-11-17'),('25','2020-11-17'),('26','2020-11-17'),('27','2020-11-17'),('28','2020-11-17');
以下结果在节点1可以分别查询到14(20),20,18(20),20行
以下结果在节点2可以分别查询到0(6),20,0(2),20行
以下结果在节点3可以分别查询到6(20),20,0(18),20行
以下结果在节点4可以分别查询到0(14),20,2(20),20行
select * from lukestest1.table_Distributed_mergetree;
select * from lukestest1.table_Distributed_ReplicatedMergeTree;
select * from lukestest2.table_Distributed_mergetree;
select * from lukestest2.table_Distributed_ReplicatedMergeTree;
以下结果在节点1可以分别查询到14,15,18,18行
以下结果在节点2可以分别查询到0,15,0,18行
以下结果在节点3可以分别查询到6,5,0,2行
以下结果在节点4可以分别查询到0,5,2,2行
select * from lukestest1.table_mergetree;
select * from lukestest1.table_ReplicatedMergeTree;
select * from lukestest2.table_mergetree;
select * from lukestest2.table_ReplicatedMergeTree;
已有数据表的情况下,即当Distributed表指向当前服务器上已经存在的一个表时,需要使用CREATE TABLE Distributed_table_name ON CLUSTER CLUSTER_NAME AS existed_table_name ENGINE = Distributed()
Clickhouse集群4节点,已有数据表是MergeTree()引擎,执行如下情况
CREATE TABLE lukestest1.tableMergeTree1 ON CLUSTER cluster_2shared2replicas (id String,create_time datetime) ENGINE = MergeTree() ORDER BY id;
--节点1执行
insert into lukestest1.tableMergeTree1 (id ,create_time) values ('11','2020-11-17'),('12','2020-11-17'),('13','2020-11-17'),('14','2020-11-17');
--节点1执行
insert into lukestest1.tableMergeTree1 (id ,create_time) values ('21','2020-11-17'),('22','2020-11-17'),('23','2020-11-17'),('24','2020-11-17');
--节点2执行
insert into lukestest1.tableMergeTree1 (id ,create_time) values ('31','2020-11-17'),('32','2020-11-17'),('33','2020-11-17'),('34','2020-11-17');
--节点3执行
insert into lukestest1.tableMergeTree1 (id ,create_time) values ('41','2020-11-17'),('42','2020-11-17'),('43','2020-11-17'),('44','2020-11-17');
--节点4执行
CREATE TABLE lukestest1.tableMergeTree1_view ON CLUSTER cluster_2shared2replicas AS lukestest1.tableMergeTree1 ENGINE = Distributed(cluster_2shared2replicas, lukestest1, tableMergeTree1);
--节点1执行
CREATE TABLE lukestest1.tableMergeTree1_view01 ON CLUSTER cluster_2shared2replicas AS lukestest1.tableMergeTree1 ENGINE = Distributed(cluster_2shared2replicas, lukestest1, tableMergeTree1,01);
--节点1执行
CREATE TABLE lukestest1.tableMergeTree1_view02 ON CLUSTER cluster_2shared2replicas AS lukestest1.tableMergeTree1 ENGINE = Distributed(cluster_2shared2replicas, lukestest1, tableMergeTree1,02);
--节点1执行
CREATE TABLE lukestest1.tableMergeTree1_view_rand ON CLUSTER cluster_2shared2replicas AS lukestest1.tableMergeTree1 ENGINE = Distributed(cluster_2shared2replicas, lukestest1, tableMergeTree1,rand());
--节点1执行
以下结果在节点1可以分别查到4,8行数据库,分别是看到只有自己的11-14,看到只有11-14和31-34的8行
以下结果在节点2可以分别查到4,8行数据库,分别是看到只有自己的21-24,看到只有21-24和41-44的8行
以下结果在节点3可以分别查到4,8行数据库,分别是看到只有自己的31-34,看到只有11-14和31-34的8行
以下结果在节点4可以分别查到4,8行数据库,分别是看到只有自己的41-44,看到只有21-24和41-44的8行
select * from lukestest1.tableMergeTree1;
select * from lukestest1.tableMergeTree1_view;
备注:也就是1-3节点看到的Distributed数据一致,2-4节点看到的Distributed数据一致,而且不管Distributed中shard_key是如何设置,每个节点看到Distributed引擎的表的数据都只有8行而不是16行。Distributed中shard_key设置可以为如下Distributed(cluster_2shared2replicas, lukestest1, tableMergeTree1),Distributed(cluster_2shared2replicas, lukestest1, tableMergeTree1,01),Distributed(cluster_2shared2replicas, lukestest1, tableMergeTree1,02),Distributed(cluster_2shared2replicas, lukestest1, tableMergeTree1,rand())
Clickhouse集群4节点,已有数据表是ReplicatedMergeTree()引擎,执行如下情况
CREATE TABLE lukestest1.table_ReplicatedMergeTree1 ON CLUSTER cluster_2shared2replicas(id String,create_time datetime) ENGINE = ReplicatedMergeTree() PARTITION BY toYYYYMM(create_time) ORDER BY id;
--节点1执行
insert into lukestest1.table_ReplicatedMergeTree1 (id ,create_time) values ('11','2020-11-17'),('12','2020-11-17'),('13','2020-11-17'),('14','2020-11-17');
--节点1执行
insert into lukestest1.table_ReplicatedMergeTree1 (id ,create_time) values ('21','2020-11-17'),('22','2020-11-17'),('23','2020-11-17'),('24','2020-11-17');
--节点2执行
insert into lukestest1.table_ReplicatedMergeTree1 (id ,create_time) values ('31','2020-11-17'),('32','2020-11-17'),('33','2020-11-17'),('34','2020-11-17');
--节点3执行
insert into lukestest1.table_ReplicatedMergeTree1 (id ,create_time) values ('41','2020-11-17'),('42','2020-11-17'),('43','2020-11-17'),('44','2020-11-17');
--节点4执行
CREATE TABLE lukestest1.table_ReplicatedMergeTree1_view ON CLUSTER cluster_2shared2replicas AS lukestest1.table_ReplicatedMergeTree1 ENGINE = Distributed(cluster_2shared2replicas, lukestest1, table_ReplicatedMergeTree1,rand());
--节点1执行
以下结果在节点1可以分别查到8,16行数据库,分别是看到只有自己的11-14和节点2的21-24,看到所有16行
以下结果在节点2可以分别查到8,16行数据库,分别是看到只有自己的21-24和节点1的11-14,看到所有16行
以下结果在节点3可以分别查到8,16行数据库,分别是看到只有自己的31-34和节点4的41-44,看到所有16行
以下结果在节点4可以分别查到8,16行数据库,分别是看到只有自己的41-44和节点3的31-44,看到所有16行
select * from lukestest1.table_ReplicatedMergeTree1;
select * from lukestest1.table_ReplicatedMergeTree1_view;
创建Distributed分布式表其中该分布式表使用ReplicatedMergeTree引擎的表作为子表,数据插入各个节点的ReplicatedMergeTree引擎子表,此时在4个节点上查看到的分布式表数据是一致的,如下实验
CREATE TABLE lukestest1.table_ReplicatedMergeTree2 ON CLUSTER cluster_2shared2replicas(id String,create_time datetime) ENGINE = ReplicatedMergeTree() PARTITION BY toYYYYMM(create_time) ORDER BY id;
--节点1执行
CREATE TABLE lukestest1.table_Distributed_ReplicatedMergeTree2 ON CLUSTER cluster_2shared2replicas(id String,create_time datetime) ENGINE = Distributed(cluster_2shared2replicas, lukestest1, table_ReplicatedMergeTree2,rand());
--节点1执行
insert into lukestest1.table_ReplicatedMergeTree2 (id ,create_time) values ('1','2020-11-17'),('2','2020-11-17'),('3','2020-11-17'),('4','2020-11-17');
--节点1执行
insert into lukestest1.table_ReplicatedMergeTree2 (id ,create_time) values ('21','2020-11-17'),('22','2020-11-17'),('23','2020-11-17'),('24','2020-11-17');
--节点2执行
insert into lukestest1.table_ReplicatedMergeTree2 (id ,create_time) values ('31','2020-11-17'),('32','2020-11-17'),('33','2020-11-17'),('34','2020-11-17');
--节点3执行
insert into lukestest1.table_ReplicatedMergeTree2 (id ,create_time) values ('41','2020-11-17'),('42','2020-11-17'),('43','2020-11-17'),('44','2020-11-17');
--节点4执行
以下结果在节点1可以分别查询到8,16行,8行数据与节点2数据一致,16行数据和其他节点一致
以下结果在节点2可以分别查询到8,16行,8行数据与节点1数据一致,16行数据和其他节点一致
以下结果在节点3可以分别查询到8,16行,8行数据与节点4数据一致,16行数据和其他节点一致
以下结果在节点4可以分别查询到8,16行,8行数据与节点3数据一致,16行数据和其他节点一致
select * from lukestest1.table_ReplicatedMergeTree2;
select * from lukestest1.table_Distributed_ReplicatedMergeTree2;
ENGINE = Distributed的表不能做update操作
ALTER TABLE lukestest1.tableMergeTree1_view ON CLUSTER cluster_2shared2replicas UPDATE id = 11 where id=15;
ALTER TABLE lukestest1.tableMergeTree1_view ON CLUSTER cluster_2shared2replicas UPDATE create_time = '2022-11-17' where create_time = '2020-11-17';
两者都报错DB::Exception: Table engine Distributed doesn't support mutations. (NOT_IMPLEMENTED) (version 23.4.2.11 (official build))
ENGINE = MergeTree()的表不能对ORDER BY的字段做update
ALTER TABLE lukestest1.tableMergeTree1 ON CLUSTER cluster_2shared2replicas UPDATE id = 101 where id=11;--报错DB::Exception: Cannot UPDATE key column `id`. (CANNOT_UPDATE_COLUMN) (version 23.4.2.11 (official build))
ALTER TABLE lukestest1.tableMergeTree1 ON CLUSTER cluster_2shared2replicas UPDATE create_time = '2022-11-17' where create_time = '2020-11-17';
正常执行,不再报错
创建ENGINE = Distributed分布式表,分布式表名和子表名(子表就是Distributed(cluster_2shared2replicas, lukestest1, table_distributed1,rand())里面的表名)不能一致
CREATE TABLE lukestest1.table_distributed1 ON CLUSTER cluster_2shared2replicas (id String,create_time datetime) ENGINE = Distributed(cluster_2shared2replicas, lukestest1, table_distributed1,rand());
报错DB::Exception: Distributed table table_distributed1 looks at itself. (INFINITE_LOOP) (version 23.4.2.11 (official build)). (INFINITE_LOOP)
创建ENGINE = Distributed分布式表,分布式表名lukestest1.table_distributed1,子表名lukestest1.table_MergeTree1,但是子表名不存在,此时分布式表可以创建成功,但是插入数据会报错子表不存在,必须先在各个节点创建好子表后再插入数据
CREATE TABLE lukestest1.table_distributed1 ON CLUSTER cluster_2shared2replicas (id String,create_time datetime) ENGINE = Distributed(cluster_2shared2replicas, lukestest1, table_MergeTree1,rand());
--表正常创建,不再报错
insert into lukestest1.table_distributed1 (id ,create_time) values ('11','2020-11-17'),('12','2020-11-17'),('13','2020-11-17'),('14','2020-11-17');报错DB::Exception: Table lukestest1.table_MergeTree1 doesn't exist. (UNKNOWN_TABLE)
额外的实验1,ENGINE = Distributed和ENGINE = MergeTree(),数据只插入节点1和节点2,或数据只插入节点1和节点3,或数据只插入节点1
CREATE TABLE lukestest1.table_mergetree3 ON CLUSTER cluster_2shared2replicas(id String,create_time datetime) ENGINE = MergeTree() ORDER BY id;
--节点1执行
CREATE TABLE lukestest1.table_Distributed_mergetree3 ON CLUSTER cluster_2shared2replicas(id String,create_time datetime) ENGINE = Distributed(cluster_2shared2replicas, lukestest1, table_mergetree3,rand());
--节点1执行
insert into lukestest1.table_mergetree3 (id ,create_time) values ('1','2020-11-17'),('2','2020-11-17'),('3','2020-11-17'),('4','2020-11-17');
--节点1执行
insert into lukestest1.table_mergetree3 (id ,create_time) values ('21','2020-11-17'),('22','2020-11-17'),('23','2020-11-17'),('24','2020-11-17');
--节点2执行
以下结果在节点1可以分别查询到4,4行,第一个4行数据与节点2数据不一致,第二个4行数据与节点2数据不一致,节点1的数据全是自己的1,2,3,4
以下结果在节点2可以分别查询到4,4行,第一个4行数据与节点1数据不一致,第二个4行数据和节点1数据不一致,节点1的数据全是自己的21,22,23,24
以下结果在节点3可以分别查询到0,4行,4行数据与节点1一致,是1,2,3,4
以下结果在节点4可以分别查询到0,4行,4行数据与节点2一致,是21,22,23,24
select * from lukestest1.table_mergetree3;
select * from lukestest1.table_Distributed_mergetree3;
insert into lukestest1.table_mergetree3 (id ,create_time) values ('11','2020-11-17'),('12','2020-11-17'),('13','2020-11-17'),('14','2020-11-17');
--节点1执行
insert into lukestest1.table_mergetree3 (id ,create_time) values ('31','2020-11-17'),('32','2020-11-17'),('33','2020-11-17'),('34','2020-11-17');
--节点3执行
以下结果在节点1可以分别查询到8,12行,8行数据是1,2,3,4,11,12,13,14,12行数据是1,2,3,4,11,12,13,14,31,32,33,34
以下结果在节点2可以分别查询到4,8行,4行数据是21,22,23,24,8行数据是21,22,23,24,31,32,33,34
以下结果在节点3可以分别查询到4,8行,4行数据是31,32,33,34,8行数据是21,22,23,24,31,32,33,34
以下结果在节点4可以分别查询到0,8或4行,4行和8行不定期出现一会出现4行一会出现8行,4行数据是21,22,23,24,8行数据是1,2,3,4,11,12,13,14
select * from lukestest1.table_mergetree3;
select * from lukestest1.table_Distributed_mergetree3;
insert into lukestest1.table_mergetree3 (id ,create_time) values ('111','2020-11-17'),('112','2020-11-17'),('113','2020-11-17'),('114','2020-11-17');
--节点1执行
以下结果在节点1可以分别查询到12,12或16行,12行是1,2,3,4,11,12,13,14,111,112,113,114,分布式表有时出现12行和有时出现16行
以下结果在节点2可以分别查询到4,4或8行,4行数据是21,22,23,24,分布式表有时出现4行和有时出现8行
以下结果在节点3可以分别查询到4,8或16行,4行数据是31,32,33,34,分布式表有时出现8行和有时出现16行
以下结果在节点4可以分别查询到0,4或12行,分布式表有时出现4行和有时出现12行
select * from lukestest1.table_mergetree3;
select * from lukestest1.table_Distributed_mergetree3;
额外的实验2,ENGINE = Distributed和ENGINE = ReplicatedMergeTree(),数据只插入节点1和节点2,或数据只插入节点1和节点3,或数据只插入节点1
数据只插入节点1和节点2
CREATE TABLE lukestest1.table_ReplicatedMergeTree3 ON CLUSTER cluster_2shared2replicas(id String,create_time datetime) ENGINE = ReplicatedMergeTree() PARTITION BY toYYYYMM(create_time) ORDER BY id;
--节点1执行
CREATE TABLE lukestest1.table_Distributed_ReplicatedMergeTree3 ON CLUSTER cluster_2shared2replicas(id String,create_time datetime) ENGINE = Distributed(cluster_2shared2replicas, lukestest1, table_ReplicatedMergeTree3,rand());
--节点1执行
insert into lukestest1.table_ReplicatedMergeTree3 (id ,create_time) values ('1','2020-11-17'),('2','2020-11-17'),('3','2020-11-17'),('4','2020-11-17');
--节点1执行
insert into lukestest1.table_ReplicatedMergeTree3 (id ,create_time) values ('21','2020-11-17'),('22','2020-11-17'),('23','2020-11-17'),('24','2020-11-17');
--节点2执行
以下结果在节点1可以分别查询到8,8行,第一个8行数据与节点2数据一致,第二个8行数据和其他节点一致
以下结果在节点2可以分别查询到8,8行,第一个8行数据与节点1数据一致,第二个8行数据和其他节点一致
以下结果在节点3可以分别查询到0,8行,8行数据和其他节点一致
以下结果在节点4可以分别查询到0,8行,8行数据和其他节点一致
select * from lukestest1.table_ReplicatedMergeTree3;
select * from lukestest1.table_Distributed_ReplicatedMergeTree3;
数据只插入节点1和节点3
insert into lukestest1.table_ReplicatedMergeTree3 (id ,create_time) values ('11','2020-11-17'),('12','2020-11-17'),('13','2020-11-17'),('14','2020-11-17');
--节点1执行
insert into lukestest1.table_ReplicatedMergeTree3 (id ,create_time) values ('31','2020-11-17'),('32','2020-11-17'),('33','2020-11-17'),('34','2020-11-17');
--节点3执行
以下结果在节点1可以分别查询到12,16行,12行数据与节点2数据一致,16行数据和其他节点一致
以下结果在节点2可以分别查询到12,16行,12行数据与节点1数据一致,16行数据和其他节点一致
以下结果在节点3可以分别查询到4,16行,4行数据与节点4数据一致,16行数据和其他节点一致
以下结果在节点4可以分别查询到4,16行,4行数据与节点3数据一致,16行数据和其他节点一致
select * from lukestest1.table_ReplicatedMergeTree3;
select * from lukestest1.table_Distributed_ReplicatedMergeTree3;
数据只插入节点1
insert into lukestest1.table_ReplicatedMergeTree3 (id ,create_time) values ('111','2020-11-17'),('112','2020-11-17'),('113','2020-11-17'),('114','2020-11-17');
--节点1执行
以下结果在节点1可以分别查询到16,20行,16行数据与节点2数据一致,20行数据和其他节点一致
以下结果在节点2可以分别查询到16,20行,16行数据与节点1数据一致,20行数据和其他节点一致
以下结果在节点3可以分别查询到4,20行,4行数据与节点4数据一致,20行数据和其他节点一致
以下结果在节点4可以分别查询到4,20行,4行数据与节点3数据一致,20行数据和其他节点一致
select * from lukestest1.table_ReplicatedMergeTree3;
select * from lukestest1.table_Distributed_ReplicatedMergeTree3;
额外的实验3
节点1执行
CREATE TABLE lukestest1.table41 ON CLUSTER cluster_2shared2replicas(id String,create_time datetime) ENGINE = ReplicatedMergeTree() PARTITION BY toYYYYMM(create_time) ORDER BY id;
CREATE TABLE lukestest1.table41_all ON CLUSTER cluster_2shared2replicas(id String,create_time datetime) ENGINE = Distributed(cluster_2shared2replicas, lukestest1, table41,rand());
insert into lukestest1.table41_all (id ,create_time) values ('1','2020-11-17'),('2','2020-11-17'),('3','2020-11-17'),('4','2020-11-17'),('5','2020-11-17'),('6','2020-11-17'),('7','2020-11-17'),('8','2020-11-17'),('9','2020-11-17'),('10','2020-11-17'),('11','2020-11-17');
table4_all在四个节点的数据一致
table4在节点1、2数据一致,table4在节点3、4一致,shard1的数据落在节点1、2上,shard2的数据落在节点3、4上,节点1(或节点2)+节点3(或节点4)的数据刚好等于table4_all
额外的实验4
节点1执行
CREATE TABLE lukestest1.table51 ON CLUSTER cluster_2shared2replicas(id String,create_time datetime) ENGINE = ReplicatedMergeTree() PARTITION BY toYYYYMM(create_time) ORDER BY id;
insert into lukestest1.table51 (id ,create_time) values ('1','2020-11-17'),('2','2020-11-17'),('3','2020-11-17'),('4','2020-11-17'),('5','2020-11-17'),('6','2020-11-17'),('7','2020-11-17'),('8','2020-11-17'),('9','2020-11-17'),('10','2020-11-17'),('11','2020-11-17');
只有节点1、2有数据且数据一致且是全量数据,因为节点1和节点2互为对方副本,节点3、4该表存在但是都没有数据
Merge引擎
https://clickhouse.com/docs/zh/engines/table-engines/special/merge
Merge引擎跟MergeTree引擎不是同一个概念不要混淆两者, Merge引擎本身不存储数据,但可用于同时从任意多个其他的表中读取数据。 读是自动并行的,不支持写入。读取时,那些被真正读取到数据的表的索引(如果有的话)会被使用。
Merge 引擎的参数:一个数据库名和一个用于匹配表名的正则表达式。
示例:Merge(hits, ‘^WatchLog’)表示数据会从 hits 数据库中表名匹配正则 ‘^WatchLog’ 的表中读取。
CREATE TABLE lukestest1.table_mergetest1 (id String,create_time datetime) ENGINE = MergeTree() ORDER BY id;
insert into lukestest1.table_mergetest1 (id ,create_time) values ('1','2020-11-17'),('11','2020-11-17');
CREATE TABLE lukestest1.table_mergetest12 (id String,create_time datetime) ENGINE = MergeTree() ORDER BY id;
insert into lukestest1.table_mergetest12 (id ,create_time) values ('12','2020-11-17'),('122','2020-11-17');
CREATE TABLE lukestest1.table_mergetest23 (id String,create_time datetime) ENGINE = MergeTree() ORDER BY id;
insert into lukestest1.table_mergetest23 (id ,create_time) values ('23','2020-11-17'),('233','2020-11-17');
CREATE TABLE lukestest1.table_mergetest1_Merge ENGINE=Merge(lukestest1, '^table_mergetest1');
select * from lukestest1.table_mergetest1_Merge;
--看到lukestest1.table_mergetest1和table_mergetest12两表的数据
CREATE TABLE lukestest1.table_mergetest2_Merge ENGINE=Merge(lukestest1, '^table_mergetest2');
select * from lukestest1.table_mergetest2_Merge;
--只看到lukestest1.table_mergetest23表的数据
MaterializedView 引擎
https://clickhouse.com/docs/zh/engines/table-engines/special/materializedview
https://clickhouse.com/docs/zh/sql–reference/statements/create/view
它需要使用一个不同的引擎来存储数据,这个引擎要在创建物化视图时指定。当从表中读取时,它就会使用该引擎。
CREATE MATERIALIZED VIEW [IF NOT EXISTS] [db.]table_name [ON CLUSTER] [TO[db.]name] [ENGINE = engine] [POPULATE] AS SELECT …
创建不带TO [db].[table]的物化视图时,必须指定ENGINE – 用于存储数据的表引擎。
使用TO [db].[table] 创建物化视图时,不得使用POPULATE。
ClickHouse 中的物化视图更像是插入触发器。 如果视图查询中有一些聚合,则它仅应用于一批新插入的数据。 对源表现有数据的任何更改(如更新、删除、删除分区等)都不会更改物化视图。
物化视图是查询结果的持久化,可以理解为一张时刻在与计算的表,创建过程中用了一个特殊引擎。但是对更新、删除 操作支持并不好,更像是个插入触发器。
如果指定POPULATE,则在创建视图时将现有表数据插入到视图中,就像创建一个CREATE TABLE … AS SELECT …一样。 否则,查询仅包含创建视图后插入表中的数据。 我们不建议使用POPULATE,因为在创建视图期间插入表中的数据不会插入其中。
创建MaterializedView时必须指定engine,且这个engine的格式和创建表时一样,比如使用engine=MergeTree() 后面必须加order by 这些。
CREATE TABLE lukestest1.table_mergetest2 (id String,create_time datetime) ENGINE = MergeTree() ORDER BY id;
insert into lukestest1.table_mergetest2 (id ,create_time) values ('11','2020-11-17'),('12','2020-11-17'),('13','2020-11-17'),('21','2020-11-17'),('22','2020-11-17'),('23','2020-11-17');
create materialized view lukestest1.table_mergetest2_materialized engine=MergeTree() POPULATE as select * from lukestest1.table_mergetest2 where id like '%2%';--报错DB::Exception: ORDER BY or PRIMARY KEY clause is missing. Consider using extended storage definition syntax with ORDER BY or PRIMARY KEY clause. With deprecated old syntax (highly not recommended) storage MergeTree requires 3 to 4 parameters:
create materialized view lukestest1.table_mergetest2_materialized engine=MergeTree() order by id POPULATE as select * from lukestest1.table_mergetest2 where id like '%2%' ;
create materialized view lukestest1.table_mergetest2_materialized_nopopulate engine=MergeTree() order by id as select * from lukestest1.table_mergetest2 where id like '%2%';
select * from lukestest1.table_mergetest2_materialized;
--有四条数据
select * from lukestest1.table_mergetest2_materialized_nopopulate;
--没有数据
insert into lukestest1.table_mergetest2 (id ,create_time) values ('222','2020-11-17'),('223','2020-11-17'),('224','2020-11-17');
select * from lukestest1.table_mergetest2_materialized;
--有7条数据
select * from lukestest1.table_mergetest2_materialized_nopopulate;
--有三条数据
原文地址:https://blog.csdn.net/lusklusklusk/article/details/134744308
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_27026.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!