本文介绍: 相比较map–reduce框架,spark的框架执行效率更加高效。mapreduce的执行框架示意图。spark执行框架示意图spark的执行中间结果是存储在内存当中的,而hdfs的执行中间结果是存储在hdfs中的。所以在运算的时候,spark的执行效率是reduce的3-5倍。
一:为什么学习spark?
相比较map–reduce框架,spark的框架执行效率更加高效。
mapreduce的执行框架示意图。
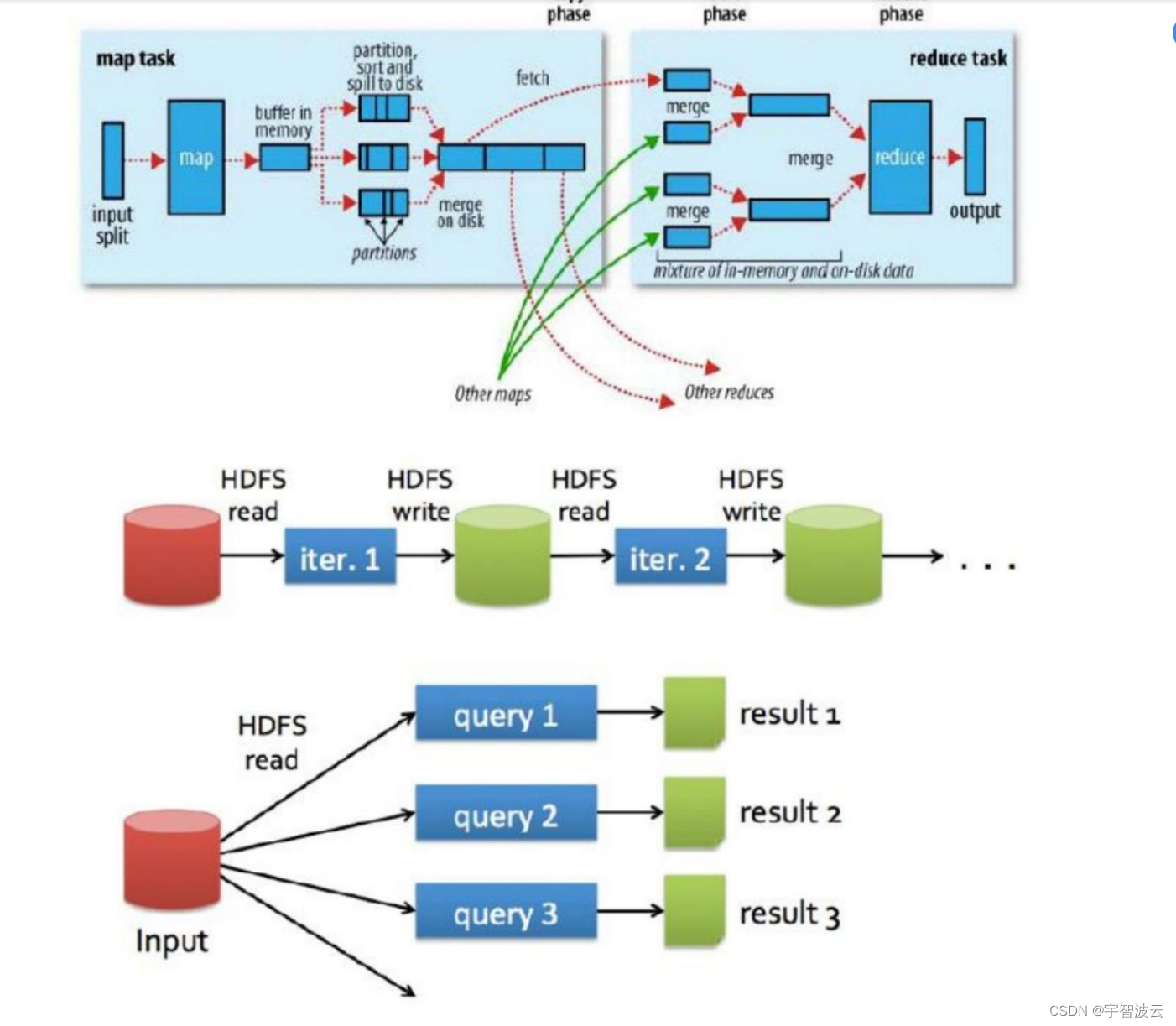
spark执行框架示意图
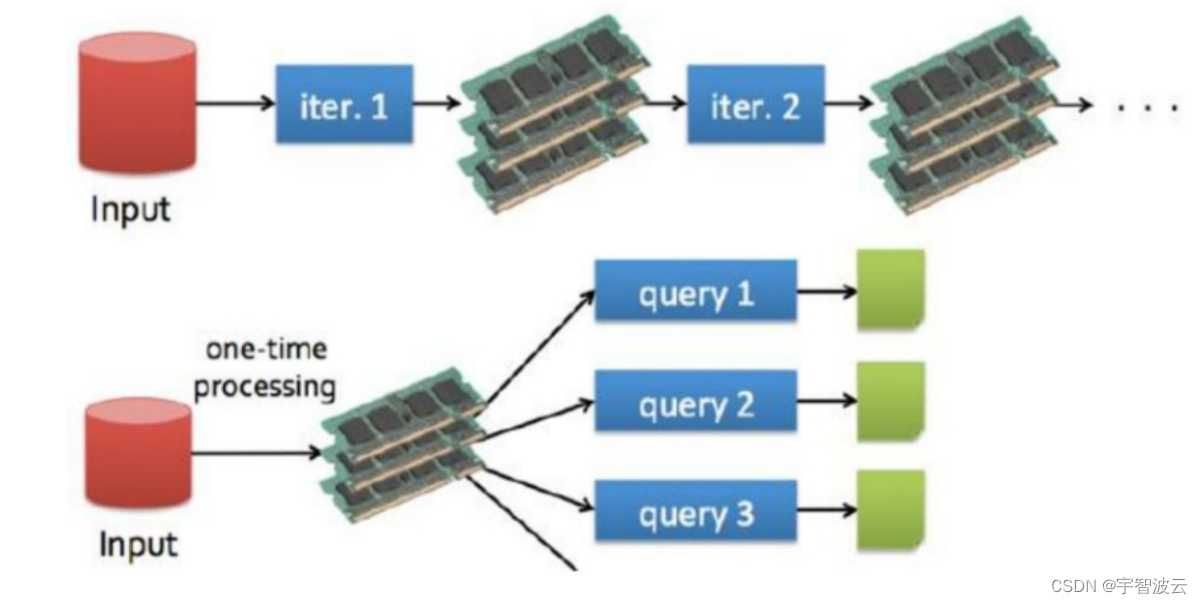
spark的执行中间结果是存储在内存当中的,而hdfs的执行中间结果是存储在hdfs中的。所以在运算的时候,spark的执行效率是reduce的3-5倍。
二:spark是什么?
三:spark包含哪些内容?
1. spark core。
1. RDD是由一系列partition组成的。
每个rdd中,partition的个数和由hdfs中的map的个数决定的。和map的个数保持一致。
2. 每个RDD会提供最佳的计算位置。
3. 每个函数会作用在每个partition上。
算子
4. RDD之间相互依赖。
RDD的宽窄依赖。
一对一的就是窄依赖。
一对多的就是宽依赖。
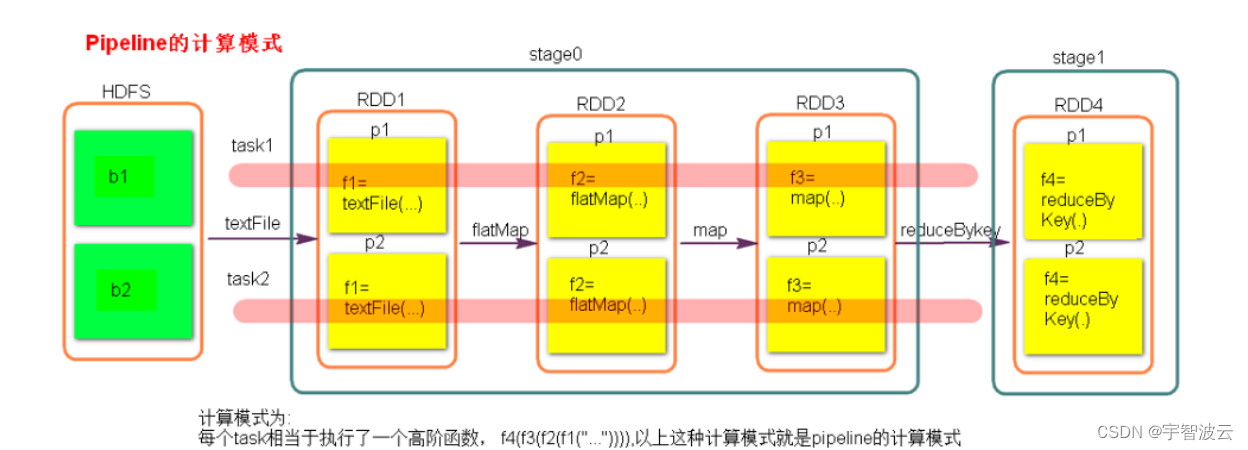
在计算进行切割的时候,会将所有的窄依赖放在一起,成为一个stage。放在一个TaskScheduler中进行计算。
5. 分区器是作用在 (K,V) 格式的 RDD 上。
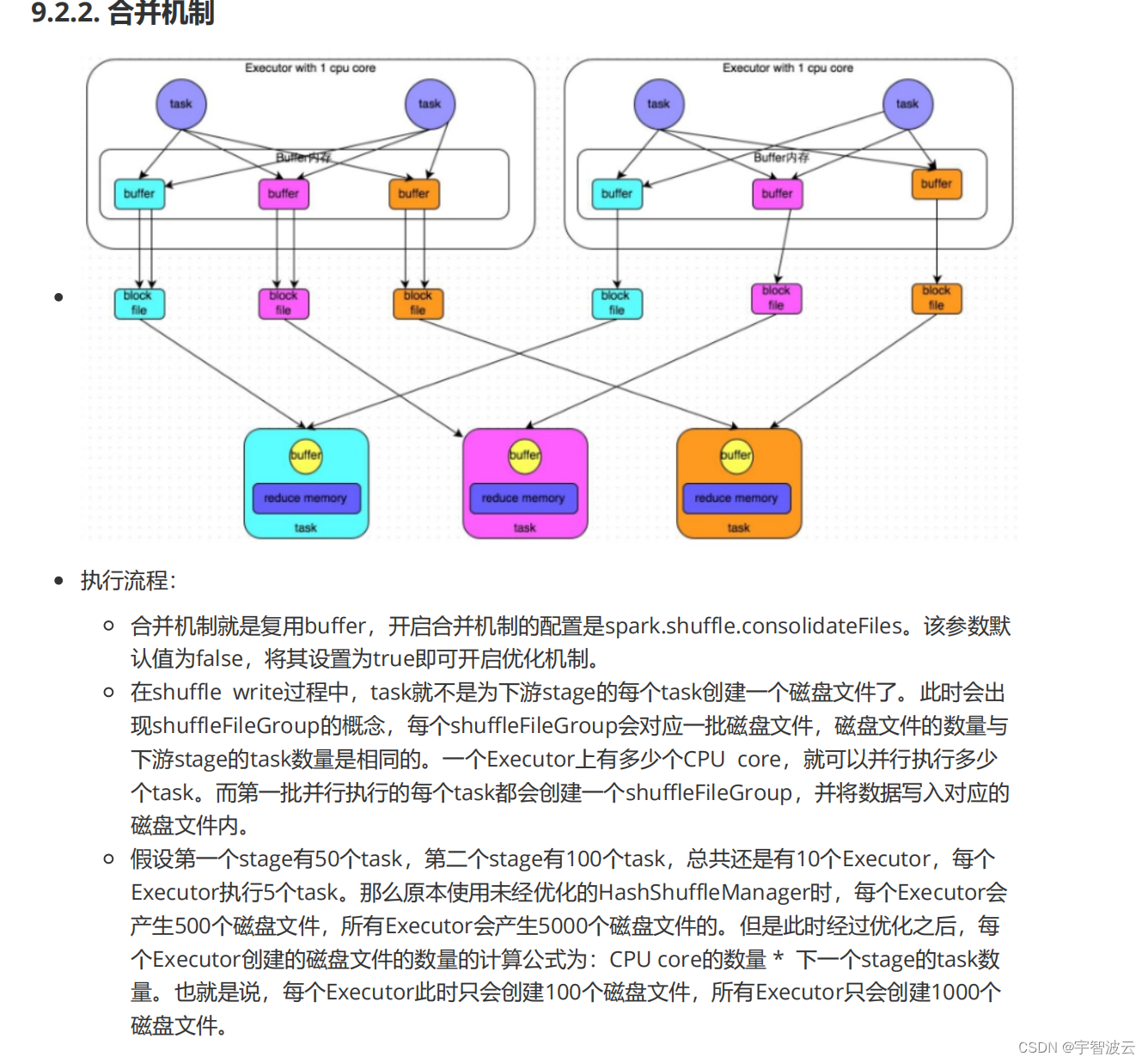
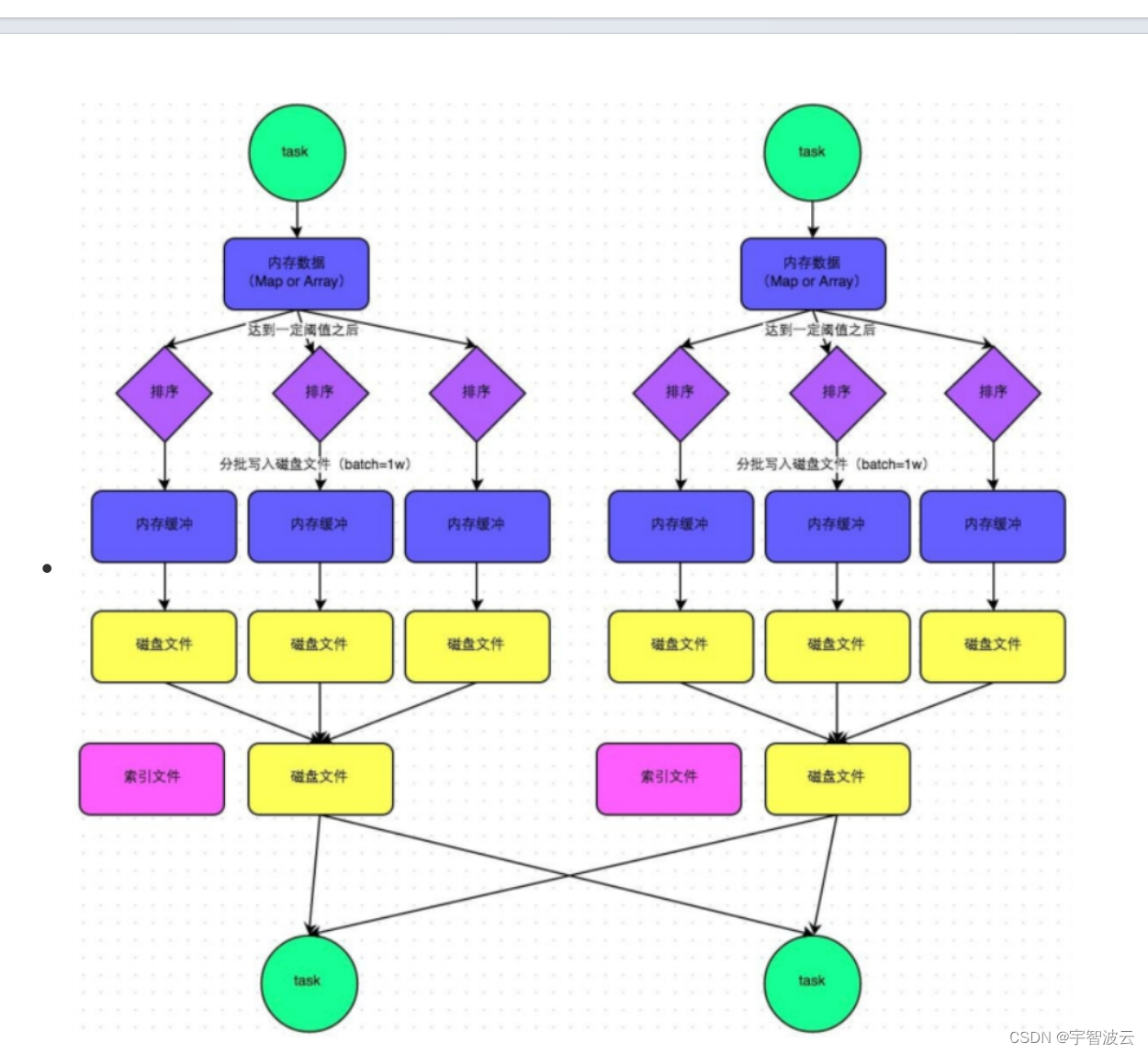



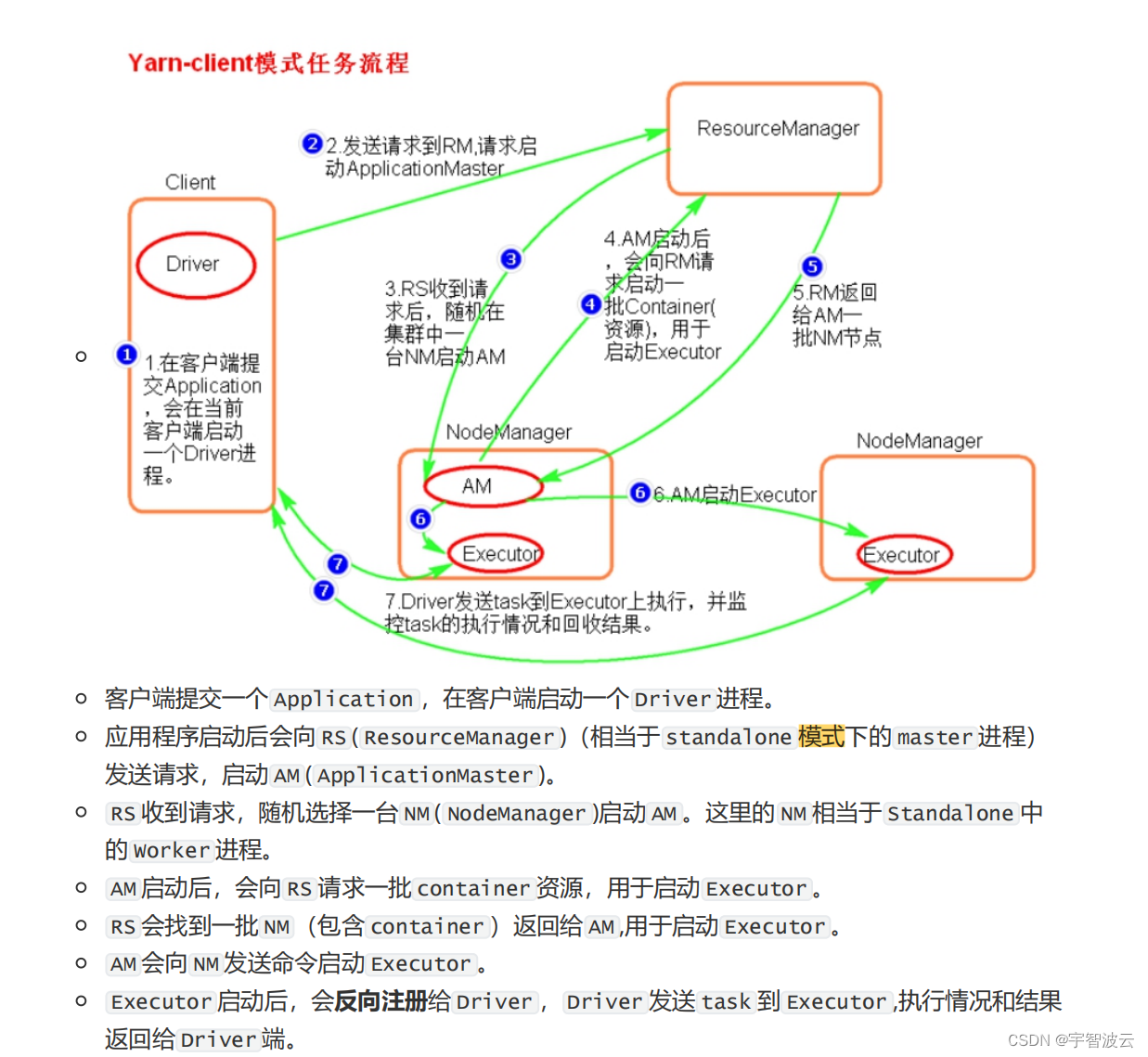
2. spark的俩种提交模式。
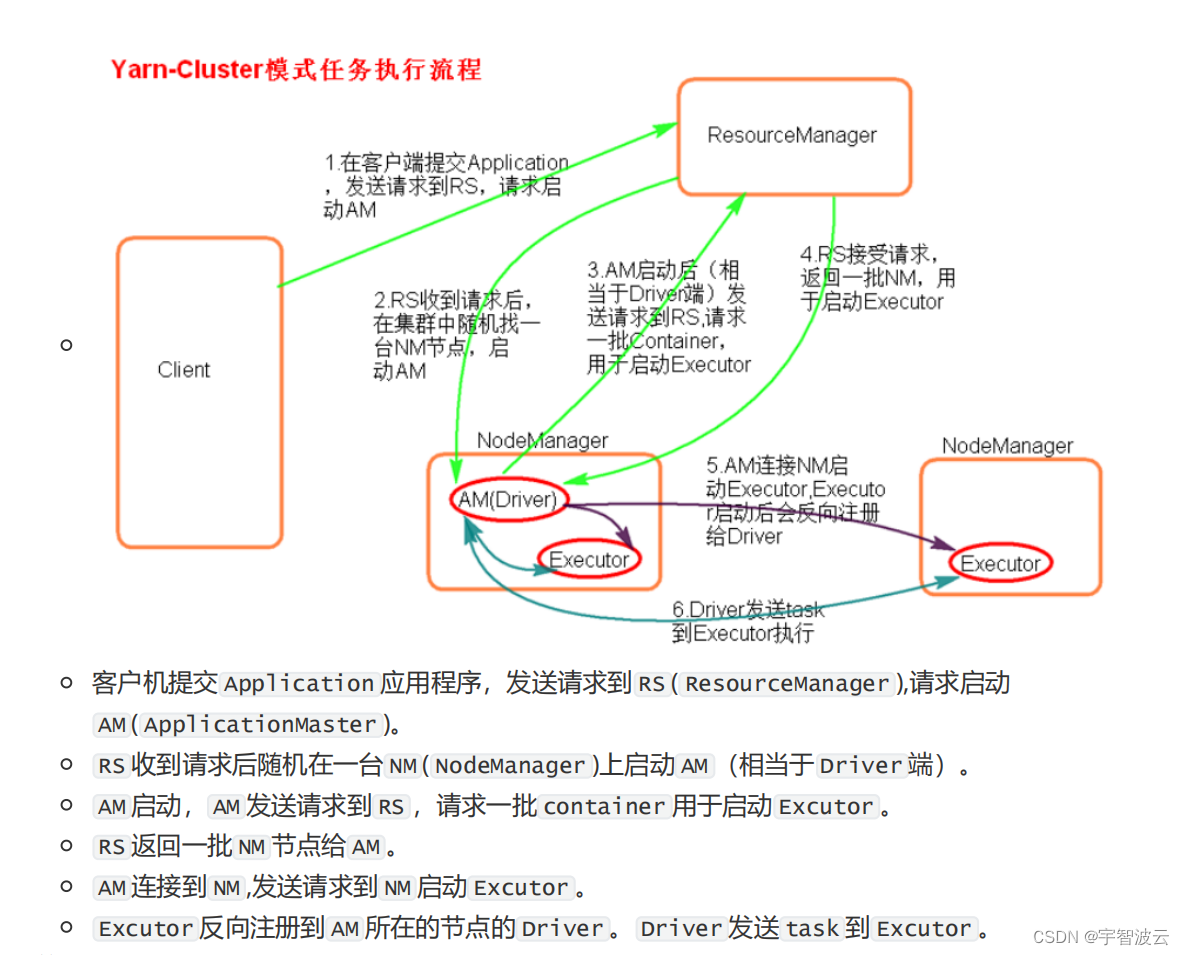

2. spark sql。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。