以往 OpenSearch 摄入时的一些最佳实践中并不包含 knn 的情况,所以在 knn 索引存在的情况,不能完全参照之前的结论,通过以上三种不同的实验方式,在多次实验的过程中,本文得到了以下的一些实践经验和结论,供参考:
a. CPU 利用率和参数 ef_construction 与 m 明显正相关,在实验中使用较大的 ef_construction 和 m 时,CPU 很容易达到 100%。实验中,在其他参数相同的情况下,ef_construction 为 512 时,CPU 利用率会长期保持在 100%,改为 2 时,利用率基本在 20% 以下,峰值不超过 30%。
b. 客户端并行数量与 OpenSearch 的摄入速度和负载成正相关,但并不是线性相关。多客户端能提高摄入速度,但是客户端数量过多,可能会导致大量的(429, ‘429 Too Many Requests /_bulk’)和(503, “No server available to handle the request..”)等错误。
c. 指数退避重试机制能保证摄入的完整性以及因集群瞬时不可用导致的大面积写入失败,opensearch–py包中有如下摄入函数, 如果并发客户端过多,可能会导致CPU利用率一直位于100%,在max_retries的重试次数内,每次会等待 initial_backoff * (attampt_idx ** 2)的时间,通过设定一个较大的initial_backoff等待时间,能避免在客户端并发数偏大的情况下出现大面积429错误。另外客户端数也不能过大,否则也会更容易出现大量的503相关错误。对于偶发的503报错,可以利用 glue 的 retry 机制处理,保证写入的完整性。

注意:在大规模向量数据库数据摄入的生产场景中,不建议使用LangChain提供的向量数据库接口,查看其源码可知,LangChain的默认实现是单客户端,且其内部实现没有使用指数退避Retry机制,无法保证摄入速度和完整性。
d. 写入完成后,建议查询文档的去重数量,确保写入的完整性。可以在 OpenSearch Dashboard 的 Dev tools 中使用如下的 DSL 语句查询文档总数。注意 cardinality 方式的统计不是精准统计值,可以提高 precision_threshold 参数值来提高其准确性。

同时可以按照文档名统计对应的 chunk 数量,可以帮助发现潜在文档处理向量数据库质量问题,参考下面代码:

e. refresh_interval 设置为 -1,在其他相关参数的相同的情况下,503 报错明显增加。更改为 60s 后,情况有明显好转, 如果发生类似问题,可以做类似的调整。
数据注入完毕以后,直接查询性能是十分差的,查询时延可能在几秒甚至十几秒。需要进行一些必要的优化。核心的主要有两点:
Segment 是 OpenSearch 中的最小搜索单元。如果每个 shard 只有 1 个 segment,搜索效率将达到最高。为了实现这个目标,我们可以通过控制 refresh interval 来降低小 segment 的生成速度,或者手动进行 segment merge。这将有助于减少搜索过程中的开销,提高搜索速度。
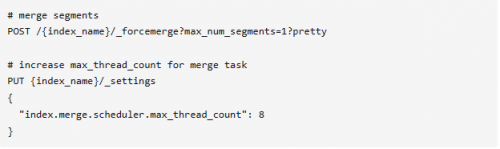
可以在 OpenSearch Dashboard 的 Dev tools 中通过如下的 DSL 执行合并,整个合并过程比较长,执行之前可以调高用于合并的线程最大值,能够提高向量数据库合并的速度。
![]()
合并前后可以执行如下 DSL 来检查当前的 segments 情况:
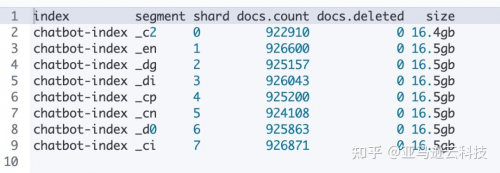
GET _cat/segments/{index_name}?v&h=index,segment,shard,docs.count,docs.deleted,size
以下表格是合并 segments 后的情况,合并完成后每个 shard 下仅有一个 segment,数据也均匀分布,标记删除的向量数据库数据也被清理掉了。
由于向量数据库 k-NN 索引的性能与索引数据结构是否缓存到内存中密切相关,能够提供的缓存内容容量对性能影响很大。可以执行以下 DSL 命令,对 k-NN 索引进行预热
![]()
GET /_plugins/_knn/warmup/{index_name}?pretty
预热执行很快,预热完毕以后,性能会有明显改善。可以到 CloudWatch 中去查看 OpenSearch Domain 中的 KNNGraphMemoryUsagePercentage 指标进行确认是否执行完毕,如图所示:
本文在本系列上篇博客的基础上,通过一个真实数据场景的实践进行更详细的阐述,讨论的重点更多放在针对大规模的文档、更快更完整地构建基于向量数据库的知识库上面,这对于一些行业如金融、法律、医疗等行业向量数据库的知识库的构建具备指导借鉴意义。
本文的第一部分对于 Amazon OpenSearch 向量数据库的集群配置选择给出了一些方法参考,第二三四部分对于数据摄入和检索性能等方面给出了一些初步的经验总结。
原文地址:https://blog.csdn.net/MJ13125007893/article/details/134728550
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_27306.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!