Kafka是一个分布式流式处理平台。很多分布式处理系统,例如Spark,Flink等都支持与Kafka集成。
Kafka使用场景
架构设计
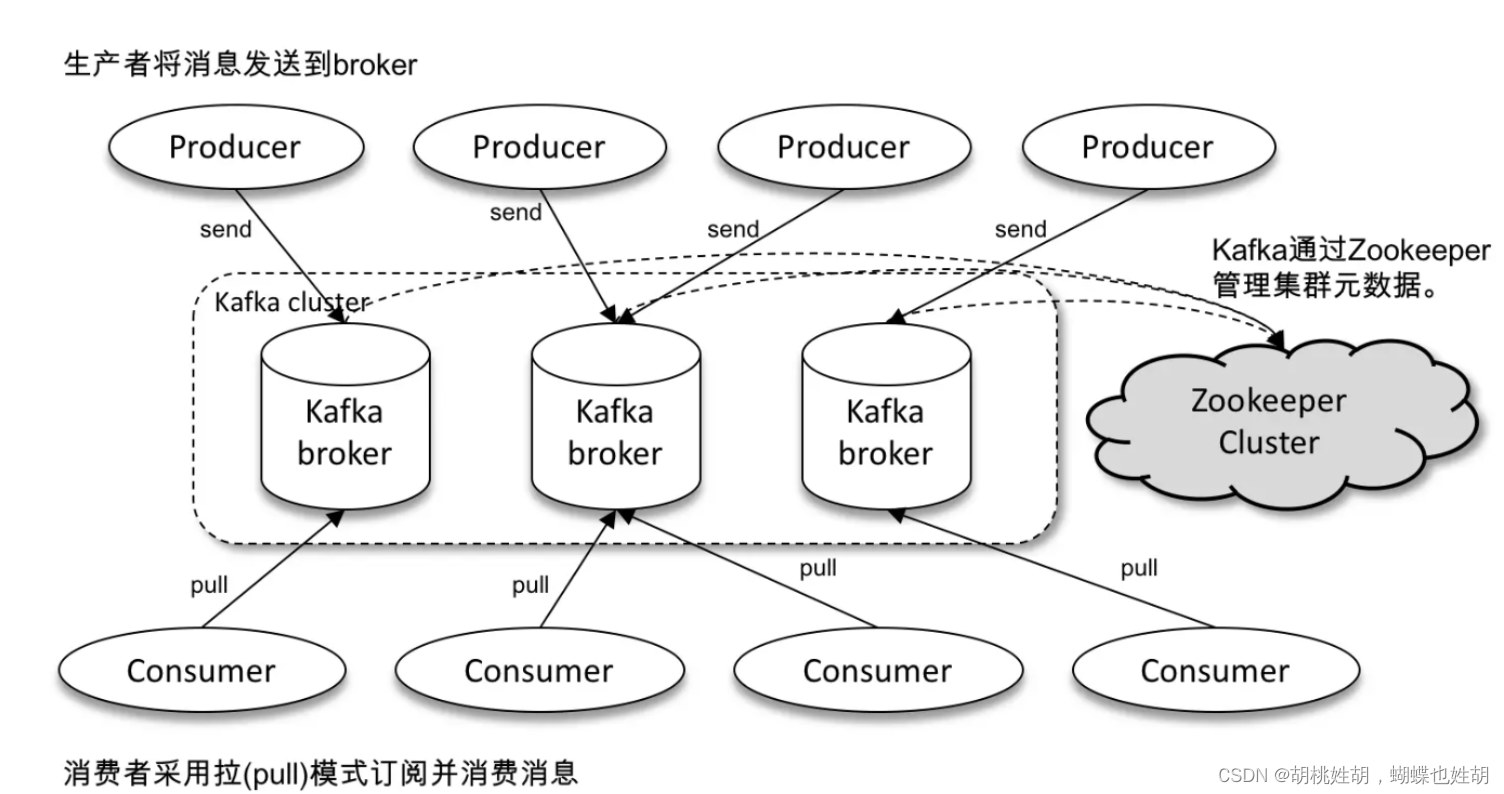
其中 ZooKeeper 是 Kafka 用来负责集群元数据的管理、控制器的选举等操作的。Producer 将消息发送到 Broker,Broker 负责将收到的消息存储到磁盘中,而 Consumer 负责从 Broker 订阅并消费消息。
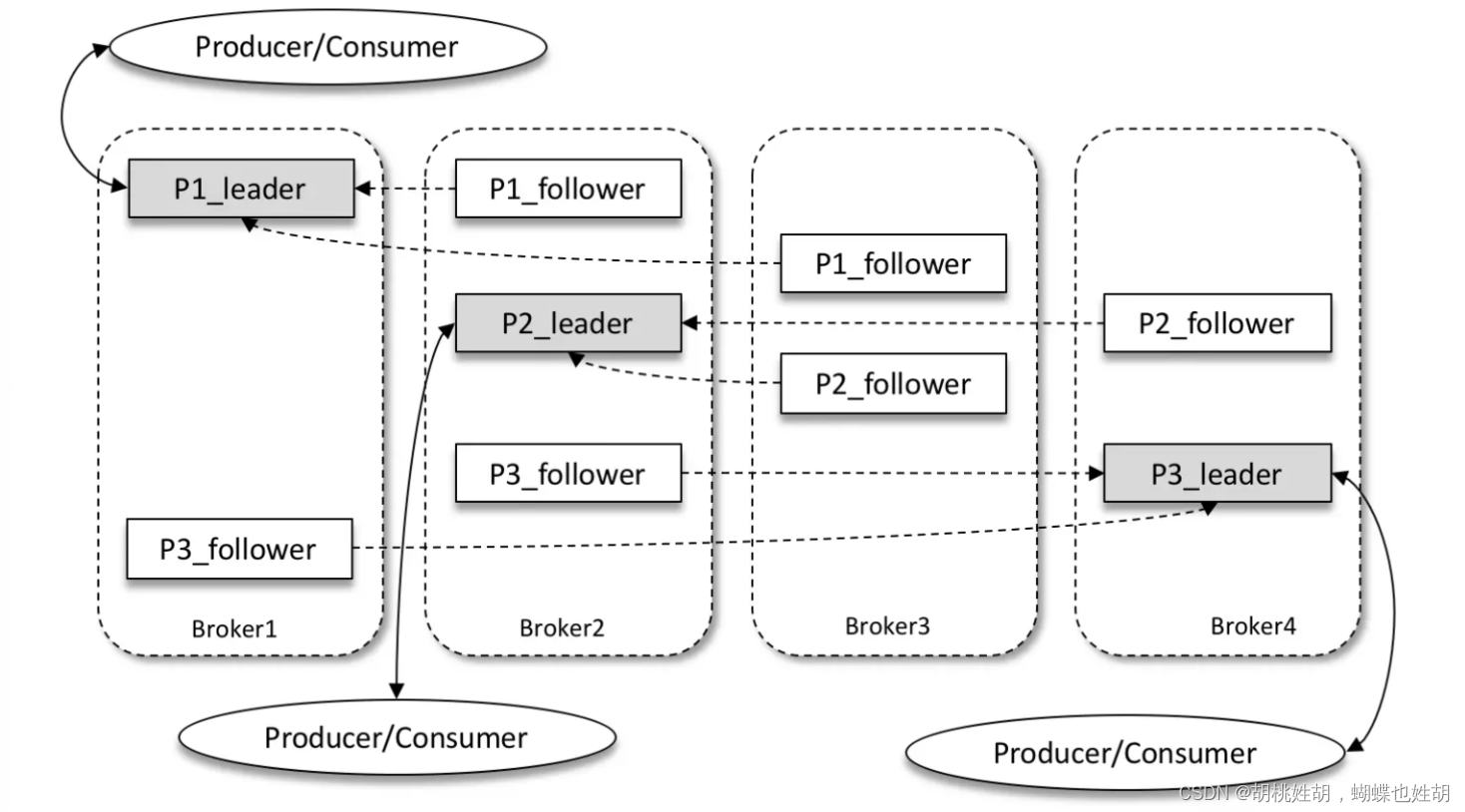
这里详细介绍一下Broker这个概念:服务代理节点。对于kafka而言,Broker可以简单地看作一个独立的Kafka服务节点或者Kafka服务实例。大多数情况下也可以将Broker看作一台Kafka服务器,前提是这台服务器上只部署了一个Kafka实例。一个或者多个Broker组成了一个Kafka集群。一般而言你我们更习惯使用首字母小写的broker来表示服务代理节点。
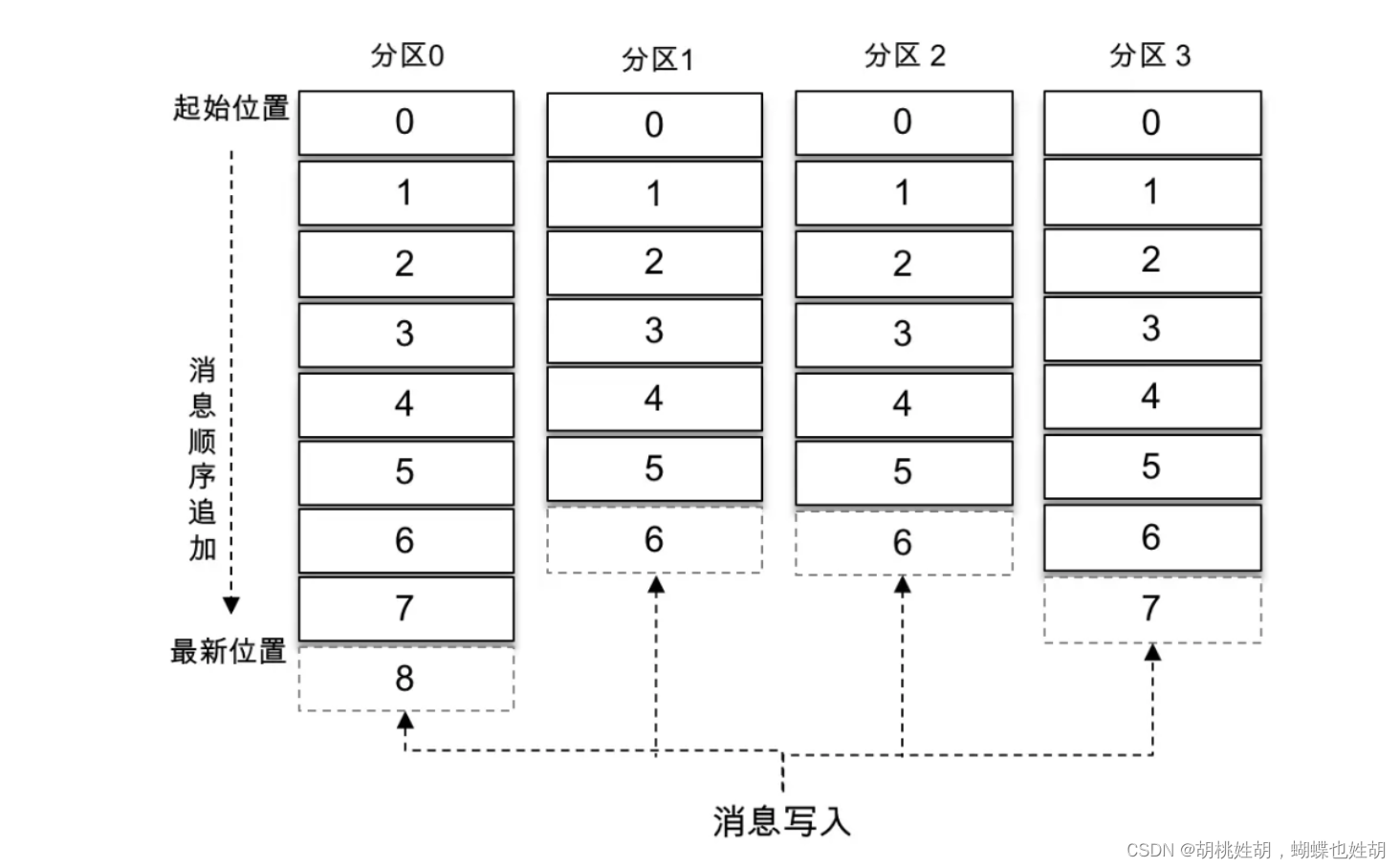
在Kafka中还有两个特别重要的概念 – 主题(Topic)与分区(Partition)。Kafka中的消息以主题为单位进行归类,生产者负责将消息发送到特定的主题(发送到Kafka集群中的每一条消息都要指定一个主题),而消费者负责订阅主题并且进行消费。
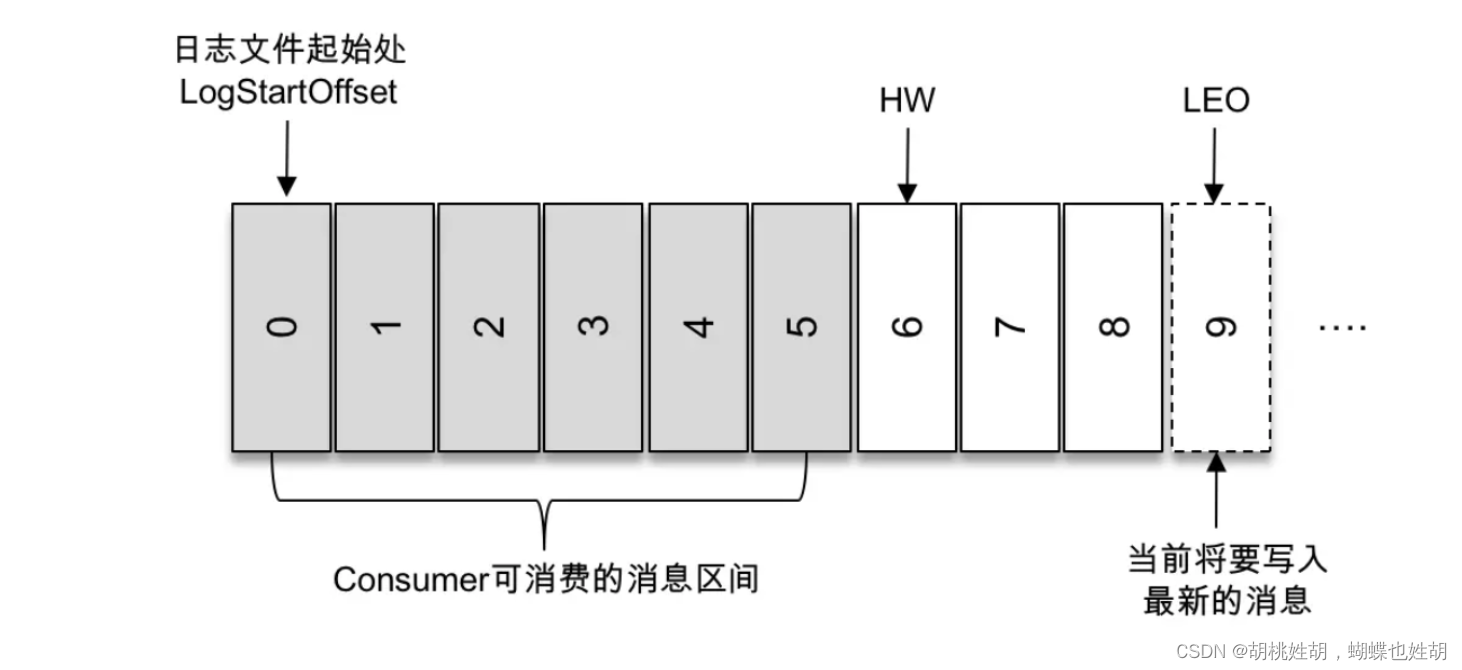
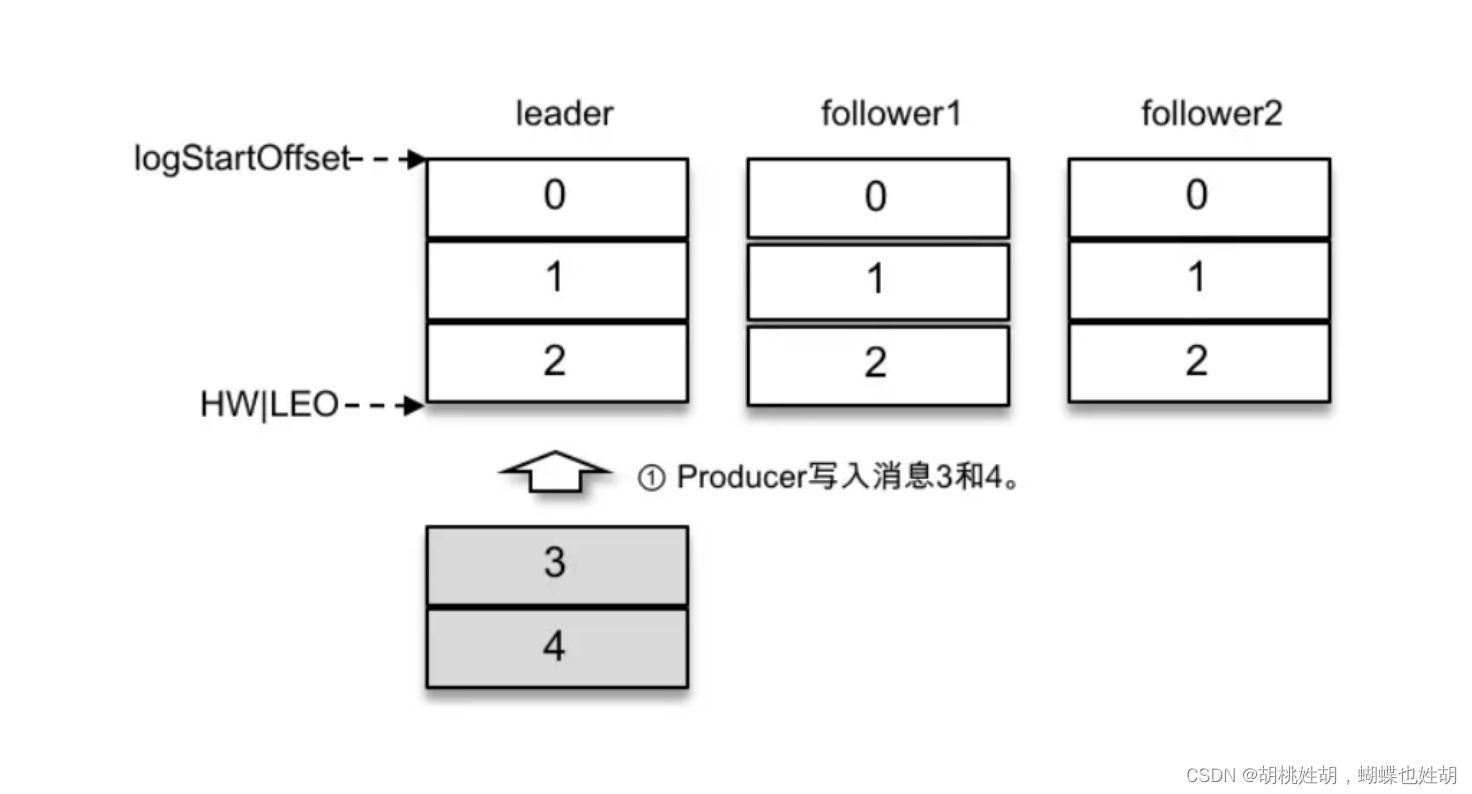
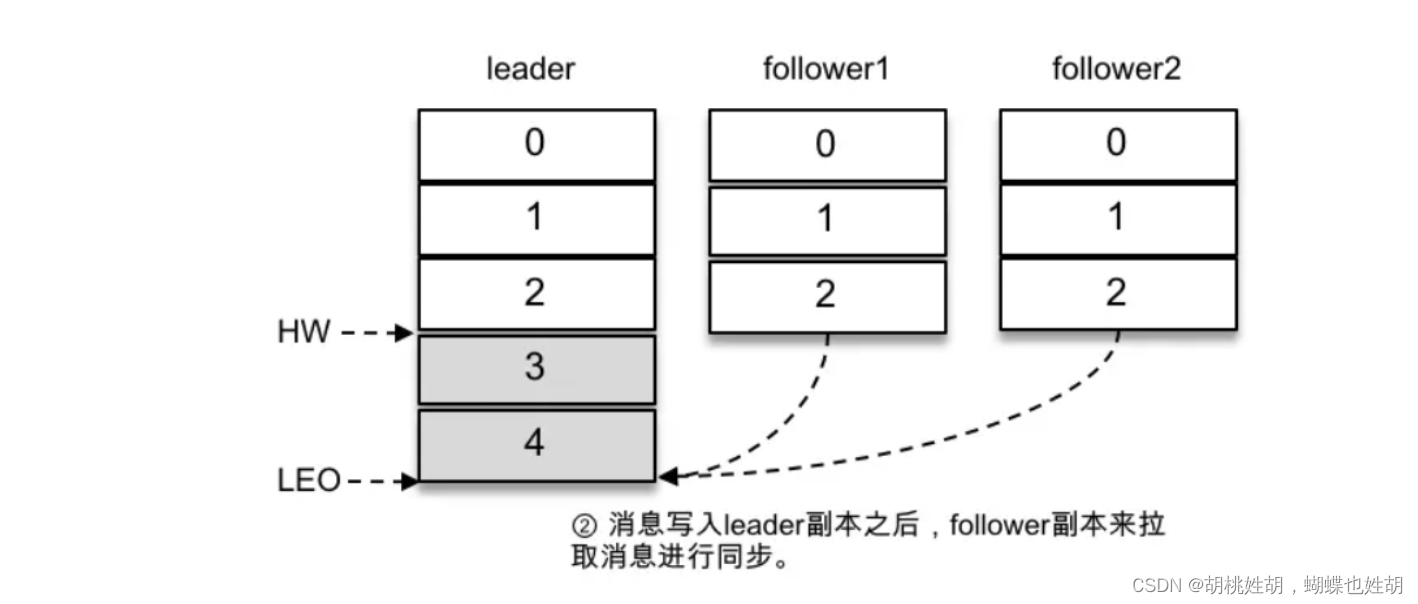
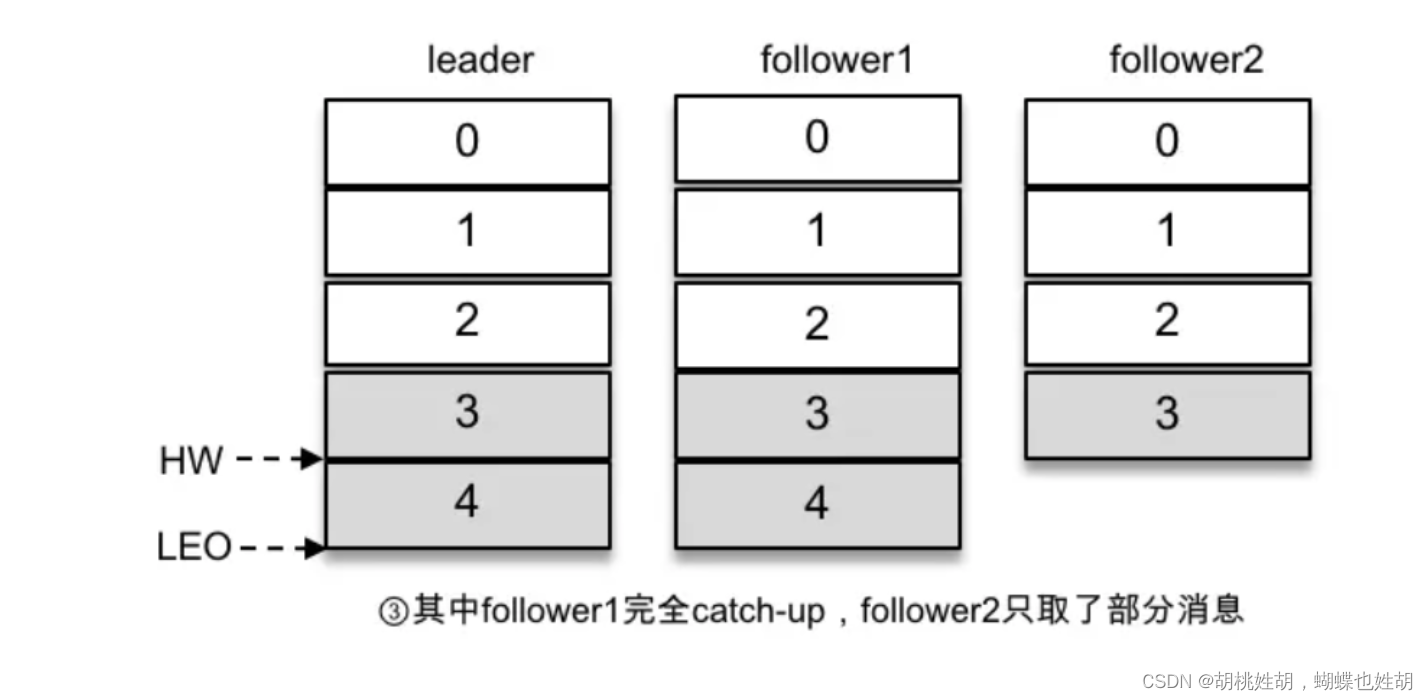
主题是一个逻辑上的概念,它还可以细分成多个分区,一个分区只属于单个主题,很多时候也会把分区称之为主题分区(Topic-Partion)。同一个主题下的不同分区包含的消息是不同的,分区在存储层可以看作一个可追加的日志(Log)文件,消息在被追加到分区日志文件的时候都会分配一个特定的偏移量(offset)。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。