本文介绍: 本文主要介绍`node`中跟进程相关的三个模块。`process`是`node`的全局模块,作用比较直观。可以通过它来获得`node`进程相关的信息,`child_process`主要用来创建子进程,可以有效解决node单线程效率不高的问题。`cluster`是`node`的集群模块,提供了开箱即用的进程创建功能。
简介
本文主要介绍node中跟进程相关的三个模块。process是node的全局模块,作用比较直观。可以通过它来获得node进程相关的信息,child_process主要用来创建子进程,可以有效解决node单线程效率不高的问题。cluster是node的集群模块,提供了开箱即用的进程创建功能。
process
process.env
process.env为node运行服务的环境变量。里面默认的变量很多,笔者就不一一列举了。
比如我们常用的NODE_ENV,我们执行NODE_ENV=production node process.js
我们还可以传别的参数,比如我们执行aaa=dev node process.js
可以发现,通过key=value这种方式传递的参数就是环境变量。
process.argv
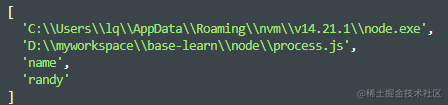
process.execArgv
process.cwd()
process.chdir(directory)
process.config
process.pid
process.title
process.uptime()
process.memoryUsage()
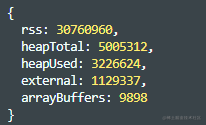
process.version
process.versions

process.execPath
process.arch
process.platform
process.nextTick(fn)

process.stdin、process.stdout、process.stderr
child_process
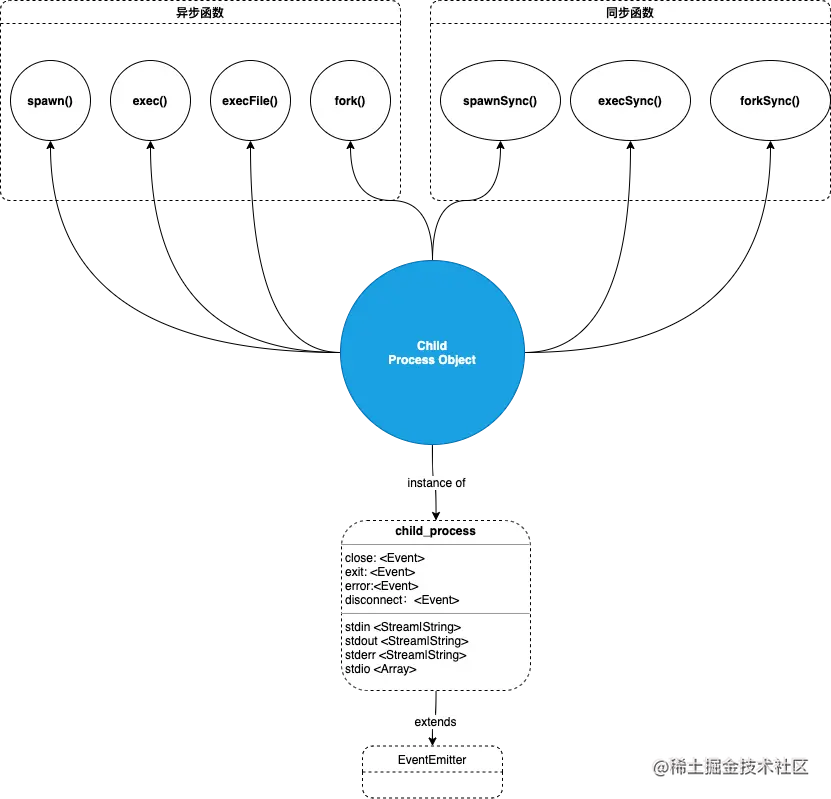
spawn(command,[args],[options])
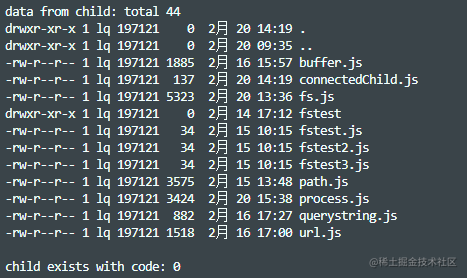
exec(command[, options][, callback])
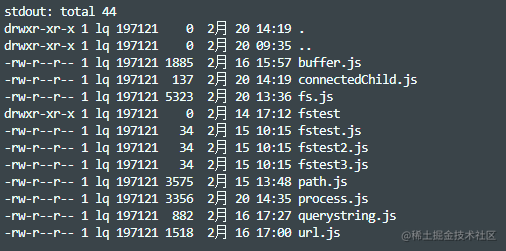
execFile(file[, args][, options][, callback])
fork(modulePath[, args][, options])

总结
cluster
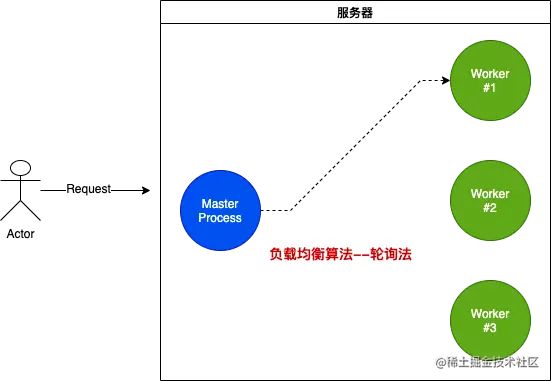
提高服务器的可用性
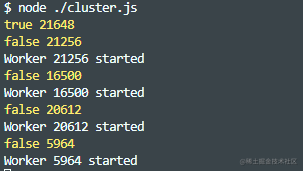
1. master、worker如何通信
2. 如何实现端口共享
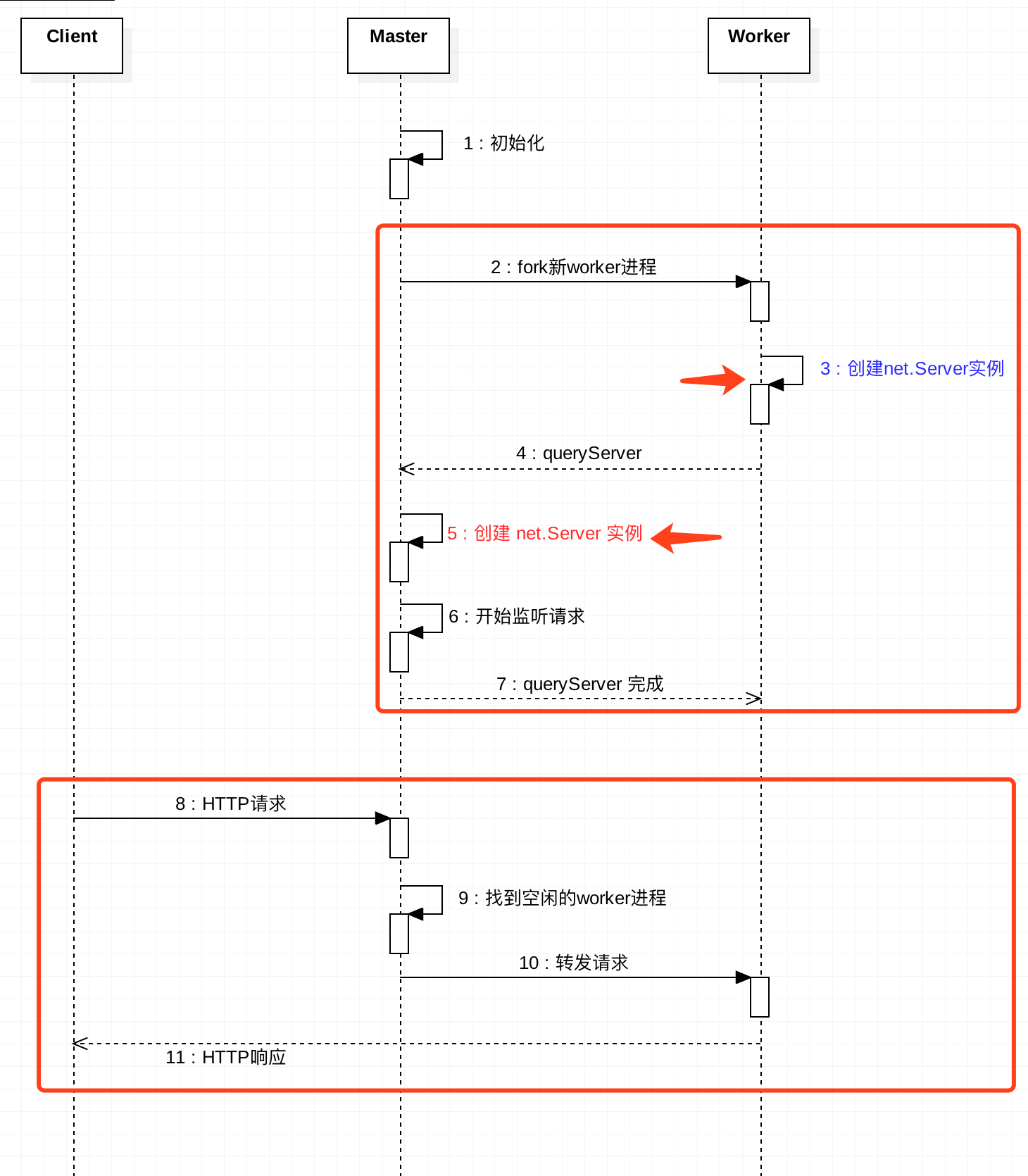
3. 如何将请求分发到多个worker
提高服务器的稳定性
系列文章
后记
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。