本文介绍: 在电子商务上,聚类分析在电子商务中网站建设数据挖掘中也是很重要的一个方面,通过分组聚类出具有相似浏览行为的客户,并分析客户的共同特征,可以更好的帮助电子商务的用户了解自己的客户,向客户提供更合适的服务。当然,这种聚类技术就失去了实际意义,因为聚类的目的是寻找数据集中的有意义的模式,方便用户理解,而任何聚类的数目和数据对象一样多的聚类算法都不能帮助用户更好地理解数据,挖掘数据隐藏的真实含义。因此,聚类就是一些数据实例的集合,这个集合中的元素彼此相似,但是它们都与其他聚类中的元素不同。
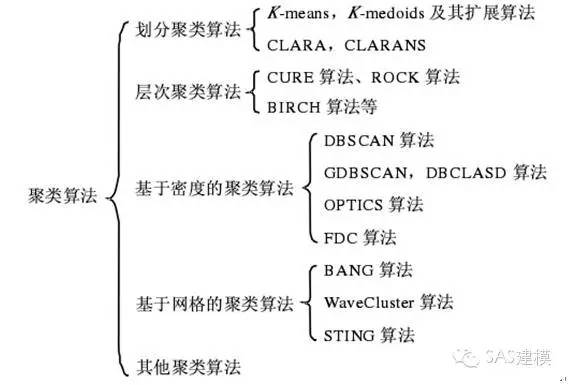
1 聚类分析介绍
聚类就是一种寻找数据之间一种内在结构的技术。聚类把全体数据实例组织成一些相似组,而这些相似组被称作聚类。处于相同聚类中的数据实例彼此相同,处于不同聚类中的实例彼此不同。聚类技术通常又被称为无监督学习,因为与监督学习不同,在聚类中那些表示数据类别的分类或者分组信息是没有的。
通过上述表述,我们可以把聚类定义为将数据集中在某些方面具有相似性的数据成员进行分类组织的过程。因此,聚类就是一些数据实例的集合,这个集合中的元素彼此相似,但是它们都与其他聚类中的元素不同。在聚类的相关文献中,一个数据实例有时又被称为对象,因为现实世界中的一个对象可以用数据实例来描述。同时,它有时也被称作数据点(Data Point),因为我们可以用 维空间的一个点来表示数据实例,其中 表示数据的属性个数。
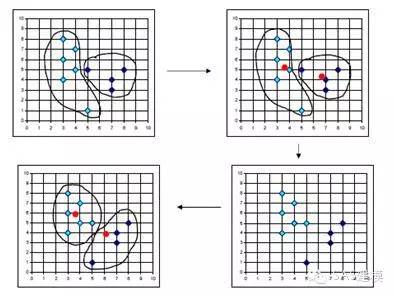
下图显示了一个二维数据集聚类过程,从该图中可以清楚地看到数据聚类过程。虽然通过目测可以十分清晰地发现隐藏在二维或者三维的数据集中的聚类,但是随着数据集维数的不断增加,就很难通过目测来观察甚至是不可能。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。







