1.Java基础篇(阿里、蚂蚁、字节、携程、快手、杭州银行等)
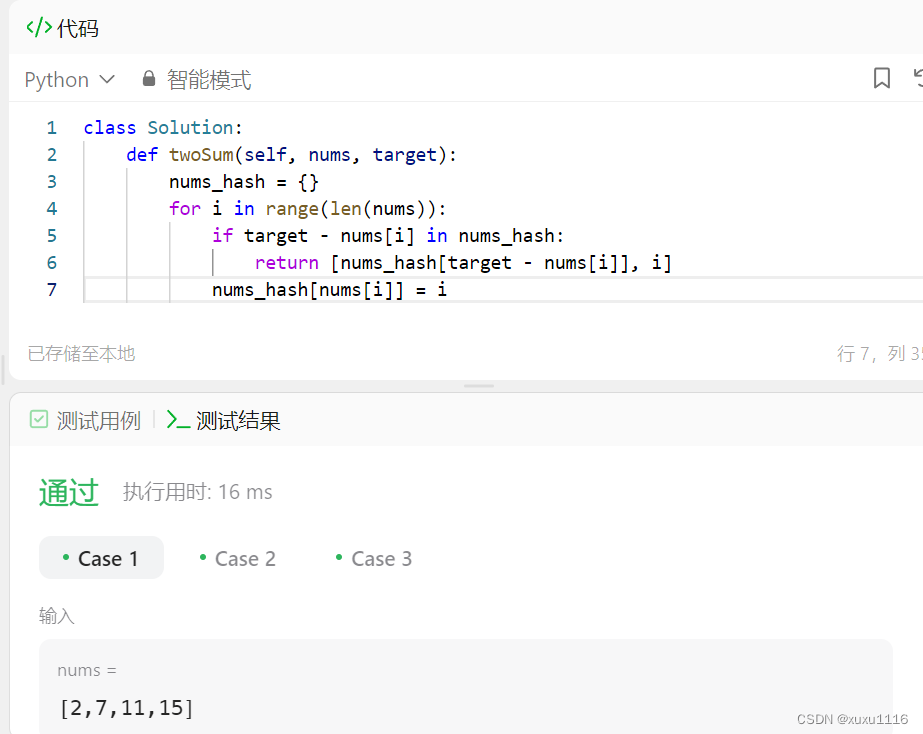
答案:
- 在jdk1.8之前,hashmap由 数组–链表数据结构组成,在jdk1.8之后hashmap由 数组–链表–红黑树数据结构组成;当我们创建hashmap对象的时候,jdk1.8以前会创建一个长度为16的Entry数组,jdk1.8以后就不是初始化对象的时候创建数组了,而是在第一次put元素的时候,创建一个长度为16的Node数组;
- 当我们向对象中插入数据的时候,首先调用hashcode方法计算出key的hash值,然后对数组长度取余((n-1)&hash(key)等价于hash值对数组取余)计算出向Node数组中存储数据的索引值;如果计算出的索引位置处没有数据,则直接将数据存储到数组中;如果计算出的索引位置处已经有数据了,此时会比较两个key的hash值是否相同,如果不相同,那么在此位置划出一个节点来存储该数据(拉链法);如果相同,此时发生hash碰撞,那么底层就会调用equals方法比较两个key的内容是否相同,如果相同,就将后添加的数据的value覆盖之前的value;如果不相同,就继续向下和其他数据的key进行比较,如果都不相等,就划出一个节点存储数据;如果链表长度大于阈值8(链表长度符合泊松分布,而长度为8个命中概率很小),并且数组长度大于64,则将链表变为红黑树,并且当长度小于等于6(不选择7是防止频繁的发生转换)的时候将红黑树退化为链表。
2.并发编程篇(顺丰、大华、字节等)
答案:
- 继承Thread类,只需要创建一个类继承Thread类然后重写run方法,在main方法中调用该类实例对象的start方法
- 实现Runnable接口,只需要创建一个类实现Runnable接口然后重写run方法,在main方法中将该类的实例对象传给Thread类的构造方法,然后调用start方法
- 实现Callable接口,只需要创建一个类实现Callable接口然后重写call方法(有返回值),在main方法中将该类的实例对象传给 Future接口的实现类FutureTask的构造方法,然后再将返回的对象传给Thread类的构造方法,最后调用start方法
- 线程池,首先介绍它的好处,然后再说它可以通过ThreadPoolExecutor类的构造方法来进行创建。
3.JVM篇(阿里、字节、蚂蚁等)
答案:
- 加载:通过一个类的全限定名来获取此类的二进制字节流,然后在内存中生成一个代表这个类的Class对象
- 验证:确保Class文件的字节流中包含的信息符合《java虚拟机规范》的全部约束要求,保证虚拟机的安全
- 准备:为类变量(即静态变量,被staic修饰的变量)赋默认初始值,int为0,long为0L,boolean为false,引用类型为null;常量(被staic final修饰的变量)赋真实值
- 解析:把符号引用翻译为直接引用
- 初始化:执行类构造器()方法,真正初始化类变量和其他资源
- 使用:使用这个类
- 卸载:一般情况下JVM很少会卸载类,如果卸载类需要满足以下三个条件
a. 该类所有的实例都已经被垃圾回收,也就是JVM中不存在该类的任何实例
b. 加载该类的类加载器已经被垃圾回收
c. 该类的Class对象没有在任何地方被引用
4.Hadoop篇(阿里)
问题:MapReduce 中排序发生在哪几个阶段?这些排序是否可以避免?
答案:
- 一个 MapReduce 作业由 Map 阶段和 Reduce 阶段两部分组成,这两阶段会对数据排序,从这个意义上说,MapReduce 框架本质就是一个 Distributed Sort。
- 在 Map 阶段,Map Task 会在本地磁盘输出一个按照 key 排序(采用的是快速排序)的文件(中间可能产生多个文件,但最终会合并成一个),在 Reduce 阶段,每个 Reduce Task 会对收到的数据排序(采用的是归并排序),这样,数据便按照 Key 分成了若干组,之后以组为单位交给 reduce 处理。
- 很多人的误解在 Map 阶段,如果不使用 Combiner 便不会排序,这是错误的,不管你用不用 Combiner,Map Task 均会对产生的数据排序(如果没有 Reduce Task,则不会排序,实际上 Map 阶段的排序就是为了减轻 Reduce端排序负载)。
- 由于这些排序是 MapReduce 自动完成的,用户无法控制,因此,在hadoop 1.x 中无法避免,也不可以关闭,但 hadoop2.x 是可以关闭的。
5.Spark篇(美团、字节等)
答案:
- 通过spark的coalesce()方法和repartition()方法
- 降低spark并行度,即调节spark.sql.shuffle.partitions
- 新增一个并行度为1的任务,专门用来合并小文件
6.Flink篇(拼多多、联通等)
答案:
- Flink 使用一个引擎就支持了DataSet API 和 DataStream API。其中DataSet API用来处理有界流,DataStream API既可以处理有界流又可以处理无界流,这样就实现了计算上的流批一体(目前流批一体最大的问题在于存储的统一上)
![[图片]](https://img-blog.csdnimg.cn/7a96fe17ba6941f0aa1f3a890b8d4d54.png)
7.Kafka篇(京东、携程等)
答案:
- 0.11版本之后,kafka提出了一个非常重要的特性,幂等性(默认是开启的),也就是说无论producer发送多少次重复的数据,kafka只会持久化一条数据,把这个特性和至少一次语义(ack级别设置为-1+副本数=2+ISR最小副本数=2)结合在一起,就可以实现精确一次性(既不丢失又不重复)。我大致介绍一下它的底层原理:在producer刚启动的时候会分配一个PID,然后发送到同一个分区的消息都会携带一个SequenceNum(单调自增的),broker会对<PID,partition,SeqNum>做缓存,也就是把它当做主键,如果有相同主键的消息提交时,broker只会持久化一条数据。但是这个机制只能保证单会话的精准一次性,如果想要保证跨会话的精准一次性,那么就需要事务的机制来进行保证(producer在使用事务功能之前,必须先自定义一个唯一的事务id,这样,即使客户端重启,也能继续处理未完成的事务;并且这个事务的信息会持久化到一个特殊的主题当中)
8.资源调度篇(快手、vivo、字节等)
答案:
- 首先客户端提交任务到RM上,同时客户端会向RM申请一个application,然后RM会告诉客户端资源的提交路径(比如jar包,配置文件);然后客户端就会提交任务运行需要的资源到对应路径上,提交完毕后,就会向RM申请Appmaster。RM会将用户的请求初始化成一个task,放入调度队列中,接着就会有NM领取task任务并且创建container容器和启动Appmaster。
- 然后Appmaster会向RM申请运行MapTask的资源,假设有两个切片,RM就会将运行maptask任务分配给两个nodemanager,这两个nodemanager分别领取任务并创建容器;Appmaster向这两个NM发送程序启动脚本,分别启动maptask;Appmaster等待所有maptask运行完毕后,再次向rm申请容器,运行reducetask
- 程序运行完毕后,Appmaster会向RM申请注销自己
9.数据质量篇(微众、美团等)
答案:
1. 完整性
a. 定义:完整性是指数据的记录和信息是否完整,是否存在缺失的情况。数据的缺失主要包括记录的缺失和记录中某个字段信息的缺失,两者都会造成统计结果不准确,所以说完整性是数据质量最基础的保障。
b. 案例:比如交易中每天支付订单数都在100万笔左右,如果某天支付订单数突然下降到1万笔,那么很可能就是记录缺失了。对于记录中某个字段信息的缺失,比如订单的商品ID、卖家ID都是必然存在的,这些字段的空值个数肯定是0,一旦大于0就必然违背了完整性约束。
2. 准确性
a. 定义:指数据中记录的信息和数据是否准确, 是否存在异常或者错误的信息。
b. 案例:比如一笔订单如果出现确认收货金额为负值,或者下单时间在公司成立之前,或者订单没有买家信息等,这些必然都是有问题的。
3. 一致性
a. 定义:一致性一般体现在跨度很大的数据仓库体系中,比如阿里巴巴数据仓库,内部有很多业务数据仓库分支,对于同一份数据,必须保证一致性
b. 案例:例如用户ID,从在线业务库加工到数据仓库,再到各个消费节点,必须是同一种类型,长度也需要保持一致
4. 及时性
a. 定义:在确保数据的完整性、准确性和一致性后,接下来就要保障数据能够及时产出,这样才能体现数据的价值。一般决策支持分析师都希望当天就能够看到前一天的数据,而不是等三五天才能看到某一个数据分析结果;否则就已经失去了数据及时性的价值,分析工作变得毫无意义。
b. 案例:现在对时间要求更高了,越来越多的应用都希望数据是小时级别或者实时级别的。比如阿里巴巴“双11” 的交易大屏数据,就做到了秒级

10.大数据场景篇(腾讯、百度等)
答案:
- 首先想到的就是全局排序,那么需要判断内存是否能够装的下?110^94B = 4GB,需要4G的内存,如果机器的内存小于4G,显然是不行的
- 第二种方法就是分治法,将这1亿个数通过hash算法,分为1000份,每份100万个数据,找到每份数据中最大的10000个数,最后在10010000中找出最大的10000个数,最大占用内存为 10000004B = 4MB。从100万个数中找到最大的10000个数的方法是快速排序的方法,但是我们没有必要将这100万个数排序,只用找到前10000个数,大致的思路是:将第一个数字设置为基准元素,然后将这100万个数分为两堆,如果大于基准的堆的个数大于10000个,那么继续对该堆进行一次快速排序,如果此时大的堆的个数n小于10000个,那么在小的堆中找到前10000-n的数字。
- 第三种方法就是小顶堆,首先读入前10000个数来创建大小为10000的最小堆,建堆的时间复杂度是O(m),然后遍历后续的数字,并与堆顶元素(最小)进行比较,如果比堆顶元素小,则继续遍历后面的数字即可;如果比堆顶元素大,则替换堆顶元素并重新调整堆为最小堆。直至遍历完所有的数字,最后输出当前堆的所有数字就可以了。整体的时间复杂度是O(mn)
原文地址:https://blog.csdn.net/qq_42397330/article/details/134625941
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_28068.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!