本文介绍: ITE可以计算图片和问题的相似度,GradCAM可以生成一个粗略的定位图,突出显示给定问题的匹配图像区域。为了去除有噪声的字幕,我们使用ITE来计算生成的字幕和采样的问题相关图像补丁之间的相似性得分,并过滤匹配得分小于0.5的字幕。总的来说,这个过程产生了与问题相关的、多样化的、干净的合成字幕,在视觉和语言信息之间架起了一座桥梁。为了解决这个问题,我们生成关于图像中与问题相关的部分的标题,并将其包含在LLM的提示中。有了候选答案后可以使用现成的任意的问题生成模型为每一个候选答案生成具体的问题。
arxiv:[2212.10846] From Images to Textual Prompts: Zero-shot VQA with Frozen Large Language Models (arxiv.org)
一、介绍
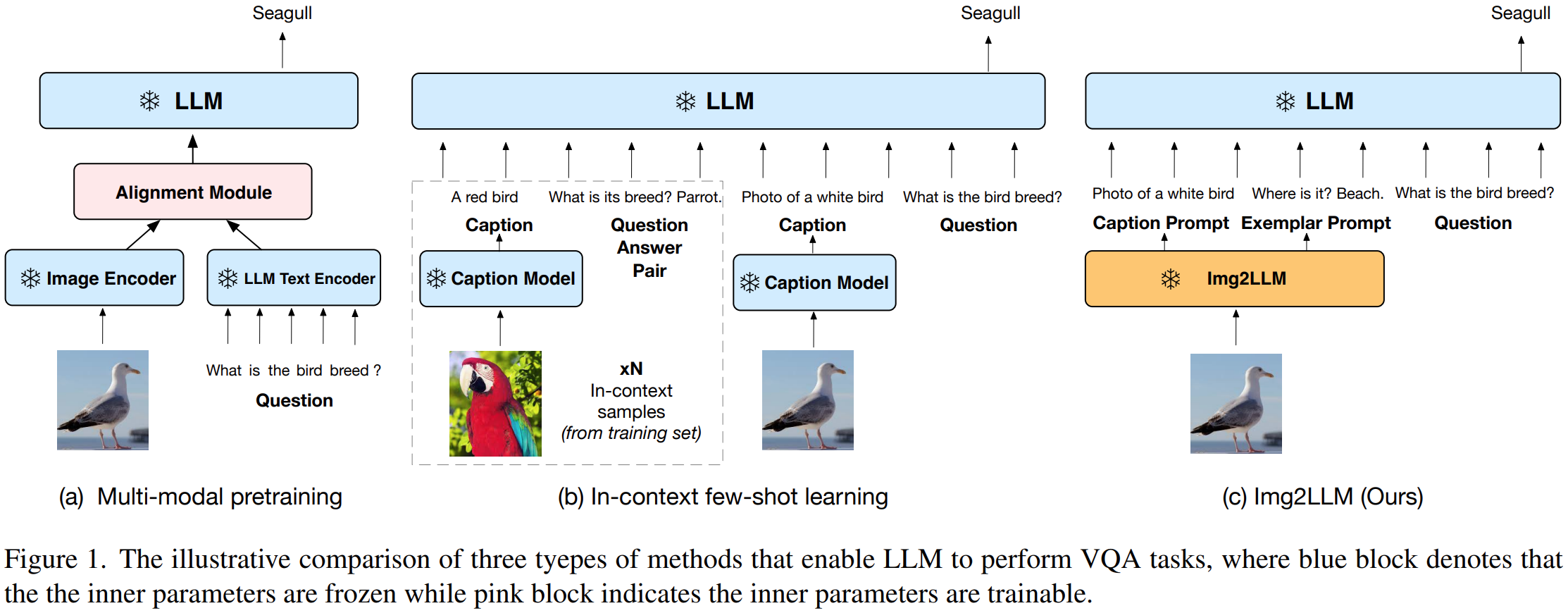
使用大语言模解决VQA任务的方法大概两种:multi–modal pretraining and language–mediated VQA,即多模态预训练的方法和以语言模型为媒介的VQA。
Multi–modal pretraining:训练一个额外的模块对齐视觉和语言向量。这类方法有两个很大的缺点,一是计算资源大,训练Flamingo需要1536 TPUv4,耗时两周。另外是灾难性遗Catastrophic forgetting. 如果LLM与视觉模型联合训练,则对齐步骤可能对LLM的推理能力不利。
Language–mediated VQA:这种VQA范式直接采用自然语言作为图像的中间表示,不再需要昂贵的预训练,不需要将图片向量化表示。PICa这种方法在few-shot setting中,为图片生成描述,然后从训练样本中选择in–context exemplars范例,但是当没有样本时,其性能会显著下降;另外还有一种方法生成与问题相关的标题。由于零样本的要求,它无法提供上下文中的范例,也无法获得上下文中学习的好处。因此,它必须依赖于特定QA的LLM,UnifiedQAv2,以实现高性能。
以语言为媒介的VQA,模态连接是通过将图片转化为语言描述,而不是稠密向量。任务连接是通过few-shot in-context exemplars或者大模型直接在文本问答上微调。




声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。







