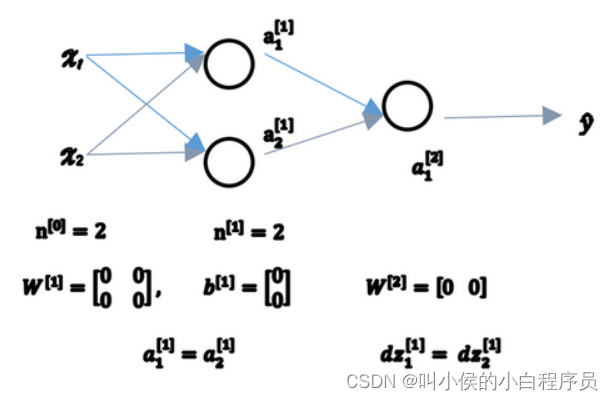
本文介绍: 所以,只要是正值的情况下,导数恒等于1,当是负值的时候,导数恒等于0。如果你这样初始化这个神经网络,那么这两个隐含单元就会完全一样,因此他们完全对称,也就意味着计算同样的函数,并且肯定的是最终经过每次训练的迭代,这两个隐含单元仍然是同一个函数。如果你要初始化成0,由于所有的隐含单元都是对称的,无论你运行梯度下降多久,他们一直计算同样的函数,这没有任何帮助。函数两者共同的缺点是:在z特别大或者特别小的情况下,导数的梯度或者函数的斜率会变得特别小,最后就会接近于0,导致梯度下降的速度降低。分析一下这是为什么。
一、简介
1.1 非线性激活函数
1.1.1 tanh激活函数
使用一个神经网络时,需要决定在隐藏层上使用哪种激活函数,哪种用在输出层节点上。到目前为止,只用过sigmoid激活函数,但是,有时其他的激活函数效果会更好。tanh函数或者双曲正切函数是总体上都优于sigmoid函数的激活函数。

tanh函数是sigmoid的向下平移和伸缩后的结果。对它进行了变形后,穿过了(0,0)点,并且值域介于+1和-1之间。结果表明,如果在隐藏层上使用tanh函数效果总是优于sigmoid函数。因为函数值域在-1和+1,其均值是更接近零的。在训练一个算法模型时,如果使用tanh函数代替sigmoid函数中心化数据,使得数据的平均值更接近0而不是0.5。这会使下一层学习简单一点!!!
但有一个例外:在二分类的问题中,对于输出层,需要的值是0或1,所以想让数值介于0和1之间 ,而不是在-1和+1之间,所以需要使用sigmoid激活函数。这种情况下,可以对隐藏层使用tanh激活函数,输出层使用sigmoid函数。
sigmoid函数和tanh函数两者共同的缺点是:在z特别大或者特别小的情况下,导数的梯度或者函数的斜率会变得特别小,最后就会接近于0,导致梯度下降的速度降低。
1.1.2 Relu激活函数
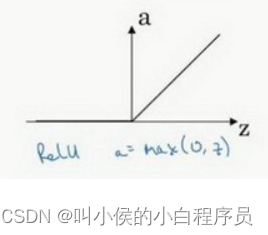
1.1.3 Leaky Relu激活函数

1.2 不同激活函数的使用场合
二、计算
2.1 随机初始化
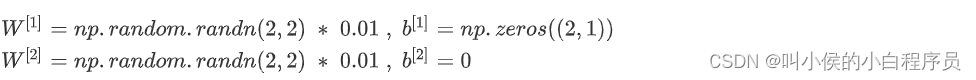
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。




