二、语义相似度简介
自然语言处理 (NLP) 中的语义相似性代表了理解机器如何处理语言的一个重要方面。它涉及对两段文本在含义方面的相似程度进行计算分析。这个概念在从信息检索到会话人工智能的各个领域都具有深远的影响。语义相似度是指两个文本片段之间相似度的度量。与侧重于单词排列的句法分析相反,语义相似性关注的是文本及其含义的解释。理解这个概念对于机器有效地处理、分析人类语言并与人类语言交互至关重要。

三、NLP 中语义相似度的演变
多年来,NLP 领域发生了巨大的发展,测量语义相似性的方法也随之变得更加复杂。早期的方法严重依赖基于字典的方法和句法分析。然而,这些方法往往无法捕捉人类语言的细微差别。
机器学习和深度学习的出现彻底改变了这个领域。词嵌入、上下文嵌入(如 BERT)和神经网络模型等技术允许对文本进行更细致和上下文感知的解释,从而显着提高语义相似性度量的准确性。
四、测量语义相似度的技术和工具
- 向量空间模型:这些模型,如 TF-IDF 和潜在语义分析 (LSA),表示多维空间中的文本,其中语义相似性是根据向量之间的距离或角度推断的。
- 词嵌入: Word2Vec 或 GloVe 等技术根据上下文在密集向量空间中表示单词,从而更有效地捕获语义。
- 上下文嵌入: BERT 或 GPT 等高级模型使用深度学习来生成嵌入,将句子中单词的上下文考虑在内,从而更准确地表示其含义。
- 语义网络: WordNet 等工具提供了单词之间丰富的语义关系网络,从而实现了更加基于同义词库的语义相似性方法。
五、语义相似度的应用
语义相似度有着广泛的应用:
- 信息检索:增强搜索引擎返回结果的相关性。
- 文本摘要:自动生成大文本的简洁摘要。
- 问答系统:提高人工智能系统提供答案的准确性。
- 机器翻译:通过理解跨语言短语的语义等效性来提高翻译质量。
- 情感分析:通过理解文本含义的细微差别来确定文本的情感。
六、挑战和未来方向
尽管取得了进步,NLP 中的语义相似性仍面临着一些挑战:
- 语言歧义:单词根据上下文可能有多种含义,因此很难准确确定语义相似性。
- 文化和语言多样性:语言深受文化和地区背景的影响,这对在特定语言数据集上训练的模型提出了挑战。
- 计算复杂性:高级模型需要大量计算资源,这使得实时应用程序难以访问它们。
NLP 中语义相似性的未来致力于开发更复杂的模型来应对这些挑战。人工智能与认知语言学的整合、对跨语言模型的更多关注以及更先进的神经网络架构的使用是一些有希望的领域。
七、代码解析
为了使用 Python 演示语义相似性,我们可以创建一个合成数据集并使用一些流行的 NLP 库,例如 NLTK、spaCy 和 scikit–learn。我们将按照以下步骤操作:
- 创建综合数据集:生成一组具有不同相似程度的句子。
- 文本预处理:基本清理和标记化。
- 文本向量化:使用 TF-IDF 将句子转换为数值向量。
- 计算语义相似度:使用余弦相似度来衡量句子之间的语义相似度。
- 可视化结果:创建绘图以可视化相似性。
第 1 步:安装所需的库
您需要安装 NLTK、spaCy、scikit–learn 和 Matplotlib。您可以使用 pip 执行此操作:
pip install nltk spacy scikit-learn matplotlibimport nltk
import spacy
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# Ensure you have the English model downloaded for spaCy
# !python -m spacy download en_core_web_sm
# Create a synthetic dataset
sentences = [
"The quick brown fox jumps over the lazy dog.",
"A quick brown dog outpaces a fast fox.",
"Lorem ipsum dolor sit amet, consectetur adipiscing elit.",
"A lazy dog lounging under a tree.",
"The fox and the dog chase each other."
]
# Initialize spaCy
nlp = spacy.load("en_core_web_sm")
# Text Preprocessing with spaCy
def preprocess(text):
doc = nlp(text.lower())
return [token.lemma_ for token in doc if not token.is_stop and not token.is_punct]
# Vectorization of text using TF-IDF
tfidf_vectorizer = TfidfVectorizer(tokenizer=preprocess)
tfidf_matrix = tfidf_vectorizer.fit_transform(sentences)
# Calculating Semantic Similarity
cosine_similarities = cosine_similarity(tfidf_matrix)
# Visualizing Results
plt.figure(figsize=(10, 8))
plt.imshow(cosine_similarities, cmap='hot', interpolation='nearest')
plt.colorbar()
plt.xticks(ticks=np.arange(len(sentences)), labels=range(len(sentences)))
plt.yticks(ticks=np.arange(len(sentences)), labels=range(len(sentences)))
plt.title("Semantic Similarity Matrix")
plt.show()解释:
- 合成数据集:这是主题上具有一定相似性的句子的小型集合。
- 预处理:我们使用 spaCy 进行词形还原和停用词删除。
- TF-IDF 矢量化:将句子转换为 TF-IDF 向量。
- 余弦相似度:测量 TF-IDF 向量之间角度的余弦以确定语义相似度。
- 绘图:创建热图来可视化相似性矩阵。
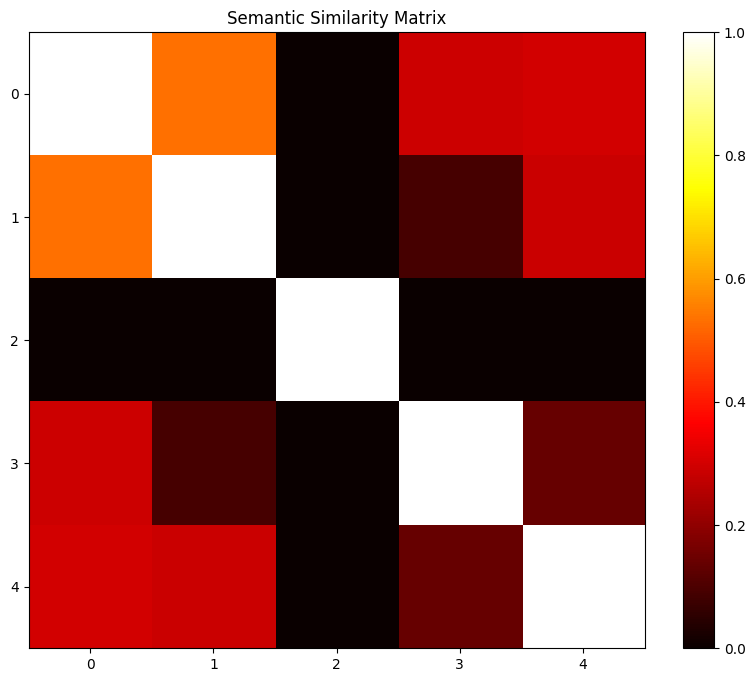
运行此脚本将生成一个热图,可视化合成数据集中句子之间的语义相似性。颜色越亮,句子之间的相似度越高。
八、结论
NLP 中的语义相似性是理解人工智能如何处理人类语言的基石。该领域的进步为人工智能应用开辟了无数可能性,使与机器的交互更加直观和有效。随着技术的不断发展,语义相似性的方法和应用也会不断发展,使其成为人工智能和自然语言处理领域正在进行的令人兴奋的研究和开发领域。
原文地址:https://blog.csdn.net/gongdiwudu/article/details/134750012
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_29962.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!