本文介绍: 例如,如果有5个个体学习器,它们的权重分别为[0.2, 0.3, 0.1, 0.2, 0.2],则最终的预测结果是将个体学习器的预测结果乘以对应的权重后相加得到的。每个个体学习器对样本进行预测后,最终的预测结果是通过对个体学习器的预测结果进行平均得到的。然后,我们将数据集拆分为训练集和测试集。在集成学习中,个体学习器可以是同质的(使用相同的学习算法,但在不同的训练集上训练)或异质的(使用不同的学习算法)。每个基本学习器都是在不同的训练集上独立训练得到的,最后通过集成基本学习器的预测结果来进行最终的预测。
1.概念
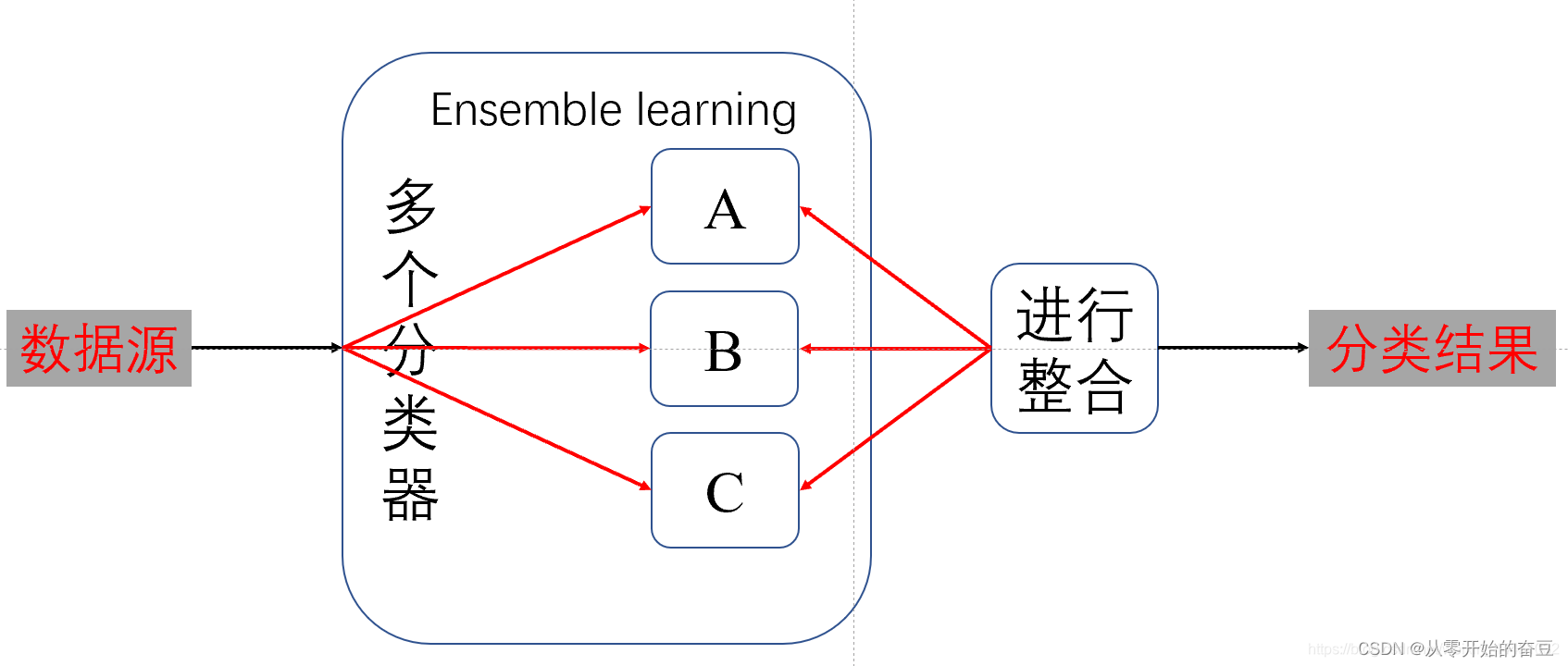
集成学习是一种机器学习方法,旨在通过组合多个个体学习器的预测结果来提高整体的预测性能。它通过将多个弱学习器(个体学习器)组合成一个强学习器,以获得更准确、更稳定的预测结果。
在集成学习中,个体学习器可以是同质的(使用相同的学习算法,但在不同的训练集上训练)或异质的(使用不同的学习算法)。集成学习的核心思想是通过个体学习器之间的合作和协同来提高整体的预测性能。
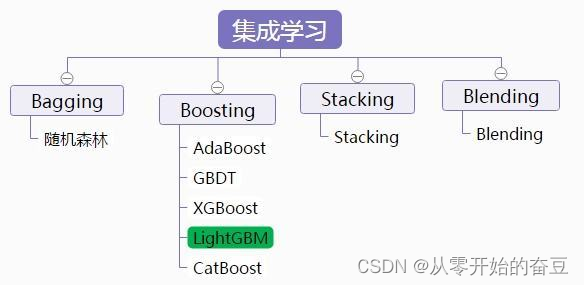
1.1 类型
集成学习可以分为两种主要类型:bagging和boosting。
1.2 集成策略
集成策略是集成方法中用于合并个体学习器预测结果的策略。它决定了如何将个体学习器的预测结果组合起来得到最终的集成预测结果。下面是一些常见的集成策略:
1.3 优势
2. 代码实例
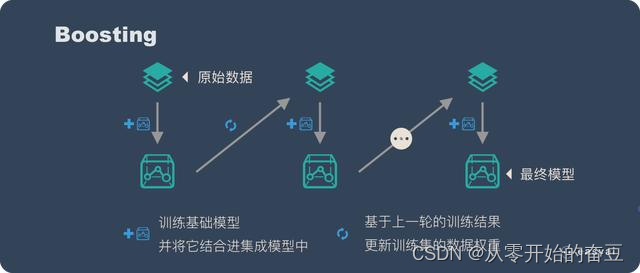
2.1boosting
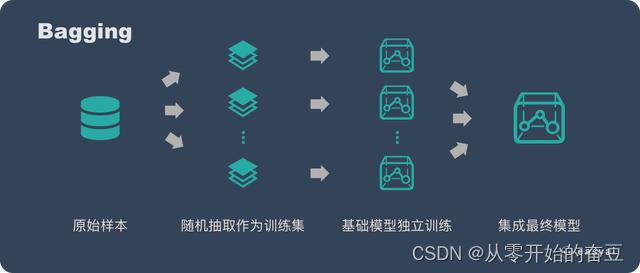
2.2 bagging
2.3 集成
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






