目录
Part.01 关于HDP
Part.02 核心组件原理
Part.03 资源规划
Part.04 基础环境配置
Part.05 Yum源配置
Part.06 安装OracleJDK
Part.07 安装MySQL
Part.08 部署Ambari集群
Part.09 安装OpenLDAP
Part.10 创建集群
Part.11 安装Kerberos
Part.12 安装HDFS
Part.13 安装Ranger
Part.14 安装YARN+MR
Part.15 安装HIVE
Part.16 安装HBase
Part.17 安装Spark2
Part.18 安装Flink
Part.19 安装Kafka
Part.20 安装Flume
十七、安装Spark2
1.安装
添加Spark2服务
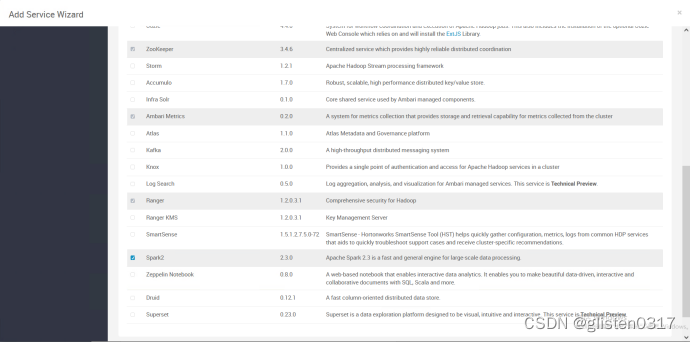
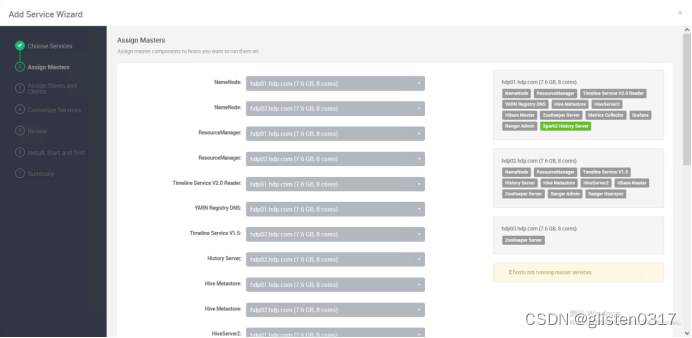
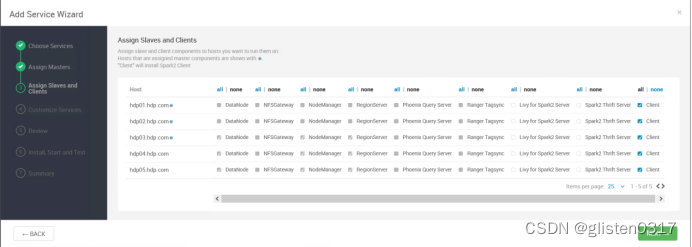
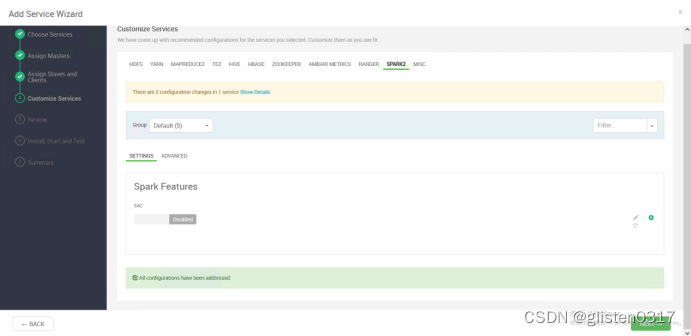
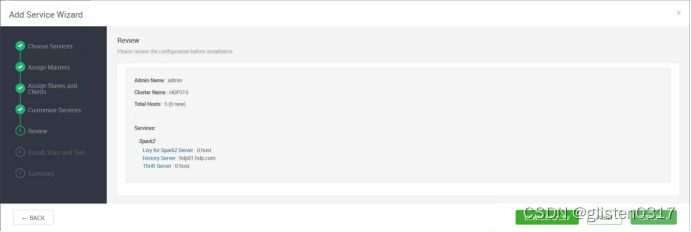
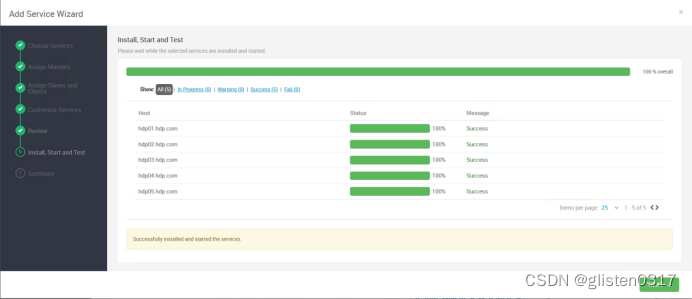
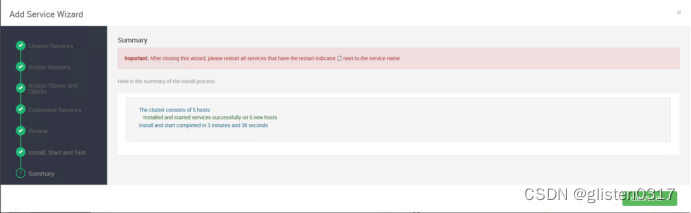
需要重启HDFS、YARN、MapReduce2、Hive、HBase等相关服务
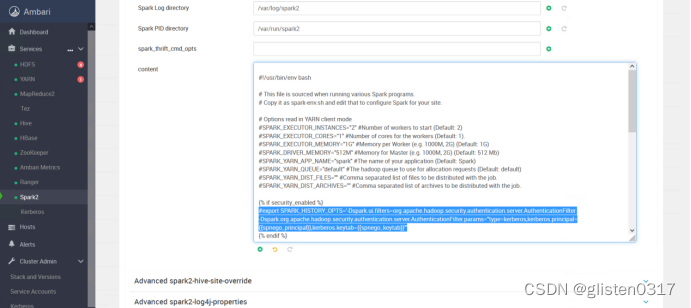
2.取消kerberos对页面的认证
在CONFIGS->Advanced spark2-env下的content里,将下面内容加#注释掉
访问页面,http://hdp01.hdp.com:18081/
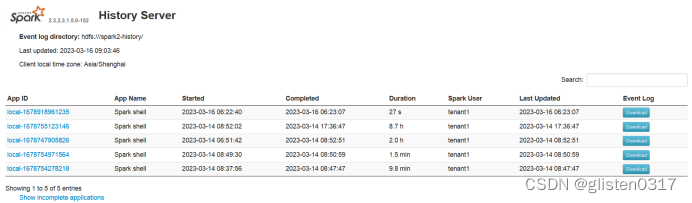
3.确认Spark on Yarn配置
查看/usr/hdp/3.1.5.0-152/spark2/conf/spark–env.sh
/usr/hdp/3.1.5.0-152/hadoop–yarn/conf/yarn–site.xml
4.spark–shell交互式命令
(1)启动

(3)变量回写到本地文件


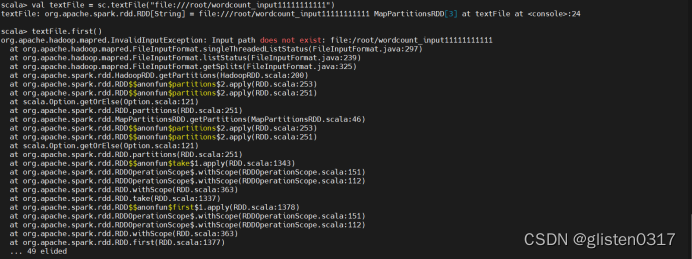
实验:Spark SQL-词频统计
(1)spark-shell方式

(2)spark-submit方式




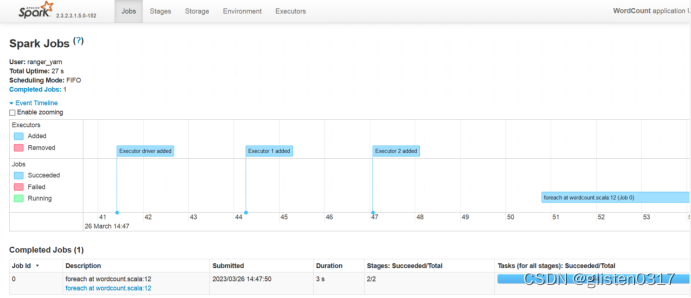
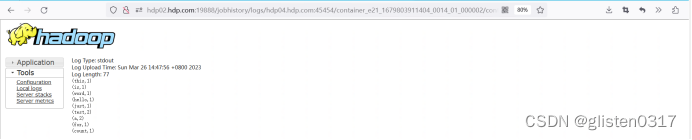
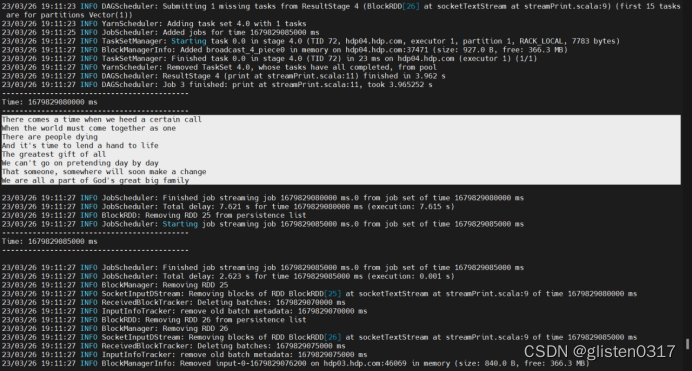
6.实验:Spark Streaming-显示实时流内容

7.spark-submit参数
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。