推书:《现代操作系统》《操作系统–精髓于设计原理》《UNIX环境高级编程》



前言
这个问题,进行了浅述,和 动态库当中的 数据存储,其实也是按照谁先修改数据,谁就进行写时拷贝的方式,来共用动态库当中数据的。
具体请参考上述博客:
Linux – 动静态库(下篇)-CSDN博客
程序的加载
程序没有加载之前的地址(此时还是程序)
程序在编译好之后,内部有 地址吗?还是说 地址是在 程序的被加载到内存当中才有的地址?
先说结论:程序在编译好之后,就已经存储了地址,这个地址是程序编译好之后就存在的,不需要加载到内存当中才有地址。
如果我们看汇编话,其实,程序在 执行到函数之时,会有 call 命令,或者是 jmp 命令,跳转到该函数定义的首地址处,而程序在顺序执行的过程当中,地址也是顺序排列的。
当然,除了上述命令之外,肯定还是有很多命令的,这些都是属于汇编当中的知识。尽管我们不知道,但是我们知道,程序被编译形成可执行文件之后,其实在这个文件当中就已经有地址了。

如上所示。
而现如今的 可执行程序,再被编译链接形成可执行文件的过程当中,被分成了很多的段;而这些段其实已经是按照 平坦模式 来进行划分的了。
什么是平坦模式呢?
其实就是,可执行程序已经基本按照 进程地址空间当中的 布局,来进行的划分段 区域的了。
就算 在进程执行之时,可能有 栈区 , 堆区等等的这些区域可能还没有进行分配,但是对应的 数据区,代码区,正文部分,初始化全局变量 和 未初始化 全局变量 这些区其实已经是有了的。
由此上述编译器生成的 可执行程序当中的布局来看,编译器也是要考虑操作系统的!!
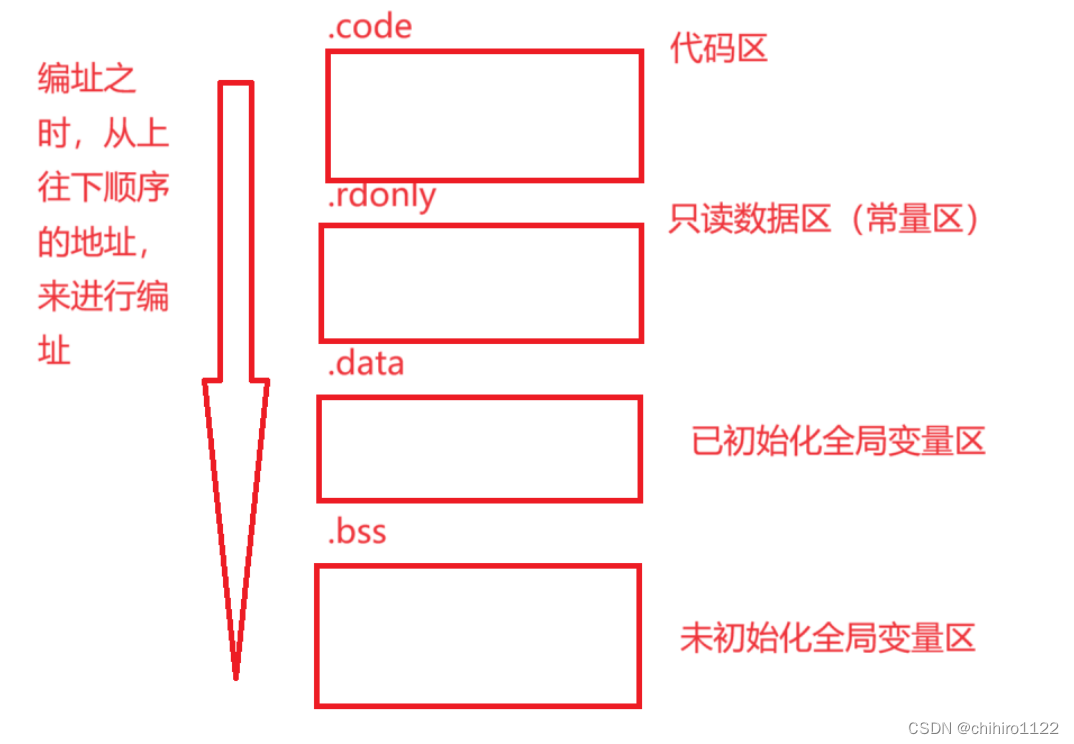
在上述过程当中,从上往下,这样来进行书顺序编址。有上述你也可以看到很多的段,这个段都是对应 进程地址空间当中的 各个分区来划分的。
所以,其实上述的地址,其实就是我们所说的 逻辑地址(虚拟地址)。
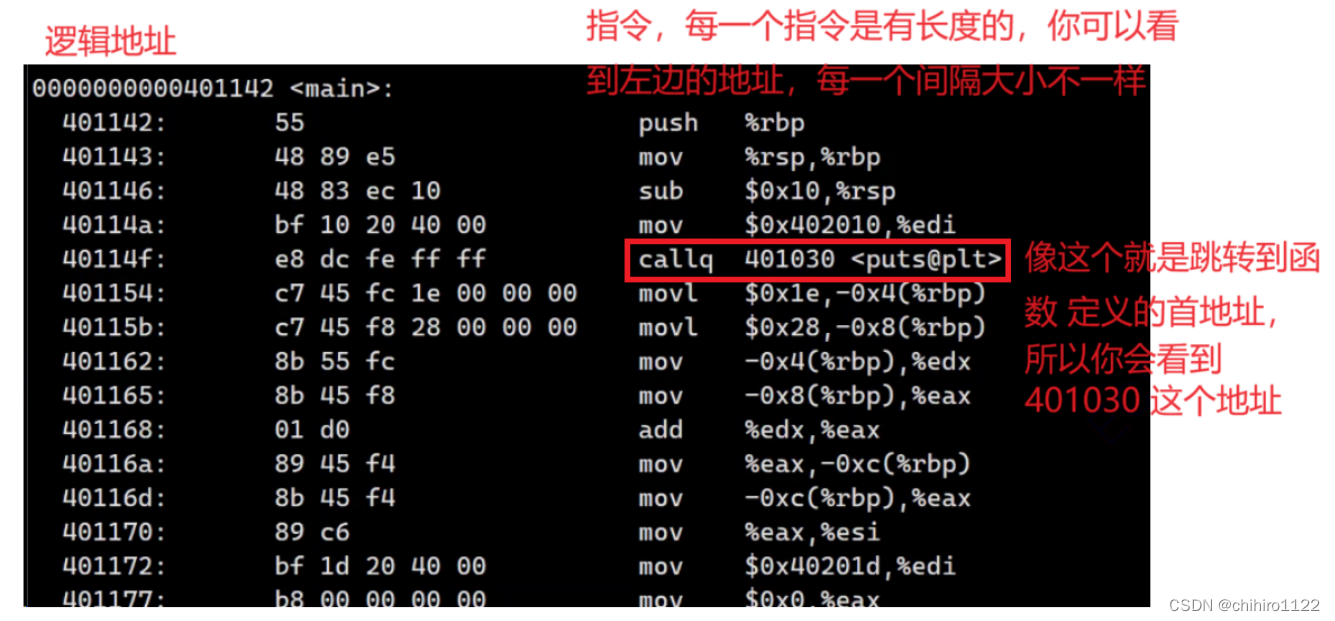
上述就是汇编代码,像上述在左边 地址其实是可以不用存在的,但是每一个 指令都是有自己的长度的,我们只需要知道这个 指令的长度和起始地址,就可以让 cpu 去执行这个指令。
其实,上述所有的指令其实就是要靠 cpu 去执行的,所以,只需要一个入口地址,比如函数的地址地址,然后又知道每一个指令的长度的话,那么整个函数,甚至于整个 程序就可以被执行起来了。
所以,最左边的地址,其实是没有的,只是为了让我们更加明显的知道某一个 命令的 地址是多少。你也可以发现,在函数的开头,用的地址的格式都不一样,其实只有在函数开头可能才会显示地址,因为函数的开头也就是这个函数当中所有指令的 入口,有了入口 和 每一个指令的长度,才能正常执行代码。
cpu 当中只能认识一些简单的 命令,像上述的汇编一样,比如 push 命令,在 cpu 内部可能就是识别 二进制序列,可能识别到时 00000···11 这个二进制序列,代表的就是 push 这个命令,那么 cpu 就回去执行这个命令。
我们可以提前向上述的方式吗,在cpu 内部 提前设置 指令集的东西,当向cpu 内部的寄存器当中写入 指令集 当中有的 二进制序列的话,此时,cpu 不会把这个二进制序列看做是一个数据,而是把这个二进制序列看做是一个 指令,或者是 控制指令。
当这些指令多了起来,实际上就我们所看到了 cpu 为我们所做的一系列的动作。
简单来说,既是在 cpu 设计之时,就会内置 指令集,而指令集 也分为两大类,一类是 精简指令集,一类是 复杂指令集。
程序被加载到内存之后(此时是进程)
在上述当中我们已经说过了 可执行程序当中 被分段了。
当 可执行程序被加载到内存当中之时,我们那 代码区 当中的代码举例:
此时,可执行程序已经被加载到 内存里了,那么既然被加载到内存当中了,那么里面的全部指令 就会有自己的 物理地址了!!
所以,当 一条指令 ,被加载到内存当中之时,这条指令,如果只看这个可执行程序当中生成的地址的话,这个指令是有自己的 逻辑地址(虚拟地址)的;
如果是只看 被加载到内存空间当中的话,已经在内存上存储了,那么肯定是占用了 物理空间的,所以 这条指令 也是有自己的 物理地址的。
所以,这个指令,再被加载到内存之后,这个指令的 物理地址 和 虚拟地址就已经 存在了!!!
Linux – 进程程序替换 – C/C++ 如何实现与各个语言之间的相互调用 – 替换环境变量-CSDN博客
在之前说到 程序替换 之时,我们说过,在可执行程序的最开始处,有一个表头部分,其中有一个很多的关于这个可执行程序当中相关属性。
其中就有一个 entry:表示的是 入口地址。那么这个 entry 当中存储的是物理地址还是 逻辑地址呢?
所以,这个 entry 当中存储的就是 整个程序 ,在 0~4G 空间当中,main函数的地址。这个地址是 属于 可执行程序当中的地址,属于是 逻辑地址。
我们还说过: EIP/PC 这个 存在 与 cpu 当中的 寄存器。在进程的 PCB 当中,也会存储 cwd:当前的工作目录;和 exe:自己的 可执行程序。
因为在加载 可执行程序之前,PCB 这些内核级别的结构体 等等 内核数据结构是要生成的,所以,cpu 可能会先加载 可执行程序当中的 entry : 程序的入口地址。把这个 entry 当中的地址,存储在 EIP/PC 这个寄存器当中。
所以,当程序完全被加载到内存当中之后,cpu 就可以由 EIP/PC 当中存储的 程序入口地址,通过映射,来找到这个 程序的入口地址(即main 函数所在地址)。
至此,程序就开始执行了。
但是,因为此时只是加载了 可执行程序当中的表头,当 cpu 从 entry 指向的开始处,执行代码之时,此时可执行程序当中的 各个段 数据和代码,还没有加载到 内存当中。
所以,此时,当 cpu 从 进程地址空间的虚拟地址当中,在页表当中寻找映射的过程当中,就会找不到这个映射关系,也就是找不到 当前进程地址空间的虚拟地址 映射的 内存当中的物理地址。
所以,此时就会发生 缺页中断。
发生缺页中断之后,程序当中对应的数据 就会被 加载到 内存当中。而,一旦可执行程序当中的 数据被加载到内存当中之后,那么这个 数据就会拥有自己在内存当中的物理地址。
此时,在页表当中们就可以填上,对应 虚拟地址 和 物理地址所映射的 关系了。
之前还说过,内存是按照 页 为基本单位 来从磁盘当中加载数据的,所以,在上述当中不是按照一个 指令 的大小来加载的,可能是按照 一页(比如是 4kg) 的大小来加载数据的。
而被加载到内存当中的 一个一个指令,在可执行程序当中就有 自己的虚拟地址,再被加载进内存之后,就有了自己的物理地址;所以就可以按照这样的关系来在 页表当中建立映射关系了。
所以在往后,cpu 顺序执行 内存当中已经加载的指令之时,如果指令在内存当中有 cpu 就 读取指令到 EIP/PC 寄存器当中,进行执行,如没有,那么 就会发生缺页中断。
而,cpu 读到的指令当中,可能有数据,也可能有地址。(这个地址是逻辑地址,只不过加载到内存当中,被称之为 虚拟地址)
所以,对于 cpu 来说,从内存当中拿到地址(读取程序当中的地址),到处理指令,到下一次再分访问,这样的循环执行的过程,cpu 拿到的 指令的地址 都是 虚拟地址!!!!
像上述说过的 进程地址空间 和 磁盘当中存储的 可执行程序 当中分的 各个段,其实,都是可以说是一母同胞 的,都是可以相互照应的,在转换之时,没有我们想象中的那么的麻烦。
进程在设计之时,就已经考虑到了进程的地址空间的;编译器在生成 可执行程序之时,就已经考虑到了 虚拟地址空间了。
这,其实就是 操作系统 和 编译器 之间的 互相协同的 重要的表现之一。
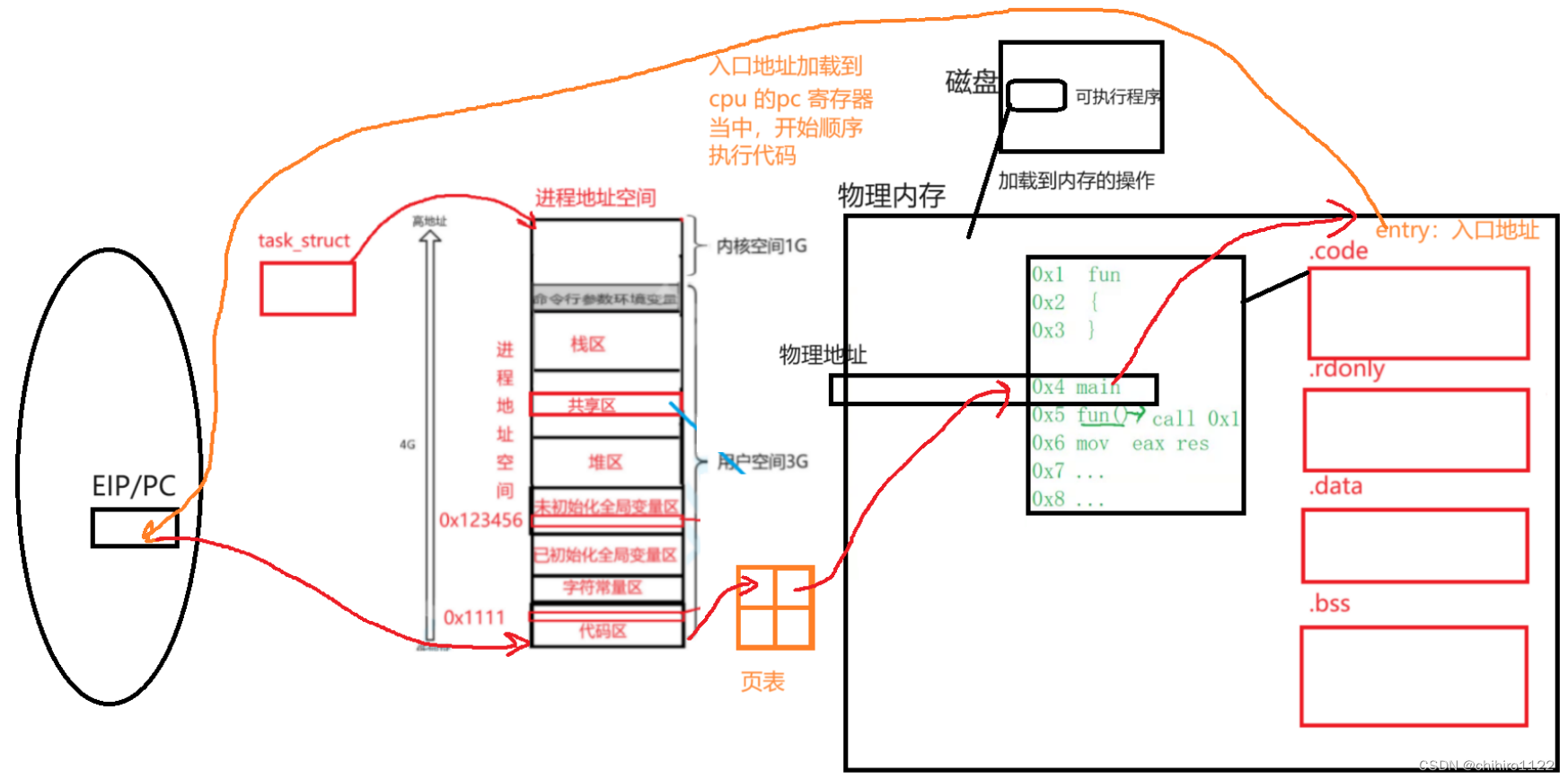
所以,上述cpu 只是用物理地址确认 当前要访问的数据在 内存当中的什么位置,但是,对于cpu 当中的 读取出来的指令,依旧是虚拟地址,由 虚拟地址在 进程地址空间当中找到对应数据在那个 虚拟地址上,然后 通过 页表来映射 到 内存当中的物理地址。
动态库的地址
其实上述所说的 逻辑地址和 虚拟地址是不一样的。
比如在一个跑道上,这个跑到长 100 m ,在这个跑道的 50m 有一棵树,那么有两个人,一个人在 树的前方 10 m 处,另一个人在树的前方 20 m 处,那么,对应的 如果把树的前方 这个方向定义在 从 跑道 0m 处 到 100m 这个方向。
那么,这两个人的位置分别在 跑道的 60m 处 和 70 m 处。
所以,在树的前方 10m 这种地址就是 相对地址/逻辑地址。
而虚拟地址指的是在 可执行程序当中 从 0 开始到 可执行程序结束的这个 区域的地址。
但是,因为 我们上述所说的 地址 也是从 0 开始的,所相当于是 这个棵树 在跑道的起点,也就是 0m位置处。
所以,在现在可执行程序看来,虚拟地址/绝对地址 的值 其实和 逻辑地址的值是一样的。
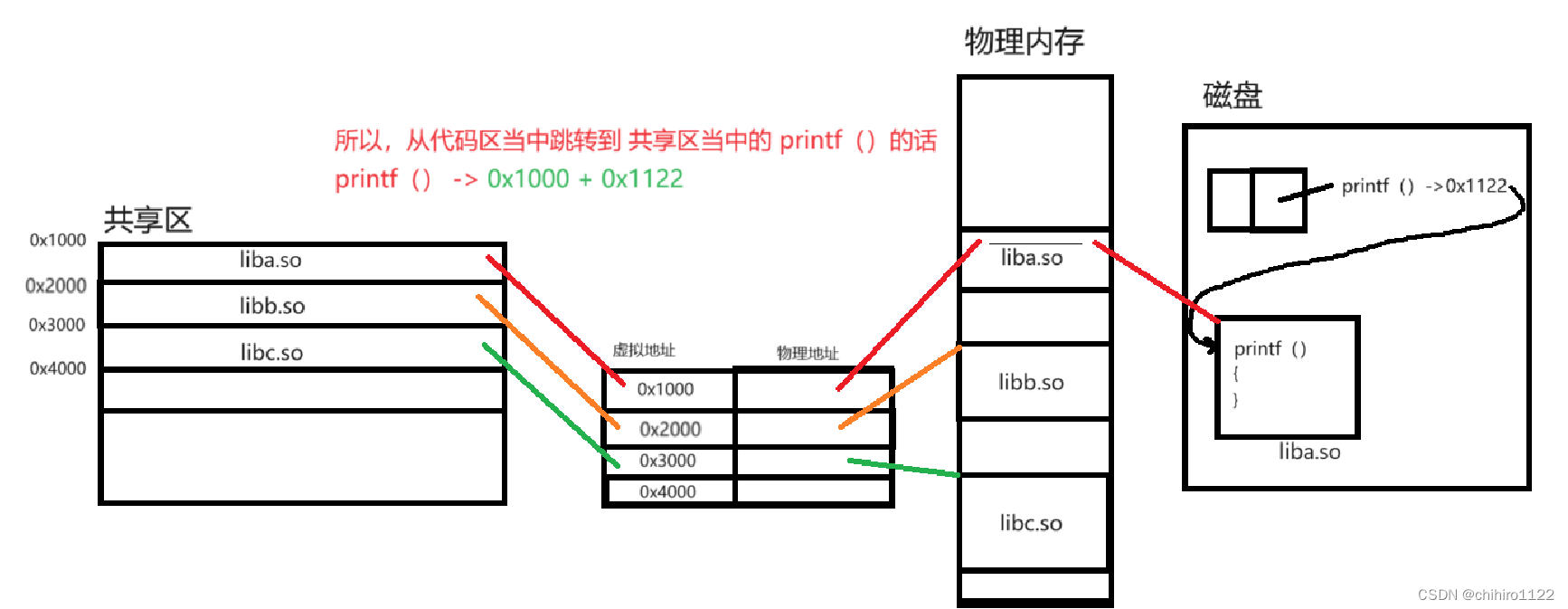
call命令的话,在编译之后,加载内存当中,此时,cpu不再是使用 函数名 像是 printf ()这个的函数名来帮助cpu 来找到这个函数定义的位置,实际上是 类似 call 命令,在函数名位置把他替换为 这个函数的定义的首位置。
cpu 是不认识这个 函数名的,有了汇编,再汇编当中 有这个函数的定义位置,然后更具这个 指令 跳转到 对应函数定义的位置。
也就是说,程序当中我没使用了 printf()这个库函数,但是这个 库函数吗,在我们把源程序 编译生成 可执行文件之时,或者是在 形成 二进制文件当中,这个printf()函数已经不存在了,变成 地址了,也就是这个函数的定义的起始位置。(也就是在动态库当中的逻辑地址)
如果这个动态库 ,并没有加载到 内存当中,或者说是 在共享区当中并没有发现 这个 代码,在 页表当中找不到这个 共享库数据,那么就发生缺页中断,把 动态库加载到 内存当中。
对于上述的过程,其实都应该没有什么问题的。但是接下来就有一个新的问题:
共享区其实是很大的,比如你在写程序的过程当中,不能之用一个 库,你可能会用很多个库,应用很多的头文件。那么这个库文件很多都是以 动态库的方式进行链接的,这也就意味着,这个库是要加载到内存当中的,既然库要加载到大内存当中,也就说明这个库的 物理地址 是要映射 进程地址空间 当中的共享库的当中 虚拟地址的。
这么大的 共享区 ,我们像要映射的话,具体应该映射到 那里呢?
在上述跳转的过程当中,只有 printf()函数,在动态库当中的起始位置,但是不知道这个动态库在那里啊?
在编译生成的 可执行代码当中,编译代码的指令上带的就是 这个 printf()在 动态库当中存储的位置,所以,换言之,动态库在共享区当中存储的位置必须得确定。
不然,在代码当中只有这个 这个 printf 函数在 对应动态库当中的存储位置,没有动态库的位置是找不到这个 printf()函数的。
而且,一个进程在运行之时,当前的 printf()所在库是 先被加载还是后被加载,进程是不能控制的。
但是,从上述看来,不能不能单独把 比如printf()的地址是 0x1122 ,那么这个地址就是这个printf()函数在 库当中的实现的起始位置。
如果单独把这个地址直接映射到 共享区当中,用来充当 printf()函数的地址的话;也就说,直接把共享区当中的 0x1122 这个地址直接拿来充当 printf()函数的地址的话,在后续的库被加载进来,同样有很大可能,0x1122 又是其他函数的地址。
那么这不就冲突了吗?
就算上述方式不可取,但是,我们还是期望,当在 共享区当中加载 printf()函数的地址之时,我们希望加载的是 共享区当中的一个固定地址。
但是,上述的期望是不现实的。
因为 一个可执行程序一般会使用很多个库,如何保证这些个库,都被加载到固定位置?
所以,动态库想被加载到固定位置是不可能的!!
所以,上述固定的方式存储的是不现实的,所以,动态库应该在 共享区当中 动态的存储。
printf()函数通过编译过后所生成的地址不是 绝对地址,绝对地址是起始地址加上 偏移量,printf()函数 编译过后的地址,是这个 函数在库当中定义的起始位置,这个位置,相对与库的其实地址的偏移量。
所以,在页表当中存储的 虚拟地址,是 这个库在 共享区当中的起始地址,如果像找到某一个函数的定义,只需要,通过这个库在共享区当中的起始位置,然后加上偏移量,就可以找到这个函数在 共享区当中的位置。

静态库的不加载,也没有 -fPIC
那么,静态库为什么不加载,为什么不谈 fPIC 位置无关码呢?
很简单,因为静态库是直接把 库当中的代码拷贝到 程序当中,已经是程序的一部分了,根本不需要加载。
同样的,因为是直接拷贝的,所以,库当中的方式在拷贝之后,就已经是 可执行程序当中的方法了。所以,此时直接按照 绝对地址来编址,是可以的 ,不会出错。
vscode 当中的 Remote – SSH 插件
vscode 推荐使用 Remote – SSH 插件 来链接 Linux。
先按下 F1 ,点击上述的 Remote-SHH: Add New SSH Host。

在上述 使用 ssh 的方式链接上远端主机之后,就会提示你,是否要保存这个 远端主机的 用户名 和 密码,在下属路径下保存:

在上述路径的 config 文件当中就会存储 你 这一次登录的 远端主机的 一些信息。
在上述链接完毕之后,在左侧你就会发现多出来一个 远端访问的 标识:
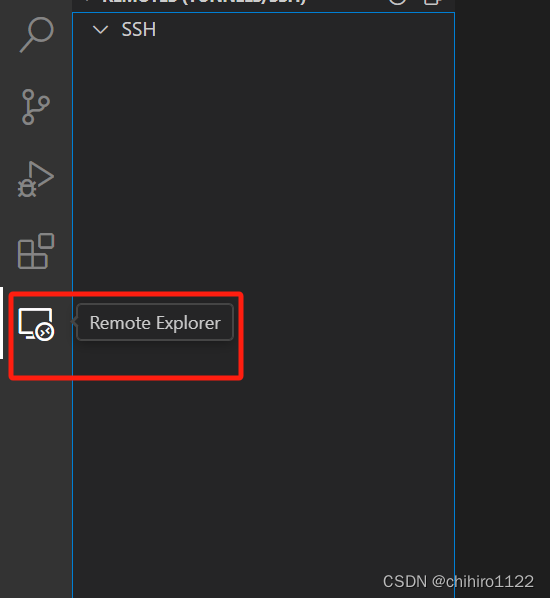
你可以发现,在 SSH 当中是没有任何主机的,我们可以点击 SSH 右侧的 “+” 号,添加主机,然后就上上述的方式来添加主机。
添加完毕之后,点击刷新就可以 发现我们刚刚添加上来的主机了:
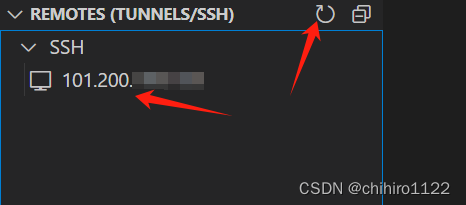
然后右键上述的主机:
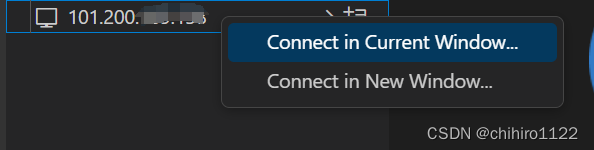
就可以输入 我们上述使用 ssh 登录的账户的密码,来登录上述的主机了:

如果是第一次登录,就会提示上述,要登录的主机是什么系统的,对应选择即可。

输入完,在上述远程连接主机当中,可以发现 当前主机logo 上 有一个 小 “√” :
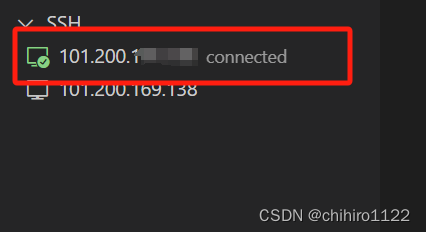
此时如果想要写文件,或者是编写代码,就可以点击下述图标 访问 远程主机当中的文件夹:
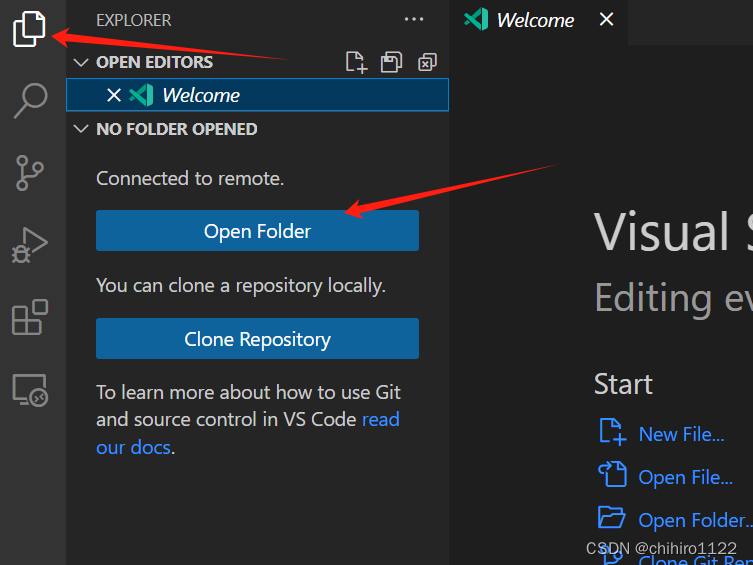
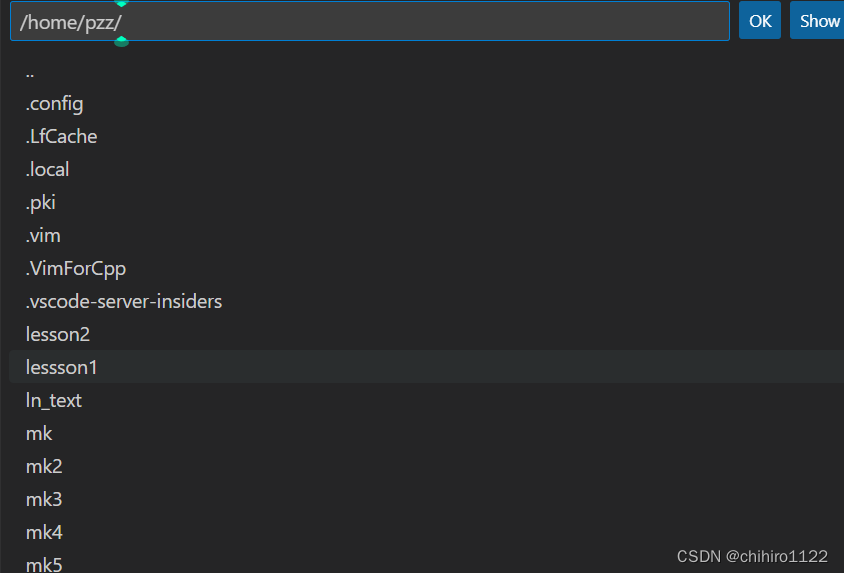
选择文件夹之后,他又会让我们去输入用户密码,第一次选择还会选择一次 主机的系统:


输入完毕之后,就可以访问到上述目录当中的 文件和 目录了:
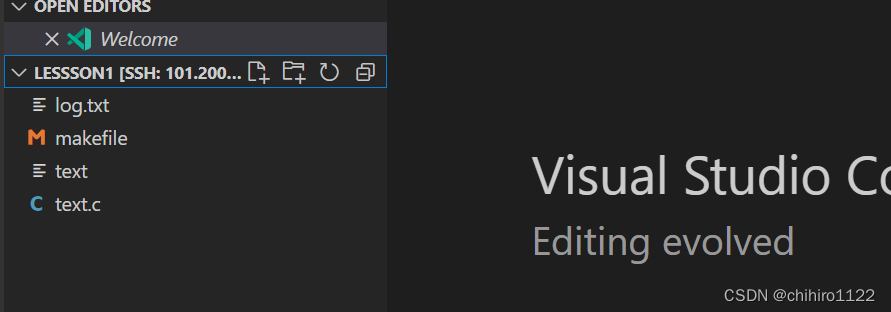
此时我们就可以在 vscode 当中创建新的文件,在这个文件当中输入的数据,保存之后,都可以在 远端服务器当中找到:
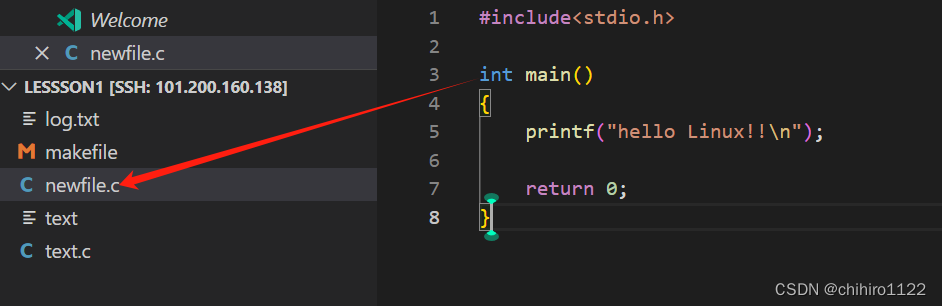
如上所示,在上述新建文件 newfile.c ,在其中写上简单的代码,此时我们登录远端主机上查看:
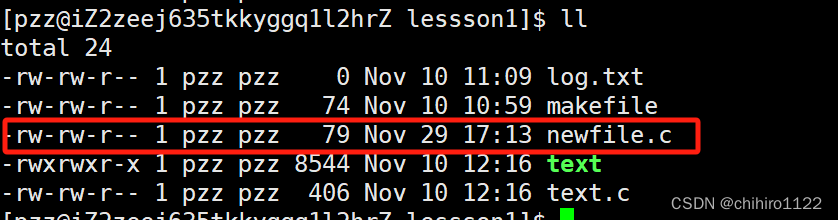
此时,远端主机当中也有了我们上述在 vscode 当中创建的 文件。
此时,我们输入快捷键 : ctrl + ~ ; 就可以打开终端:
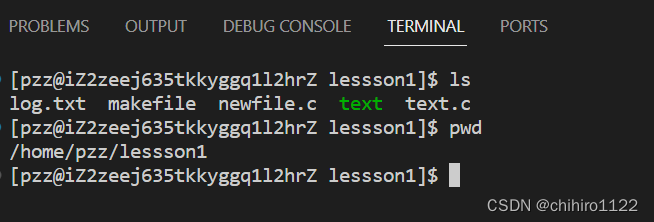
当你,登录上云服务器的话,此时在 vscode 当中安装的插件,就是直接在 云服务器 安装了。
原文地址:https://blog.csdn.net/chihiro1122/article/details/134676107
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_30418.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!