Pipeline
前面我们已经说过,Redis客户端执行一条命令分为如下4个部分:1)发送命令2)命令排队3)命令执行4)返回结果。
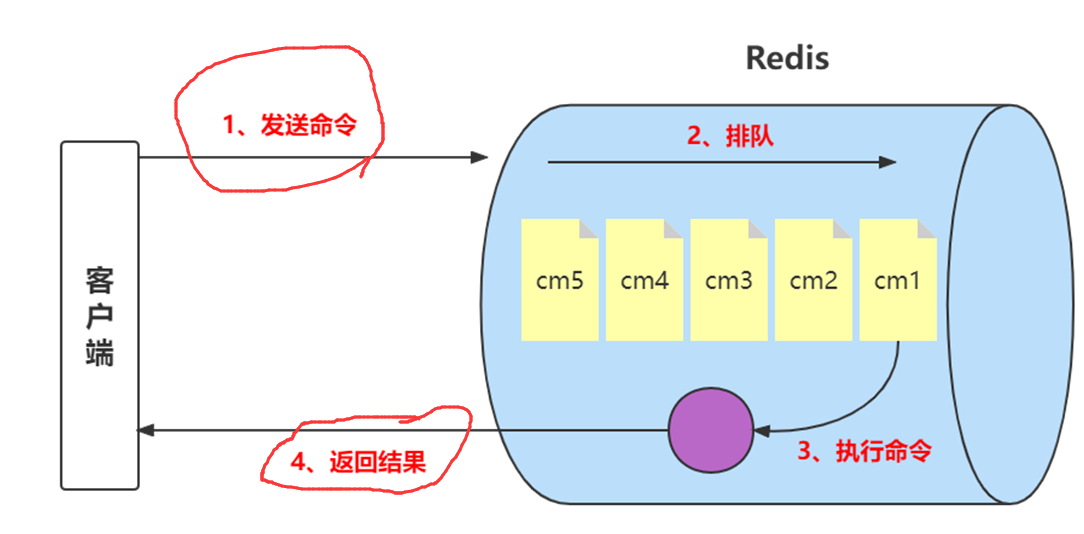
其中1和4花费的时间称为Round Trip Time (RTT,往返时间),也就是数据在网络上传输的时间。
Redis提供了批量操作命令(例如mget、mset等),有效地节约RTT。
但大部分命令是不支持批量操作的,例如要执行n次 hgetall命令,并没有mhgetall命令存在,需要消耗n次RTT。
举例
举例:Redis的客户端和服务端可能部署在不同的机器上。例如客户端在本地,Redis服务器在阿里云的广州,两地直线距离约为800公里,那么1次RTT时间=800 x2/ ( 300000×2/3 ) =8毫秒,(光在真空中传输速度为每秒30万公里,这里假设光纤为光速的2/3 )。而Redis命令真正执行的时间通常在微秒(1000微妙=1毫秒)级别,所以才会有Redis 性能瓶颈是网络这样的说法。
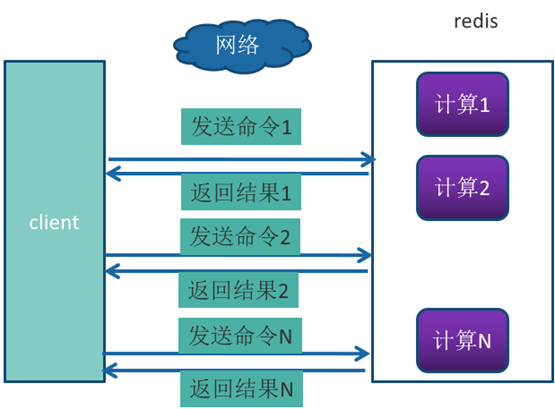
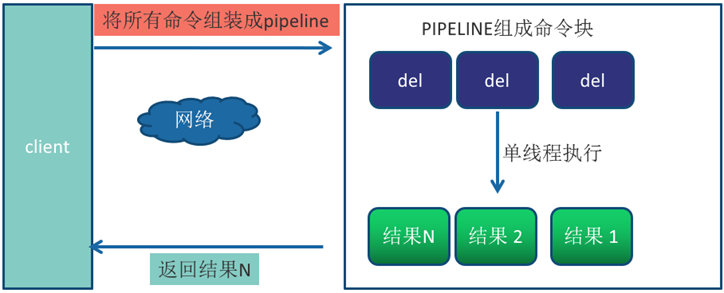
比较普通模式与 PipeLine 模式
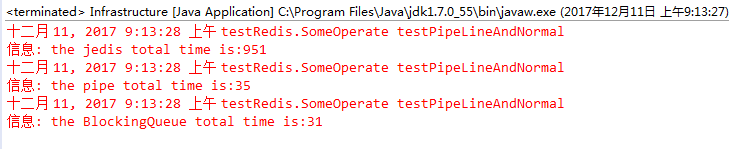
小结:
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






