本文介绍: 随着人工智能技术的不断演进,多模态大模型已是当下比较热的研究方向,它可以同时理解和生成多种输入和输出模态,如文本、图像、语音等,能够更好地模拟人类的多感知能力,给文档图像的分析处理带来了新的机遇和挑战!近期,中国模式识别与计算机视觉大会在厦门举办,是国内顶级的模式识别和计算机视觉领域学术盛会。大会汇聚了国内国外模式识别和计算机视觉理论与应用研究的广大科研工作者及工业界同行,分享我国模式识别与计算机视觉领域的最新理论和技术成果。

前言
近期,中国模式识别与计算机视觉大会在厦门举办,是国内顶级的模式识别和计算机视觉领域学术盛会。大会汇聚了国内国外模式识别和计算机视觉理论与应用研究的广大科研工作者及工业界同行,分享我国模式识别与计算机视觉领域的最新理论和技术成果。通过此次会议,进一步加强本领域的同行与东南沿海地区的学者和企业进行学术交流和技术碰撞,从而促进模式识别与计算机视觉领域的协同合作与融合创新。
合合信息是人工智能及大数据领域的领先企业。在本次大会中合合信息智能技术平台事业部副总经理郭丰俊博士分享了文档图像前沿技术中的成果及探索,主要包括多模态模型以及图像安全,让我们一起来了解一下吧。
一、多模态模型进展与探索
多模态大模型可以用于提高文档图像的处理和分析能力,使文档变得更易于管理、检索和理解。而文档图像是多模态天然的一个属性,它们能够为文档管理、信息提取和文档分析等任务提供有力支持。
1、GPT-4V (多模态)测试
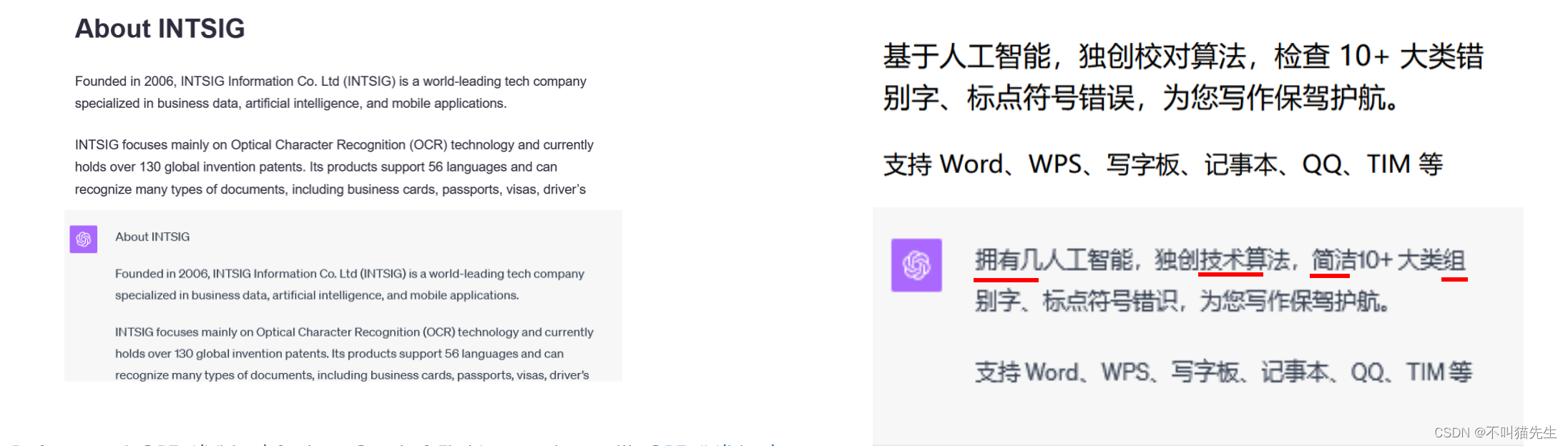
随着 GPT-4V 到来,多模态能力发生了跃迁,不仅能理解文本,还能理解图像。经过初步的测试发现它对英文 OCR 较好,但是对中文 OCR 不理想。GPT-4V 有时会错误地将图像中的两串文字组合在一起,创造出一个虚构的术语。它还会遗漏文字或字符、忽略数学符号,以及无法识别相当明显的物体和地点设置。下图展示了 GPT-4V 的错误识别:
2、LLM时代文档图像处理技术趋势
LLM 时代,文档图像处理技术在不断演进,郭丰俊博士从三个方面来介绍文档图像处理技术趋势:
3、LLM时代文档图像技术机会
4、MLLM时代文档图像处理技术趋势
5、知名文档图像大模型OCR性能分析

二、图像安全

1、篡改种类

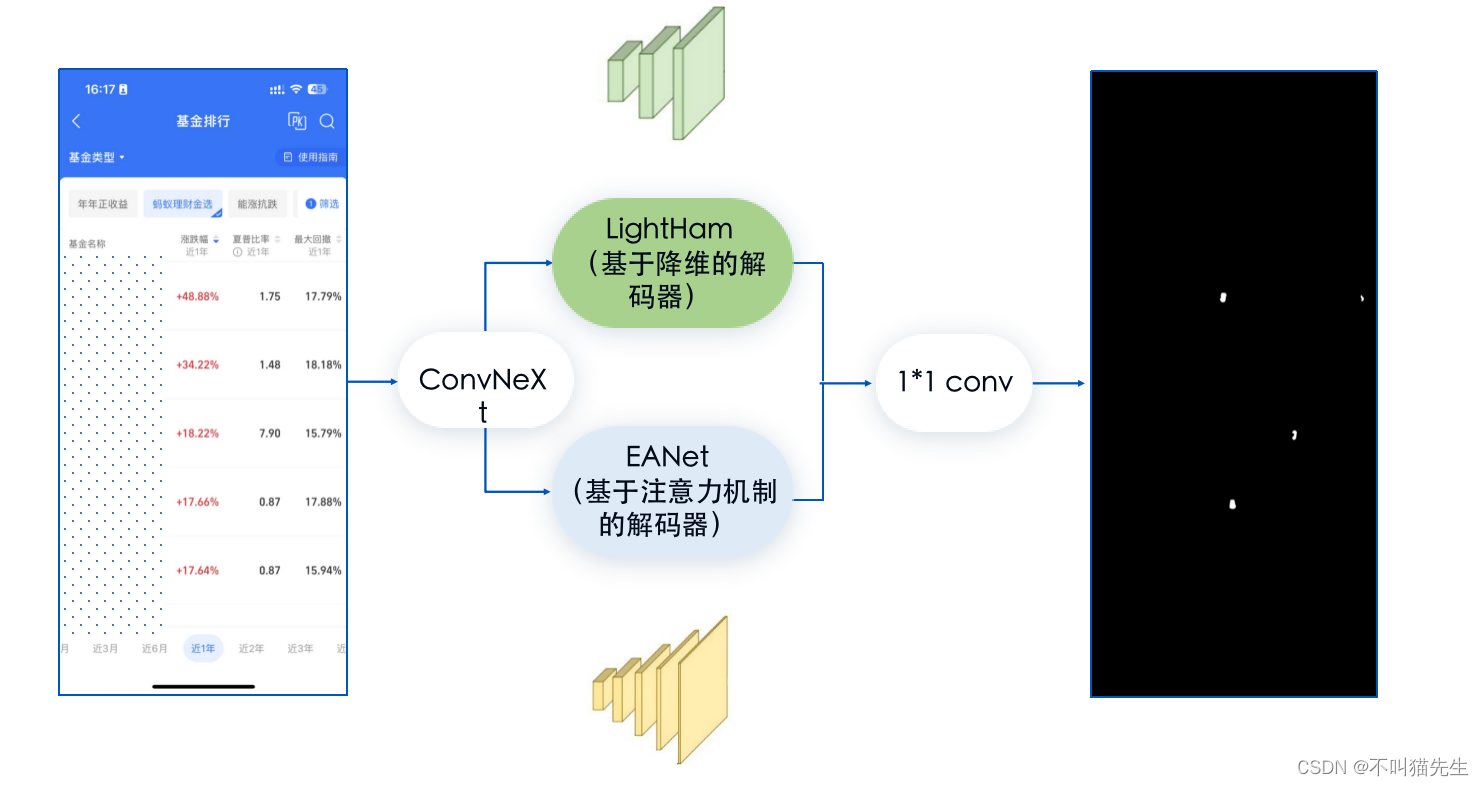
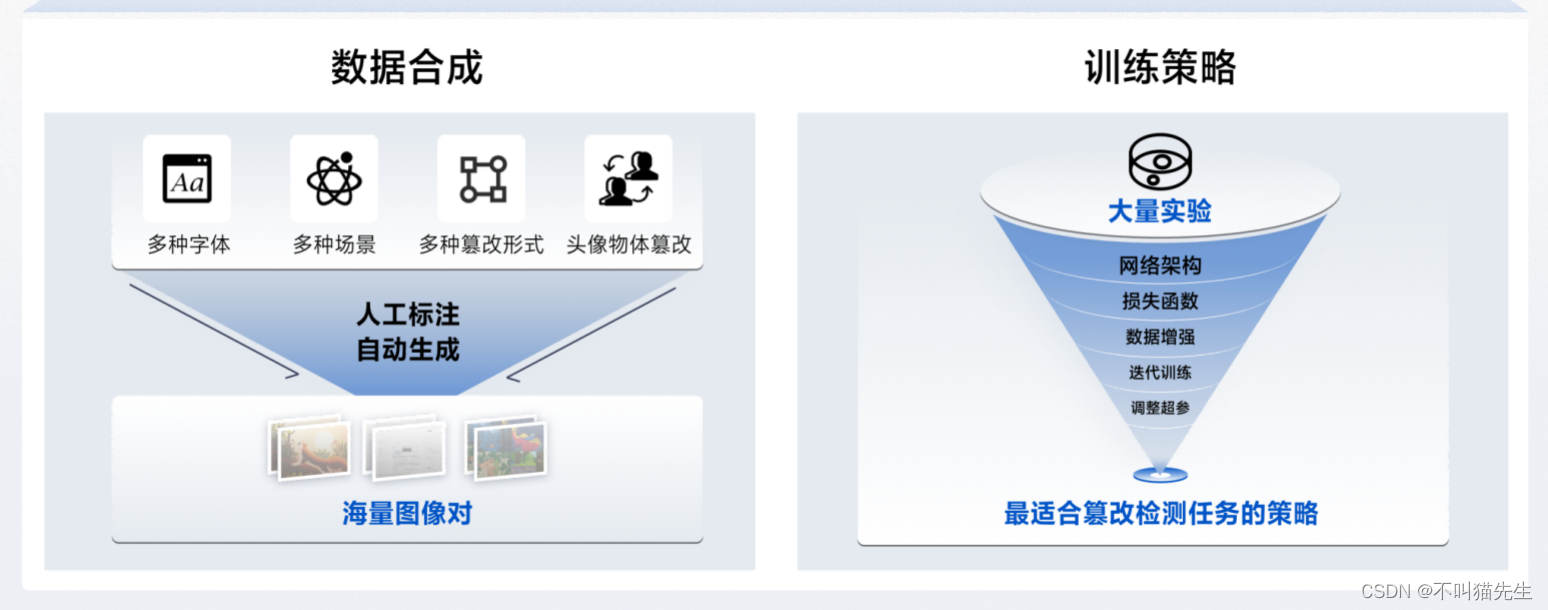
2、系统架构
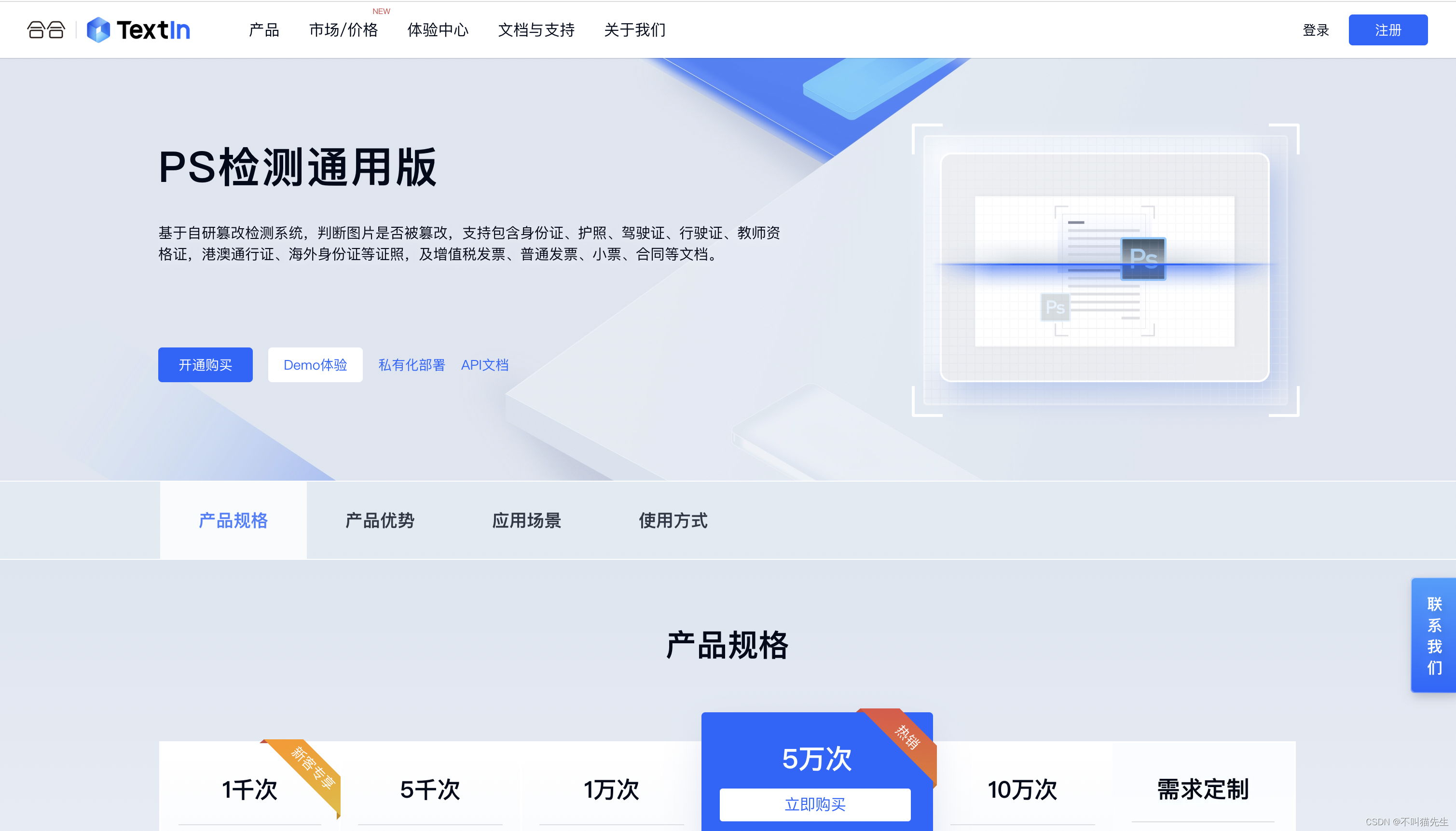
3、文档图像处理开放平台
4、AIGC假图鉴别
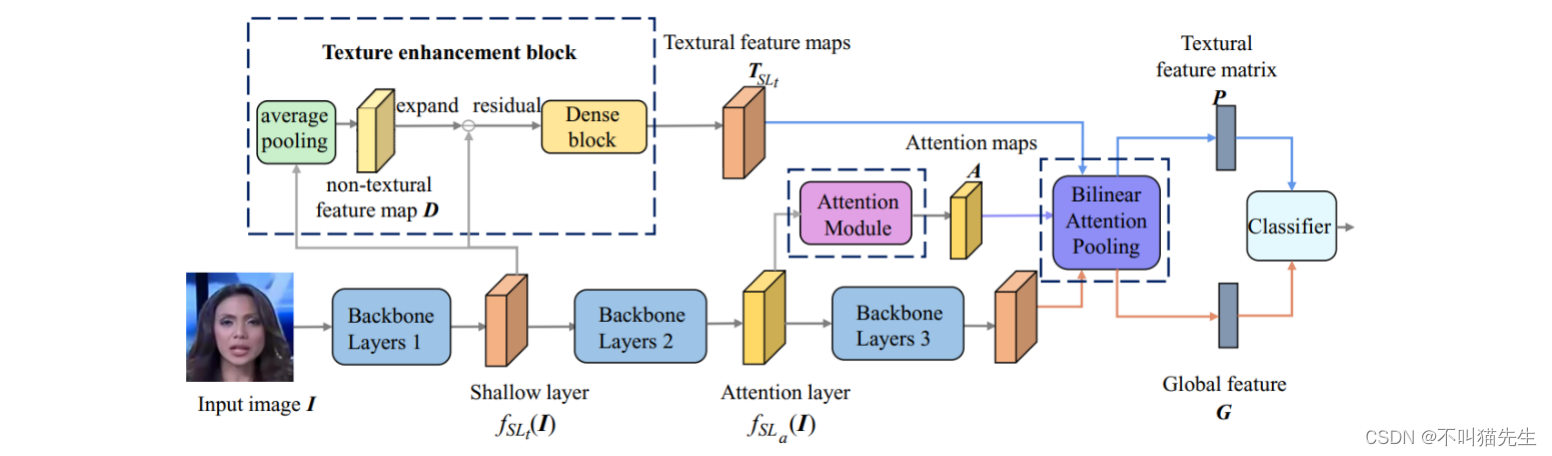
5、图像篡改检测标准制定
最后
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
![[软件工具]文档页数统计工具软件pdf统计页数word统计页数ppt统计页数图文打印店快速报价工具](https://img-blog.csdnimg.cn/direct/09dfbaff3e9a47a9a551dd65fef5d482.jpeg)
![[word] word中怎么插入另外一个word文档 #媒体#职场发展](https://img-blog.csdnimg.cn/img_convert/36ffef6b3060628ccf540a56f6069cb0.png)




