随着信息技术的迅速发展,数据规模逐渐扩大,与此同时,劣质数据也随之而来,极大地降低了数据挖掘的质量,对信息社会造成了严重的困扰,劣质数据大量存在于很多领域和机构,国外权威机构的统计表明:美国的企业信息系统中,1%~30%的数据具有各种错误和误差12.13.6%~81%的关键数据不完整或陈旧情况存在于美国的医疗信息系统中,根据 Gartner 的调查结果:在全球财富 1000 强的企业中超过25%的企业信息系统中存在错误数据。
大多数组织不考虑数据质量,就对大数据平台建设、分析应用等方面的重要影响而盲目投入,也缺乏对大数据资源的整体规划和综合治理,最终导致一些项目实施的终止和失败。因此数据治理越来越被重视。
数据治理的重要前提是建设统一共享的数据平台,信息系统的建设发展到一定阶段,数据资源将成为战略资产,而有效的数据治理才是数据资产形成的必要条件。
同时,在数据共享的时代,享受大数据带来便利的同时也带来如个人隐私泄露的问题,个人隐私信息泄露事件频繁发生,使得人们更加注重保护个人的隐私信息,往往会采取一些措施,如在进行网站注册时故意填写虚假信息,这会影响数据的质量和完整性,低质量的数据将导致低质量的挖掘结果。
因此,数据治理不仅要规范数据,实现数据的价值和管控风险,还要做到隐私保护。
数据治理的研究现状
1.1数据治理的定义
至今为止,数据治理还没有统一标准的定义,IBM 对于数据治理的定义是,数据治理是一种质量控制规程用于在管理、使用、改进和保护组织信息的过程中添加新的严谨性和纪律性。DGI则认为,数据治理是指在企业数据管理中分配决策权和相关职责。
数据治理的目标,总体来说就是提高数据质量,在降低企业风险的同时,实现数据资产价值的最大化,包括:
1.构筑适配灵活、标准化、模块化的多源异构数据资源接入体系;
2.建设规范化、流程化、智能化的数据处理体系;
3.打造数据精细化治理体系、组织的数据资源融合分类体系
4.构建统一调度、精准服务、安全可用的信息共享服务体系
其次,我们还需理解数据治理的职能一一数据治理提供了将数据作为资产进行管理所需的指导,最后,我们要把握数据治理的核心一一数据资产管理的决策权分配和指责分工。
由此可见,数据治理从本质上看就是对一个机构(企业或政府部门)的数据从收集融合到分析管理和利用进行评指导和监督(EDM)的过程,通过提供不断创新的数据服务,为企业创造价值。
数据治理与数据管理是两个十分容易混淆的概念,治理和管理从本质上看是两个完全不同的活动,但是存在一定的联系:
管理是按照治理机构设定的方向开展计划、建设、运营和监控活动来实现企业目标的,而治理过程是对管理活动的评估、指导和监督而管理过程是对治理决策的计划、建设和运营。
数据治理包括评估指导和监督、回答企业决策的相关问题并制定数据规范;
数据管理包括计划建设和运营,实现数据治理提出的决策并给予反馈。
1.2大数据治理一一数据治理新趋势
近年来大数据已成为国内外专家学者研究的热点话题,目前基本上采用IBM 的5V 模型描述大数据的特征:
第1个 V(volume)是数据量大,包括采集、存储和计算的量都非常大;
第 2 个V(velocity)是数据增长速度快,处理速度也快,时效性要求高;
第 3 个 V(variety)是种类和来源多样化,包括结构化、半结构化和非结构化数据;
第4个V(value)是数据价值密度相对较低,可以说是浪里淘沙却又弥足珍贵;
第5个 V(veracity)是各个数据源的质量良养不齐,需要精心甄别。
随着数据量的激增,可以用“5V+I/O”一一体量、速度、多样性、数据价值和质量以及数据在线来概括其特征。这里的“I/O”是指数据永远在线,可以随时调用和计算,这也是大数据与传统数据最大的区别。
2014 年,吴信东等人基于大数据具有异构、自治的数据源以及复杂和演变的数据关联等本质特征提出了HACE定理,该定理从大数据的数据处理、领域应用及数据挖掘这 3 个层次(如图 1 )来刻画大数据处理框架。
框架的第 1层是大数据计算平台,该层面临的挑战集中在数据存取和算法计算过程上;
第 2 层是面向大数据应用的语义和领域知识,该层的挑战主要包括信息共享和数据隐私、领域和应用知识这两个方面;
架构的第3层集中在数据挖掘和机器学习算法设计上:稀疏不确定和不完整的数据挖掘、挖掘复杂动态的数据以及局部学习和模型融合。
以第 3 层的 3 类算法对应3 个阶段:首先,通过数据融合技术对稀疏、异构、不确定、不完整和多源数据进行预处理;其次,在预处理之后,挖掘复杂和动态的数据:最后通过局部学习和模型融合获得的全局知识进行测试,并将相关信息反馈到预处理阶段,预处理阶段根据反馈调整模型和参数。

目前比较权威的大数据治理定义是:大数据治理是广义信息治理计划的一部分,它通过协调多个职能部门的目标,来制定与大数据优化、隐私与货币化相关的策略。
1.海量数据存储:根据本地实际数据量级和存储处理能力,结合集中式或分布式等数据资源的存储方式进行构建,为大数据平台提供 PB 级数据的存储及备份能力支撑.云计算作为一种新型的商业模式,它所提供的存储服务具有专业、经济和按需分配的特点,可以满足大数据的存储需求;
2.处理效率:大数据治理提供多样化的海量数据接入及处理能力,包括对各类批量、实时、准实时及流式的结构化、非结构化数据提供快速的计算能力和搜索能力,比如数据加载能力≥130MB/s、亿级数据秒级检索、百亿数据实时分析≤10s、千亿数据离线分析≤30m 等等。对于大数据的搜索能力方面,为了保证数据安全,大数据在云计算平台上的存储方式一般为密文存储,因此研究人员设计了很多保护隐私的密文搜索算法,基于存储在云平台上大数据的计算安全问题的解决方法一般采用比较成熟的完全同态加密算法;
3.数据可靠性:围绕行业数据元相关标准规定,基于行业元数据体系打造大数据平台采集汇聚、加工整合、共享服务等全过程的、端到端的数据质量稽核管控体系,确保数据准确可靠;
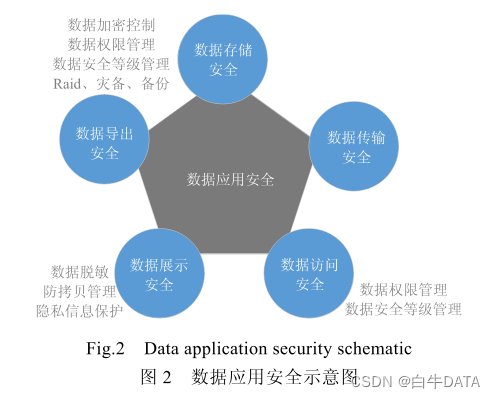
4.数据安全性:数据价值是大数据平台的核心价值,所以数据的安全是保证平台运行的基础。数据安全包括数据存储的安全、数据传输过程中的安全,数据的一致性、数据访问安全等。如图 2 所示,数据安的总体目标是保证数据的存储、传输、访问、展示和导出安全.数据安全措施主要有数据脱敏控制、数据加密控制、防拷贝管理、防泄漏管理、数据权限管理、数据安全等级管理等。
而数据治理技术就是在数据治理的过程中所用到的技术工具,其中主要包括数据规范、数据清洗、数据交换和数据集成这 4 种技术。
数据规范
2.1数据规范的含义
数据治理的处理对象是海量分布在各个系统中的数据,这些不同系统的数据往往存在一定的差异:数据代码标准、数据格式、数据标识都不一样,甚至可能存在错误的数据,这就需要建立一套标准化的体系,对这些有在差异的数据统一标准,符合行业的规范,使得在同样的指标下进行分析,保证数据分析结果的可靠性。
数据的规范化能够提高数据的通用性、共享性、可移植性及数据分析的可靠性,所以,在建立数据规范时要具有通用性,遵循行业的或者国家的标准。
2.2数据规范方法
数据治理过程中可使用的数据规范方法有:规则处理引擎、标准代码库映射。
数据治理为每个数据项制定相关联的数据元标准,并为每个标准数据元定义一定的处理规则,这些处理逻辑包括数据转换、数据校验、数据拼接赋值等。基于机器学习等技术.对数据字段进行认知和识别,通过数据自动对标技术,解决在数据处理过程中遇到的数据不规范的问题。
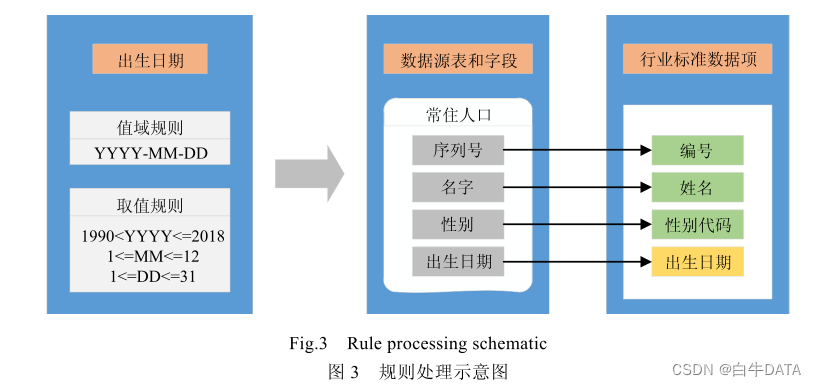
根据数据项标准定义规则模板.图 3 中“出生日期”的规则如下所示。
值域稽核规则:YYYY:MM:DD或YYYY-MM-DD;
取值范围规则:1900<YYYY<=2018,1<=MM<=121<=DD<=31。
将数据项与标准库数据项对应。
借助机器学习推荐来简化人工操作,根据语义相似度和采样值域测试,推荐相似度最高的数据项关联数据表字段,并根据数据特点选择适合的转换规则进行自动标准化测试。根据数据项的规则模板自动生成字段的稽核任务。
规则体系中包含很多数据处理的逻辑:将不同数据来源中各种时间格式的数据项,转化成统一的时间戳格式;对数据项做加密或者哈希转换;对身份证号做校验;将多个数据项通过指定拼接符号连接成一个数据项;将某个常量或者变量值喊给某个数据项等
规则库中的规则可以多层级迭代,形成数据处理的一条规则链,规则链上,上一条规则的输出作为下一条规则的输入,通过规则的组合,能够灵活地支持各种数据处理逻辑。
(2)标准代码映射
标准代码库是基于国标或者通用的规范建立的 key–value 字典库,字典库遵循国标值域、公安装备资产分类与代码等标准进行构建。当数据项的命名为 XXXDM(XXX 代码)时。根据典库的国标或部标代码。通过字典规则关联出与代码数据项对应的代码名称数据项XXXDMMC(XXX 代码名称)。
原文地址:https://blog.csdn.net/WhiteCattle_DATA/article/details/134576799
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_3078.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!







