| 表达式 | 描述 |
|---|---|
| nodename | 选中该元素 |
| / | 从根节点选取、或者是元素和元素间的过渡 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
| text() | 选取文本 |
举例:
| 路径表达式 | 结果 |
|---|---|
| html | 选择html元素 |
| /html | 选取根元素 html。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| /html/body/ul/li | 选取属于 ul的子元素的所有 li元素 |
| //li | 选取所有 li元素,而不管它们在文档中的位置 |
| /html//li | 选择属于 html元素的后代的所有 li元素,而不管它们位于 html之下的什么位置 |
| //li//a/@href | 选择所有的li下面的a标签中的href属性的值 |
| //li//a/text() | 选择所有的li下面的a标签的文本 |
2. 寻找特定节点:
| 路径表达式 | 结果 |
|---|---|
| //span[@class=“s2”] | 选择class属性值为s2的所有span标签 |
| //ul/li[1] | 选取属于 ul子标签的第一个 li标签。 |
| //ul/li[last()] | 选取属于 ul子标签的最后一个 li标签。 |
| //ul/li[last()-1] | 选取属于 ul子标签的倒数第二个 li标签。 |
| //ul/li[position()>1] | 选择ul下面的li标签,从第二个开始选择 |
| //li/span/a[text()=‘无墟极道’] | 选择所有li下的span标签,仅仅选择文本为 无墟极道 的a标签 |
敲黑板: 在xpath中,第一个元素的位置是1,最后一个元素的位置是last(),倒数第二个是last()-1
以上仅供参考,实用才是王道
一.在大多数标准网站中对于文本的提取
一般只需:相对标签+class属性值
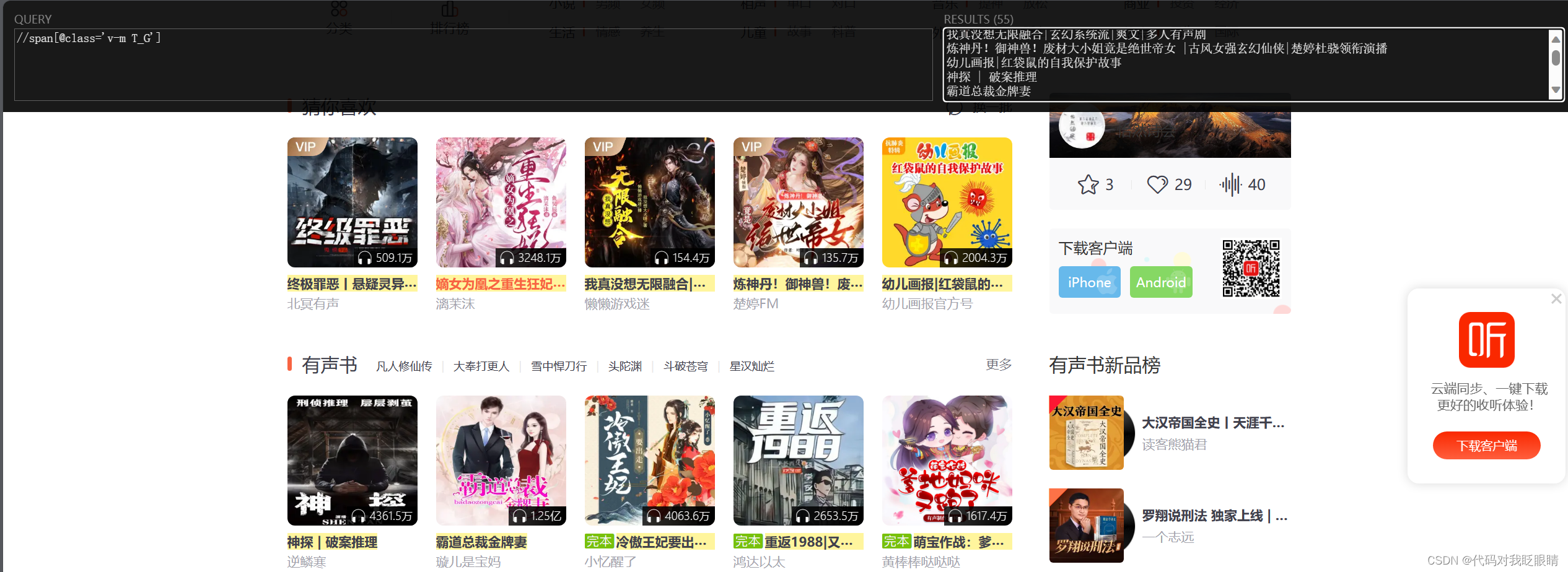
eg.提取喜马拉雅的发现页面的书名
//span[@class='v-m T_G']

二.对于链接的提取一般只需:相对标签+class属性值+标签中内容所在的属性值
eg.提取喜马拉雅的发现页面的书籍封面链接
//img[@class='img _hW']/@src
 2. 上方
2. 上方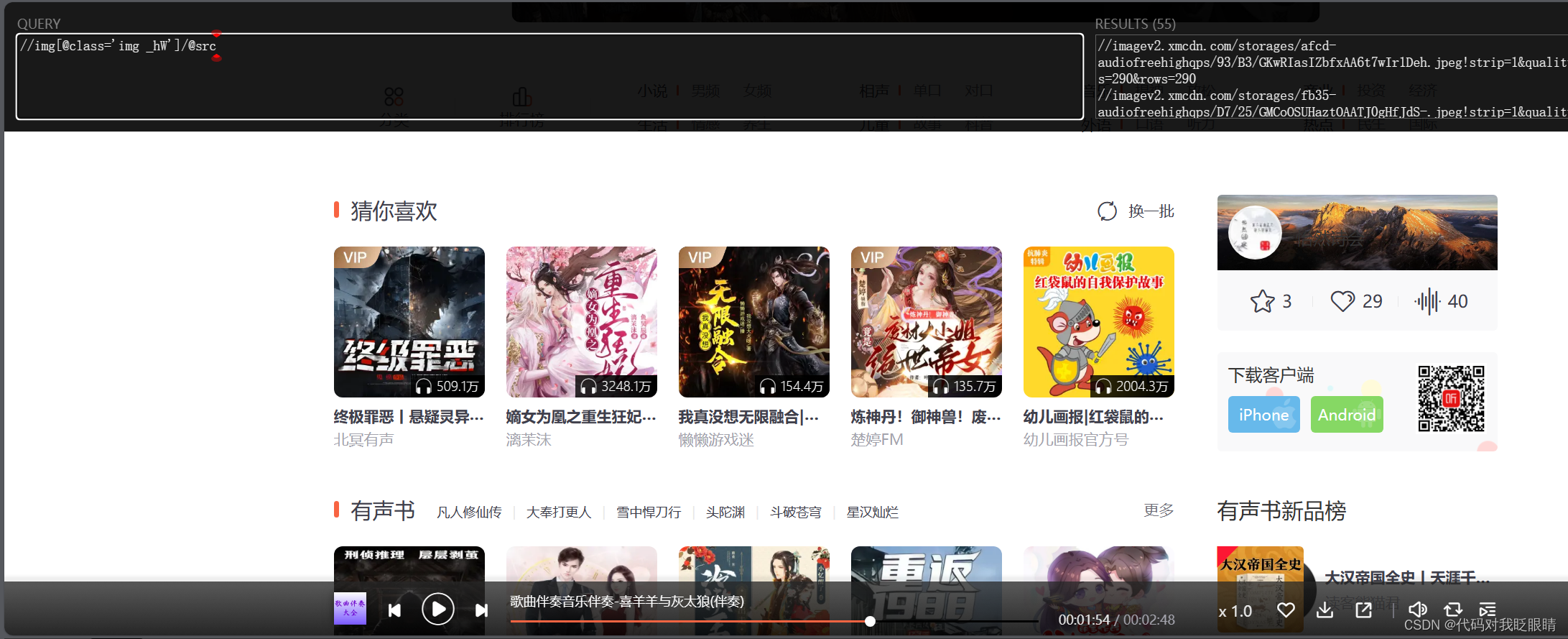
原文地址:https://blog.csdn.net/m0_73756108/article/details/134747336
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_31086.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。