目标检测:我们希望找到图像中的不同实例并将它们分配给某一个类别。实例可以部分重叠,但仍然可以区分为不同的实例。如图(1)所示,在输入图像中找到三个实例并将其分配给某一个类别。

实例分割是目标检测的一种特殊情况,其中模型还预测了实例的掩码(即在图像的特定区域中标记出该实例)。如图(2)所示,在输入图像中找到三个实例,每个实例被分配到一个类,并获得一个标识其特定区域的掩码。

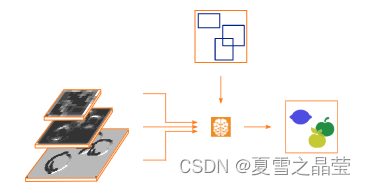
目标检测有两个不同的任务,查找(/定位)实例,并对查找到的实例进行分类。为此,我们采用一个包含三个主要部分的组合网络,来实现目标检测。第一部分称为骨干网络,它由一个预训练的分类网络(不包括分类层)组成。随着网络的加深,在不同的尺度上,生成不同的特征映射;第二部分称为特征金字塔,与第一部分一起构成特征金字塔网络。将第一部分中不同级别(具有相同宽度和高度的特征映射被称为属于同一级别)的特征映射组合在一起,得到了包含低级和高级信息的特征映射;第三部分为每一层所选的额外网络,称为头。它们以相应的特征映射作为输入,学习如何对目标进行定位(对重叠边框进行抑制)和分类。

上述三部分原理图如图(3)所示。图(3-1)为主干网络;图(3-2)对骨干特征图进行合并,生成新的特征图;图(3-3)附加网络(称为头部),学习如何对目标进行定位和分类。
在目标检测的第三部分附加网络中,实例在图像中的位置是由矩形边界框给出的。因此,首要任务是为每个实例找到一个合适的边界框。为了做到这一点,网络生成参考边界框(锚框),并学习如何修正它们,使其最适合地定位出实例。这些锚框越好的表示不同的ground truth边界框的形状,网络就越容易学习它们。为此,网络在每个锚点上生成一组锚框。这样的一组锚框包括形状、大小和方向的所有组合。这些锚框的形状由参数‘anchor_aspect_ratio‘控制,大小由参数‘anchor_num_subscales‘控制,方向由参数‘anchor_angles‘的控制。如果参数生成多个相同的锚框,则网络会在内部忽略这些重复的锚框。具体的参见get_dl_model_param()算子。

在图(4-1)中,锚框是在不同层级的特征图上创建的,例如在特征图上绘制的浅蓝色、橙色、和深蓝色的锚框;在图(4-2)中,设置参数‘anchor_num_subscales‘来创建不同大小的锚框;在图(4-3)中,设置参数’anchor_aspect_ratio‘来创建不同形状(长宽比不一样)的锚框;在图(4-4)中,设置参数’anchor_angles‘来创建不同方向的锚框(仅用于实例类型‘rectangle2′)。
网络预测了如何修改锚框,以获得更好地拟合实例的边框。它将生成的锚框与相应的ground truth边框进行比较,从而得到图像中单个实例的位置信息。
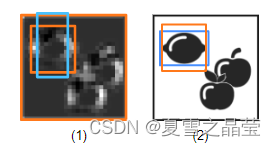
在图(5-1)中,网络修正浅蓝色的锚框,以预测出更好拟合效果的橙色边界框;在图(5-2)中,在训练过程中,将预测的边界框(橙色)与重叠最多的ground truth边界框(蓝色)进行比较,使网络能够学习到必要的修正(偏移量)。
如前所述,我们使用了不同层次的特征图。比如,较低层次的特征图(可以看到小特征)和较深层次的特征图(只有大特征可见)。它们可以通过参数’min_level‘和’max_level‘来控制,它们决定了特征金字塔的层级。
通过这些边界框,我们可以定位出实例对象,但实例还没有被分类。因此,第二项任务包括对边界框中的实例进行分类,这是由附加网络来完成的。网络很可能会为单个实例找到多个边界框,可以通过非最大值抑制来筛选边界框。最后输出一个带有置信度的预测框,表示此图像中的实例与其中某一个类的相关性。

图(6) 实例类型为’rectangle1’的重叠边界框抑制
在图(6-1)中,网络分别为实例苹果(橙色)和实例柠檬(蓝色)找到了多个预测框;在图(6-2)中,设置参数’max_overlap‘,用于抑制同一类实例的重叠预测框,不同类的实例重叠预测框不会被抑制;在图(6-3)中,设置参数’max_overlap_class_agnostic‘也可以抑制不同类的实例的重叠预测框。
实例分割的进一步内容如下:获得与预测边界框相对应的特征映射的那些部分作为一个额外网络(头部)的输入,由此预测出一个二值掩模图像的类别。此掩码标记了图像中属于预测实例的区域。其概述如图(7)所示。
1.2 目标检测通用工作流程
在本节中,我们描述了基于深度学习的目标检测任务的一般流程。它分为四个部分:数据预处理和模型创建、模型训练、模型评估和模型推理。HDevelop示例中detect_pills_deep_learning的应用程序显示了目标检测的完整工作流程;HDevelop示例中dl_instance_segmentation_workflow的应用程序显示了实例分割的完整工作流程。
① 在HDevelop示例detect_pills_deep_learning_1_prepare.hdev中展示了目标检测模型的创建以及数据预处理。使用determine_dl_model_detection_param()函数估计适合于数据集的参数(比如锚参数)。对于实例分割,必须设置参数’instance_segmentation‘以创建相应的模型;使用create_dl_model_detection()算子创建目标检测模型。该算子需要有指定主干网络的参数、类别数目参数、在DLModelDetectionParam字典上设置的其他参数。最后,该算子返回一个句柄‘DLModelHandle’;可以使用read_dl_model算子读取已经用write_dl_model保存的模型。
② 可以使用read_dict()算子读取DLDataset字典中数据,或者使用read_dl_dataset_from_coco()函数读取的一个COCO数据格式的文件,并由此创建一个字典DLDataset。字典DLDataset充当一个数据库,存储关于数据的所有必要信息。
③ 使用split_dl_dataset()函数来拆分字典DLDataset所表示的数据集。产生的拆分将在字典DLDataset中的样本字典中通过新键’split‘加以区分保存。
④ 网络对输入图像有一定的要求,比如图像的宽度和高度。可以使用get_dl_model_param()算子检索每个单独的值。可以使用函数create_dl_preprocess_param_from_model()检索所有必要的参数。注意,对于由’class_ids_no_orientation‘声明的类,边界框需要在预处理期间进行特殊处理。可以使用preprocess_dl_dataset()函数对数据集进行预处理。可以使用dev_display_dl_data()函数对预处理后的数据进行可视化。
(2)模型训练
在HDevelop示例detect_pills_deep_learning_2_train.hdev中展示了目标检测模型的训练。
① 设置训练参数并将它们存储在字典TrainingParam中。
② 使用train_dl_model()函数训练模型。该函数参数有:模型句柄DLModelHandle、包含DLDataset数据信息的字典、带有训练参数TrainingParam的字典、和epochs等。
(3)训练模型的评估
在HDevelop 示例detect_pills_deep_learning_3_evaluate.hdev中展示了目标检测模型的评估。
② 使用evaluate_dl_model()函数可以方便地对模型进行评估。该函数需要一个带有计算参数的字典GenParamEval,将参数detailed_evaluation设置为’true‘以获取可视化所需的数据。
③ 可以使用dev_display_detection_detailed_evaluation()函数对评估结果可视化。
(4)对新图像进行推理
在HDevelop示例detect_pills_deep_learning_4_infer_hdev中展示了深度学习目标检测模型的推理。
① 使用算子get_dl_model_param()或者函数create_dl_preprocess_param_from_model()获取网络对输入图像要求的参数。
② 使用算子set_dl_model_param()设置模型参数和超参数。
③ 使用gen_dl_samples_from_images函数()为每个图像生成一个数据字典DLSample。
④ 使用preprocess_dl_samples()函数对每张图像进行预处理。
⑤ 使用算子apply_dl_model()进行模型推理,并从字典’DLResultBatch’中检索出推理结果。
1.3 目标检测其他补充说明
(1) 数据(Data)
我们区分用于训练和评估的数据(包含实例信息的图像)和用于推理的数据(裸露图像)。对于前者,定义出每个实例属于哪个类以及它在图像中的位置(通过它的边界框)。实例分割需要目标的像素级精确区域(通过掩码提供)。
(2) 用于训练和评估的数据(Data for training and evaluation)
训练的数据用于特定任务的训练和评估网络。有了这些数据,网络可以知道哪些类应该被区分,这样的实例是什么样子的,以及如何找到它们。通过告诉每个图像中的每个对象属于哪个类以及它位于何处,可以提供必要的信息。这是通过为每个对象提供一个类标签和一个边界框来实现的。在实例分割的情况下,每个实例都需要一个掩码。有不同的方法来存储和检索这些信息。简而言之,字典DLDataset可作为训练和评价程序所需信息的数据库。可以使用MVTec深度学习工具(可从MVTec网站获得)以各自的格式标记你的数据并直接创建字典DLDataset。如果你已经用标准的COCO格式标记了你的数据,你可以使用函数read_dl_dataset_from_coco (仅适用’instance_type‘ = ‘rectangle1′)来格式化数据并创建字典DLDataset。还需要足够的训练数据来将其划分为三个子集,用于训练、验证和测试网络。这些子集最好是独立的、同分布的。注意,在目标检测中,网络必须学习如何找到实例的可能位置和大小。这就是为什么后面重要的实例位置和大小需要在你的训练数据集中有代表性地出现。
不管应用程序如何,网络都对图像提出了要求,例如图像的尺寸。具体的值取决于网络本身,可以使用get_dl_model_param()函数进行查询。可以使用preprocess_dl_dataset()函数对单个样本进行预处理,使用preprocess_dl_samples()函数对整个数据集进行预处理。
根据目标检测模型的实例类型,对边界框进行不同的参数化:
边界框定义为左上角(‘bbox_row1’,’bbox_col1′)和右下角(‘bbox_row2’, ‘bbox_col2′)坐标。这与算子gen_rectangle1()一致。
边界框定义为中心坐标(‘bbox_row‘,’bbox_col‘),方向’Phi‘和边长’bbox_length1’和’bbox_length2’。方向定义为水平轴与’bbox_length1′(数学上为正)之间的夹角(单位弧度)。这与算子gen_rectangle2一致。
如果在’rectangle2’的情况下,只对定向边界框感兴趣,但不考虑边界框内对象的方向,则参数’ignore_direction‘可以设置为’true‘。
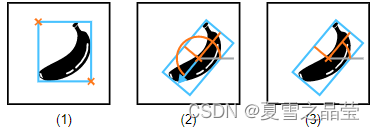
图(8-1) 为实例类型“rectangle1”;图(8-2)为实例类型“rectangle2”,其中边界框朝向香蕉端。图(8-3)为实例类型“rectangle2”,在不考虑香蕉在矩形框中的方向的情况下,我们只对矩形框的方向感兴趣。
实例分割除了需要一个紧密的边界框外,还需要学习每个对象的掩模。这样的掩模是一个区域(注意,这些区域是相对于图像给出的)。在图(9)中,单个图像的掩码以区域对象元组的形式给出(tupel中包含每个要学习的对象的独立区域)。

作为输出,算子train_dl_model_batch()将返回一个字典DLTrainResult,其中包含总损失的当前值以及模型中包含的所有其他的损失值。
② 网络输出取决于任务:inference and evaluation
函数apply_dl_model()将为每个图像返回一个字典DLResult。对于目标检测,该字典将包括每个检测到的实例的边界框和指定类的置信值,以及在实例分割情况下的掩码。因此,对于图像中的同一对象可以检测到多个实例,参见上面对非最大抑制的解释。生成的边界框根据实例类型(在’instance_type‘上指定)进行参数化,并以像素为中心的亚像素精确坐标给出。
(7) 模型参数和超参数(Model Parameters and Hyperparameters)
除了深度学习中解释的一般深度学习超参数之外,还有与目标检测相关的超参数:
‘bbox_heads_weight‘、’class_heads_weight‘、’class_weights‘和’mask_head_weight‘(在实例分割的情况下)。这些超参数在get_dl_model_param()函数中有更详细的解释,并使用create_dl_model_detection对其进行设置。
对于目标检测模型,有两种不同类型的模型参数:固定参数(一旦创建了模型,它们就不能再更改了)和可变参数。只与目标检测相关的参数,’max_num_detections’、’max_overlap‘、’max_overlap_class_agnostic‘和’min_confidence‘,它们会影响评估和预测的结果。可以在创建模型时使用create_dl_model_detection()函数或在创建模型后使用set_dl_model_param进行参数设置。
(8 ) 目标检测结果的评价方法(Evaluation measures for the Results from Object Detection)
对于目标检测,HALCON支持以下评估方法。为了对图像进行评估度量,需要相关的ground truth信息。
① IoU交并比
IOU的全称为交并比(Intersection over Union),是目标检测中使用的一个概念,如图(10)所示,IoU计算的是预测边框和真实边框的交集与它们并集的比值。其中,蓝色为predicted box,橙色为 ground truth box。最理想情况下,IoU=1。

图(10) IoU计算示例图
T/F:表示样本是否被分类正确;T:分类正确;F:分类错误。
P/N:表示样本原来是正样本还是负样本;P:样本原来是正样本;N:样本原来是负样本。
True Positives (TP: predicted positive, labeled positive):被分配为正样本,而且分对了(预测对了,原来就为正样本)。代表的是被正确分类的正样本,即IoU > IoUthreshold 的检测框数量(同一Ground Truth只计算一次)。TP示例图如图(11)所示。

图(11) TP示例图
False Positive due to Location and Class (FP mult):预测框和真实标注框的IoU小于所需最小的IoUthreshold即预测的位置是错误的,同时预测的类别也是错误的。FP mult示例图如图12所示。

图(12) FP mult示例图
False Positives due to Misclassification (FP class):预测框和真实标注框的IoU大于所需最小IoUthreshold ,但是它的预测类别是错误的。FP classs示例图如图(13)所示。

图(13)FP classs示例图
False Positive due to Wrong Location (FP loc):预测框和真实标注框的IoU不为零且低于最小的IoUthreshold,并且预测的类别是正确的,但是预测的位置被认为是错误的。FP loc示例图如图(14)所示。

图(14)FP loc示例图
False Positive due to Duplicate Detections (FP dup):如果IoU高于最低IoU,但存在另一个具有更高分数的同类检测,则认为是重复检测的。

图(15) FP dup示例图
False Positive on Background(FP bg):如果预测框(predicted boxes)与所有GT( ground truth boxex)的IoU为零,即它与任何ground truth boxex都没有重叠,则认为它是假阳性背景检测(False Positive on Background, FP bg)。FP bg示例图如图(16)所示。

图(16) FP bg示例图
False Negative(FN):对于含有标注框的对象没有被true positive 检测,则会发生 false negative。
对于’class_id‘ = 5和’class_id’ = 8的类别,我们有false negative,这些类别有真实的标注框,但它们没有被true positive 检测。FN示例图如图(17)所示。

图(17) FN示例图
True Negatives (TN: predicted negative, labeled negative):被分配为负样本,而且分对了(原来就是负样本)。代表的是被正确分类的负样本,在mAP评价指标中不会使用到。
False Positives (FP: predicted positive, labeled negative):被分配为正样本,但是分错了(事实上这个样本为负样本)。代表的是被错误分类的负样本,IoU <= IoUthreshold 的检测框,或者是检测到同一个GT的多余检测框的数量。
False Negatives (FN: predicted negative, labeled positive):被分配为负样本,但分错了(事实上这个样本是正样本)。代表的是被错误分类的正样本,没有检测到的GT的数量。
FN:分类器认为是负样本,但实际上不是负样本的例子;
Precision(精确率)就是分类器认为是正类并且确实是正类的例子与分类器认为是正类的所有例子的比值;Precision=TP/(TP+FP)=TP/预测框总数;Precision(精确率)就是找的对,通常精确率越高,分类器越好。
Recall(召回率)就是分类器认为是正类并且确实是正类的部分占所有确实是正类的比例;Recall=TP/(TP+FN)=TP/GT框数量;Recall(召回率)就是找的全,通常召回率越大,漏检率越低。
Accuracy(准确率):结果预测正确的数量占样本总数的比例;Accuracy=(TP+TN)/(TP+TN+FP+FN)
如图(18)所示,可以看出网络对每个类的执行情况。对于每个类,它列出了预测到哪个类的实例数量。例如,对于区分’苹果‘、’桃子’和’梨’这三个类别的分类器,混淆矩阵展示了具有多少ground truth的 ‘苹果‘类图像被分类为’苹果’;有多少被分类为’桃子’或’梨’。在HALCON中,每一列表示某类具有 ground truth label的实例,并在一行中表示预测属于该类的实例。

从图(11)中可以看出68张’苹果’图片被归类为’苹果'(TP); 60张不是’苹果’的图片被正确归类为’桃子'(30张)或’梨'(30张)(TN); 0张显示’桃子’或’梨的图片被归类为’苹果'(FP); 24张’苹果’的图片被错误地归类为’桃子'(21张)或’梨'(3张)(FN)。
④ AP (average precision):每个类别的平均精度计算为精确率-召回率曲线下的面积。
⑤ mean_ap(Mean average precision,mAP):所有类的平均AP的平均值。如图19所示。在训练期间或对不同模型进行比较时,采用‘mean_ap’来评估检测模型的性能。
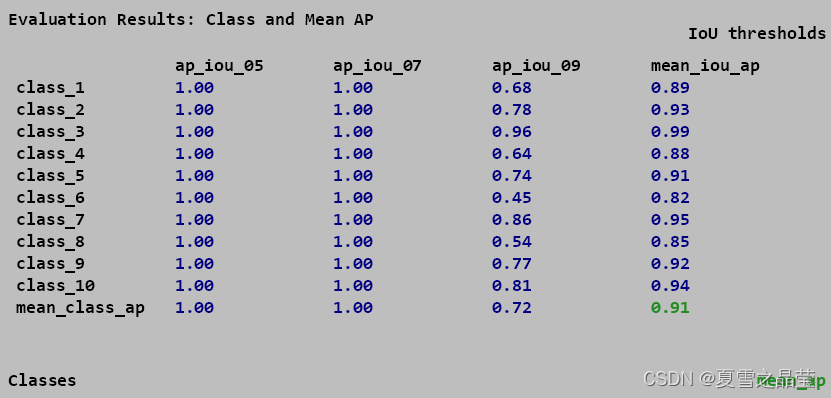
图(19) 三个IoU阈值的示例评估结果
原文地址:https://blog.csdn.net/qq_44744164/article/details/134747574
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_31148.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!