前言
文章定位是能够为初学者提供一个快速入门的参考,同时记录了我在工作中使用kettle的经验和总结。文章内容会持续更新,希望能够给大家提供一些帮助,同时也欢迎大家一体探索kettle的各种奇技淫巧~~~。另外我在kettle的使用过程中经常会参考kettle中文网,我在这个网站上学习到很多有用的知识。
一、kettle是什么
Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。kettle中文名称叫水壶。主要用作数据抽取,转换工作。
二、kettle 安装与基本使用
2.1 kettle 安装
前面提到 kettle是java编写,在安装之前需要先安装jdk环境,建议jdk版本保持在1.8及以上。把kettle安装包解压放到指定文件夹目录下,进入 kettle-pdi–ce-9.0.0.0-423data–integration目录,双击运行Spoon.bat脚本即可打开kettle开发页面。

稍等片刻后,kettle程序启动完成,下图就是kettle的工作页面:
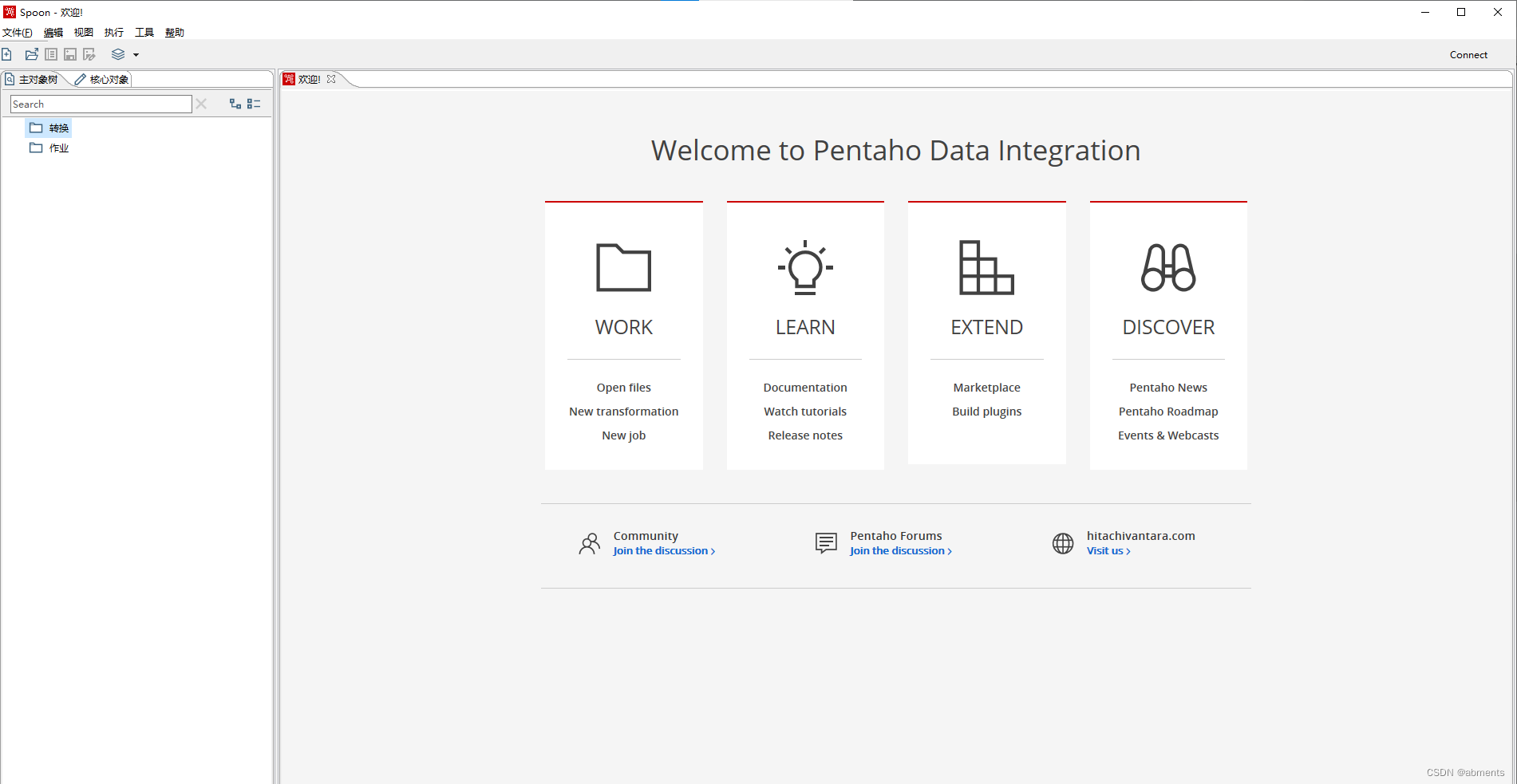
2.2 kettle的基础使用
点击文件下的新建图片,弹出下拉框,选择转换功能,弹出转换编辑页面。

2.21 做一个简单的转换样例
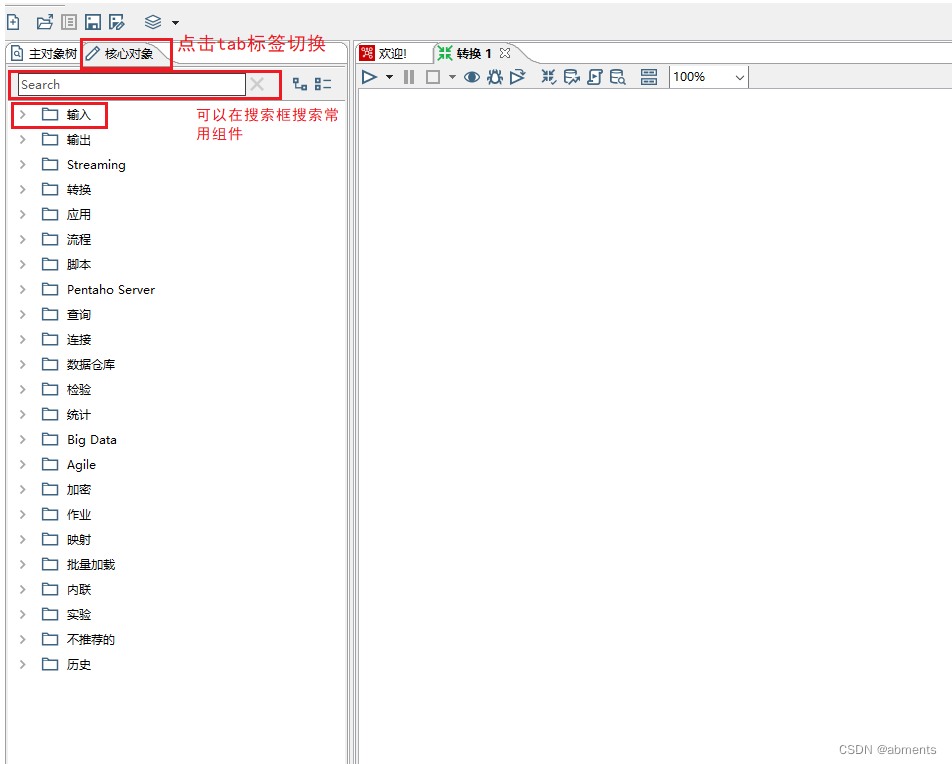
通过点击tab标签切换主对象树和核心对象树,在初学阶段主要关注核心对象树。可以通过点击模块左边的箭头展开模块内容,也可以通过搜索框输入组件名对组件进行模糊搜索。

2.2.2 小技巧

三、转换常用组件使用
转换侧重于数据流的处理。它处理抽取,转换,加载各阶段各种对数据行的操作。转换包括一个或者多个步骤(step),如读取文件,过滤输出行,数据清洗或者将数据加载到数据库。
3.1 输入模块
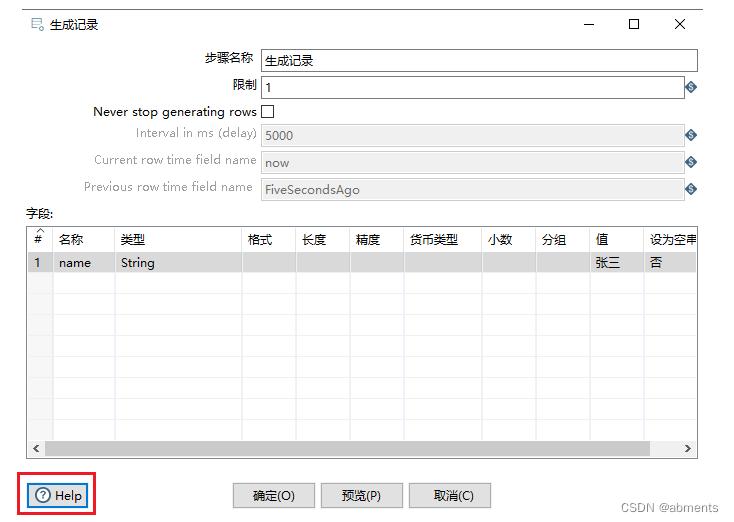
3.1.1 生成记录
1.作用:
生成一些空记录或者相等的行
2.用法:


3.用途:
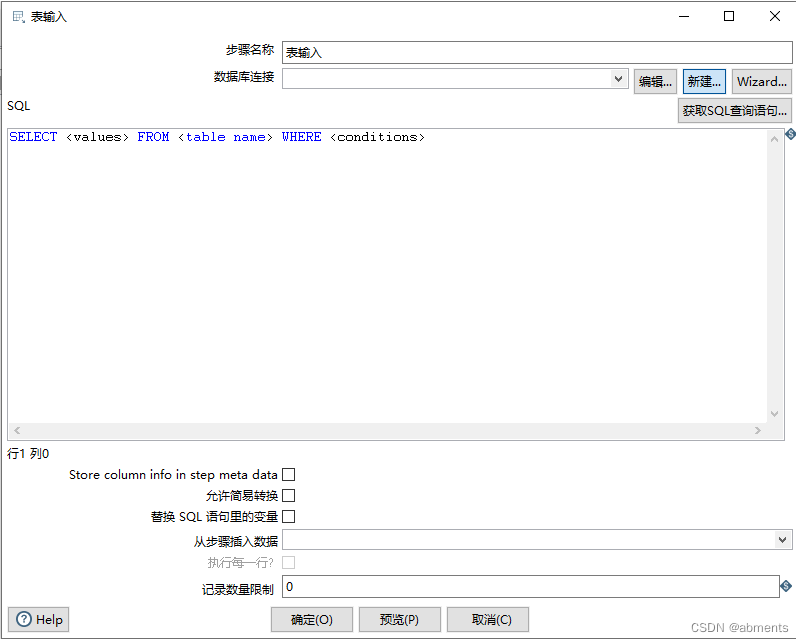
3.1.2 表输入
1.作用:
2.用法:
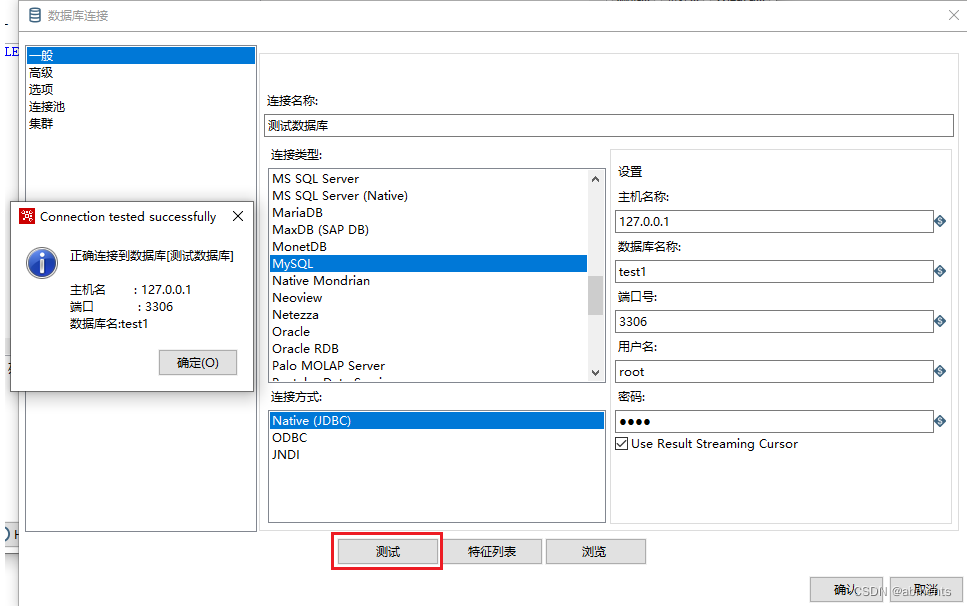
2.点击新建按钮,创建数据库连接(如果数据库链接已存在则可以直接使用),按照提示填写完成之后,点击测试按钮,弹出成功对话框表示数据库连接测试成功。
3.在SQL输入框中输入查询sql,点击预览按钮可以查看查询出来的数据 。
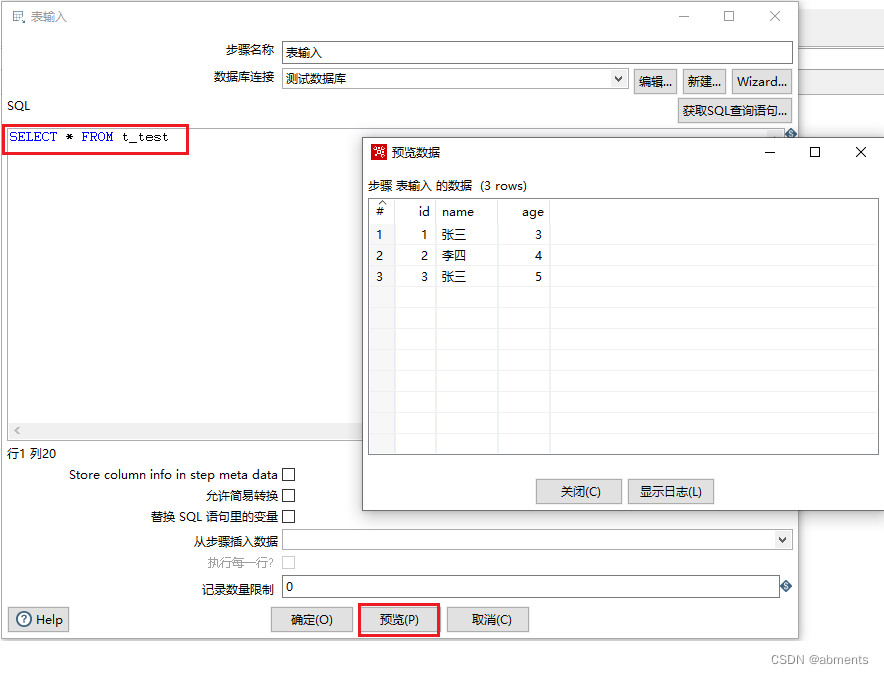
3.用途:
4.注意事项
在数据预览过程中,如果数据量过大或者查询时间过长,容易造成kettle卡死甚至崩溃,在预览过程中可以尝试在sql后加分页查询语句。
3.2 输出模块
3.2.1表输出
1.作用:
2.用法:
为了展示出数据插入的效果,我们结合表输入组件一起使用,把t_test表中的数据存入到t_test_1表中
5.点击获取字段按钮,检查左边表字段与流字段的对应关系是否正确,如果不正确可以直接修改
6.运行转换。
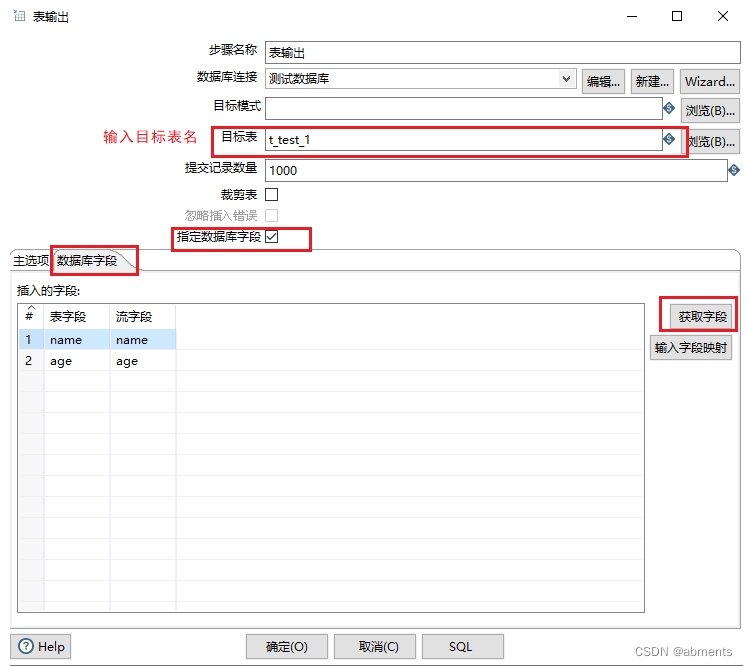
3.小技巧:
由于表t_test_1中的id字段是自增的,在插入数据库之前我们并不知道id的值是什么,幸运的是表输出组件提供了获取值的功能,但性能如何,我没有进行测试,大家用的时可以留意一下。使用方法如下:

预览数据:

3.3.2 插入/更新
1.作用:
2.用法:
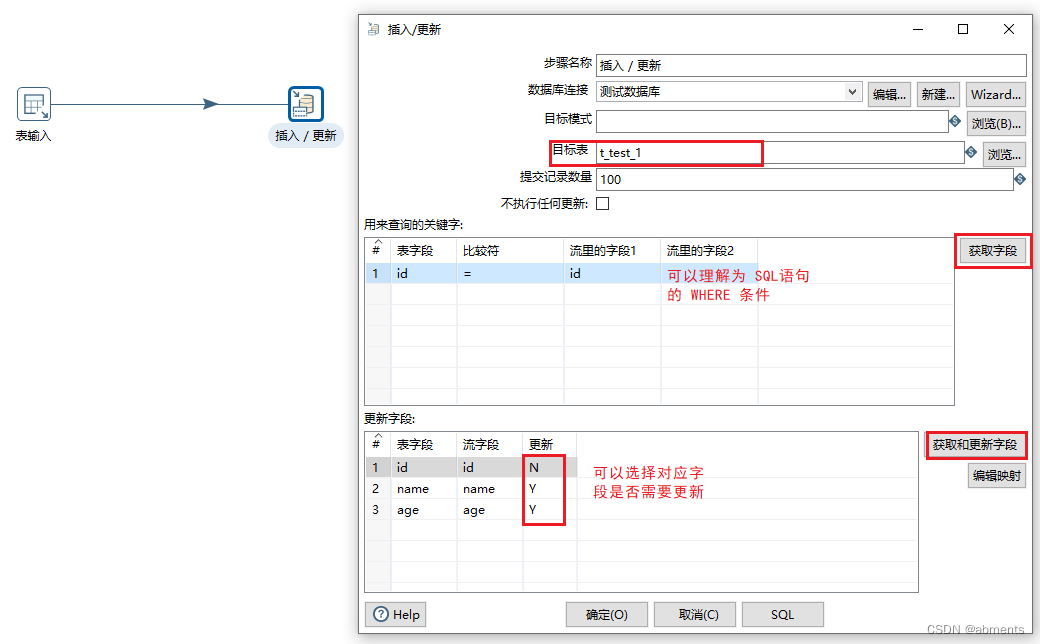
为了展示出组件的效果,我们结合表输入组件一起使用,把t_test表中的数据更新或插入到t_test_1表中
1.双击<插入/更新>组件
2.选择数库连接
4.点击<用来查询的关键字>右边的获取字段按钮,清除不需要的字段
5.点击<更新字段> 右边的 获取和更新字段按钮,清除不需要的字段
6.运行转换。
3.注意事项
3.3.3 更新
1.作用:
2.用法:
为了展示出组件的效果,我们结合表输入组件一起使用,把t_test表中的数据更新到t_test_1表中
1.双击<更新>组件
2.选择数库连接
4.点击<用来查询的关键字>右边的获取字段按钮,清除不需要的字段
5.点击<更新字段> 右边的 获取和更新字段按钮,清除不需要的字段
6.运行转换。

按照图中示例填写对应的选项即可完成设置。其中<批量更新><跳过查询><忽略查询失效>复选框在选择后,由于减少了查询的步骤,所以在性能上一定的提升,具体细节还请小伙伴们自行探索。
3.3 转换模块
3.3.1 字符串操作
1.作用:
2.用法:
为了展示出组件的效果,我们结合表输入组件一起使用,加工t_test表中的name字段
1.双击<字符串操作>组件
2.编辑数据对话框
3.运行转换。

3.注意事项
3.3.2 字符串替换
1.作用:
2.用法:
为了展示出组件的效果,我们结合表输入组件一起使用,加工t_test表中的name字段中包含 “张” 的字符串 替换 为 “小米”
2.编辑数据对话框
3.运行转换。

3.注意事项
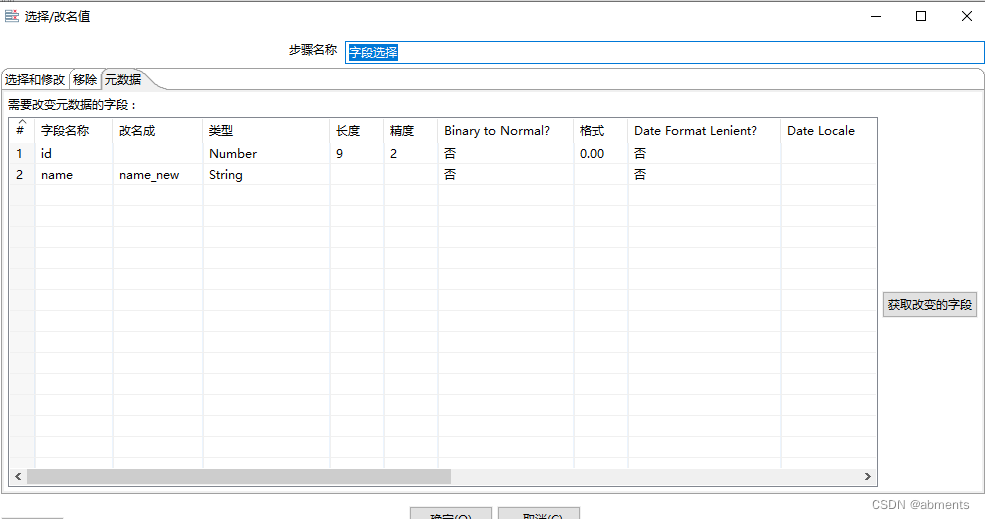
3.3.3 字段选择
1.作用:
2.用法:
为了展示出组件的效果,我们结合表输入组件一起使用,加工t_test表中的id字段类型修改为小数。同时移除sex字段,修改name字段名为name_new。
1.双击<字段选择>组件
2.编辑数据对话框
3.运行转换。
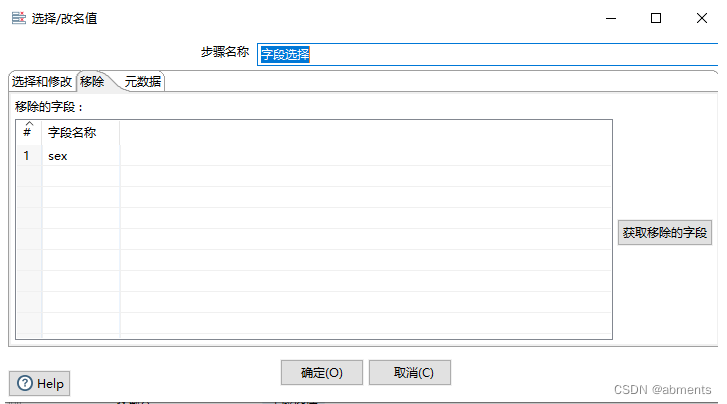
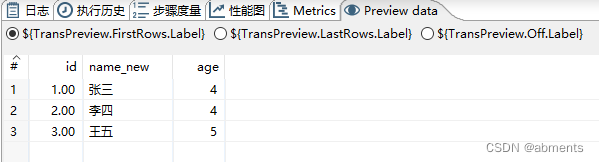
运行结果预览:
3.3.4 设置字段值
1.作用
2.用法:
为了展示出组件的效果,我们结合表输入组件一起使用,加工t_test表中的sex 字段替换为 name字段值
1.双击<设置字段值>组件
2.编辑数据对话框
3.运行转换。

3.3.5 计算器
1.作用:
2.用法:
为了展示出组件的效果,我们结合表输入组件一起使用,根据t_test表中的name、sex、age字段生成一个新的字段combine
1.双击<计算器>组件
2.编辑数据对话框
3.运行转换。

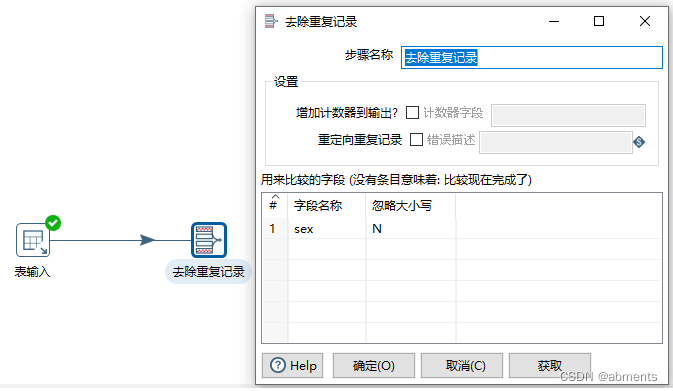
3.3.6 去除重复记录
1.作用:
2.用法:
为了展示出组件的效果,我们结合表输入组件一起使用,根据t_test表中的sex字段进行去除重复记录。
1.双击<去除重复记录>组件
2.编辑数据对话框
3.运行转换。
根据sex字段去重

3.注意事项
1.在使用去重组件时一定要先根据去重字段进行排序,组件不关心排序是否升序或降序。
3.3.7 值映射
1.作用:
2.用法:
为了展示出组件的效果,我们结合表输入组件一起使用,根据t_test表中的sex字段进行字典翻译。
1.双击<值映射>组件
2.编辑数据对话框
3.运行转换。

3.4 应用模块
3.4.1 替换NULL值
1.作用:
2.用法:
为了展示出组件的效果,我们结合表输入组件一起使用,根据t_test表中的sex字段进行设置默认值。
1.双击<替换NULL值>组件
2.编辑数据对话框
3.运行转换。
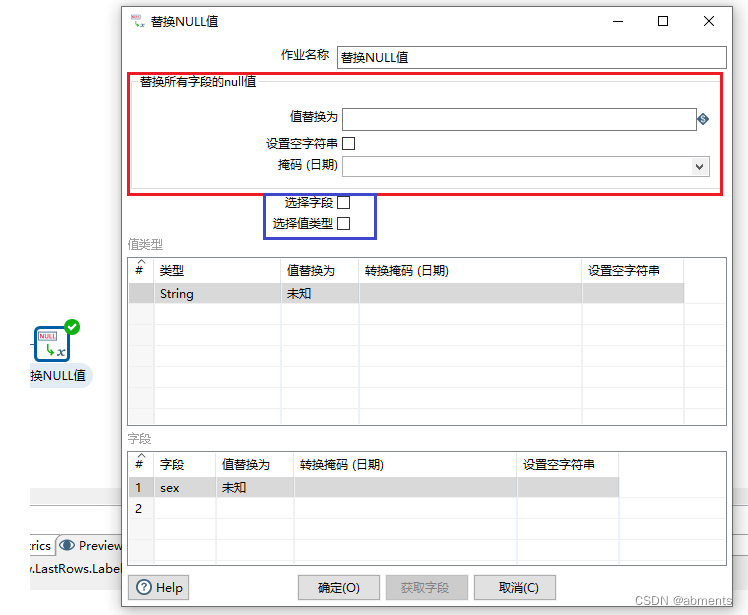
3.注意事项
<替换所有字段的null值>、<值类型>、<字段>三个输入框同时只能有一个生效。通过选择蓝色线框的复选框来确定哪个输入框生效。
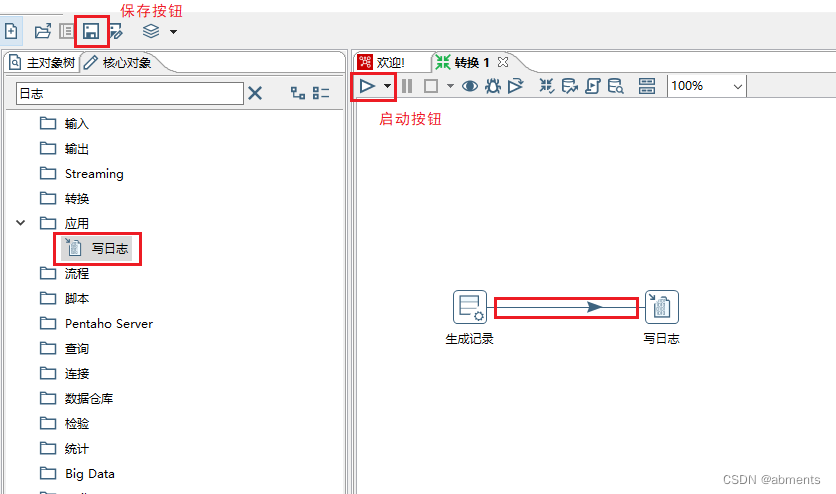
3.4.2 写日志
1.作用:
2.用法:
为了展示出组件的效果,我们结合表输入组件一起使用,把t_test表中的字段写入到日志中。
1.双击<写日志>组件
2.编辑数据对话框
3.运行转换。

3.5 流程模块
3.6 脚本模块
3.6.1 java 代码
1.作用:
2.用法:
为了展示出组件的效果,我们结合表输入组件一起使用。
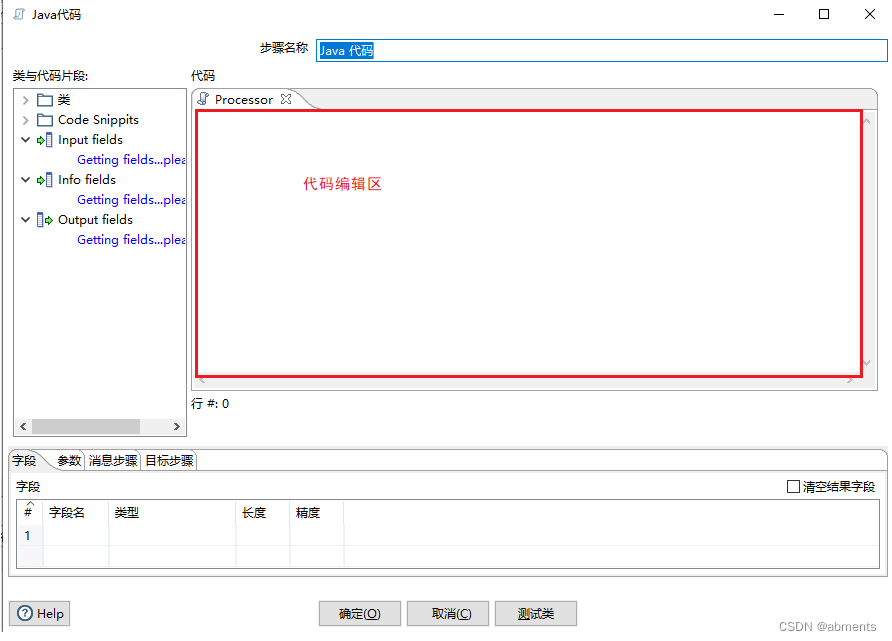
1.双击 <java 代码组件> 打开功能对话框。可以看到代码编辑区展示空白。
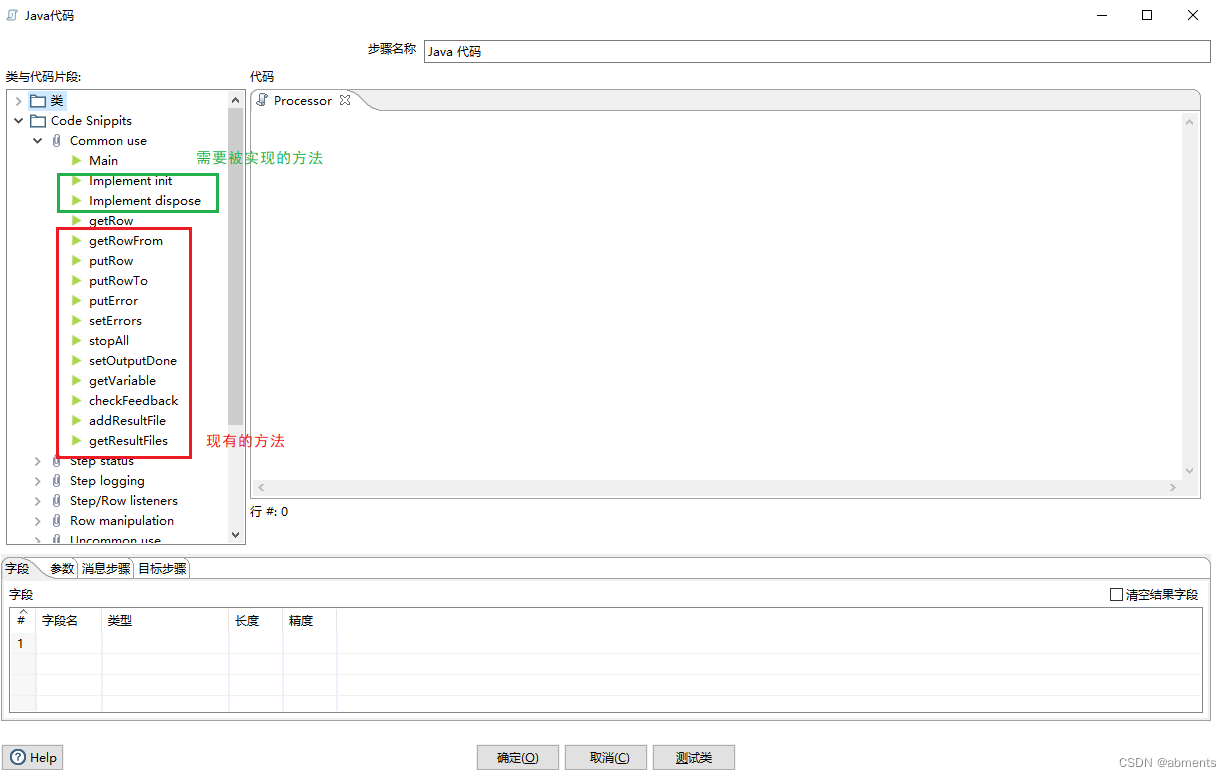
2.点击 Code Snippites 左边的箭头,展开下一级,看到二级分类菜单,打开Common use 如下:
3.双击Main 图标 将在右侧出现代码片段,我们主要在processRow(…)方法中编辑代码逻辑。
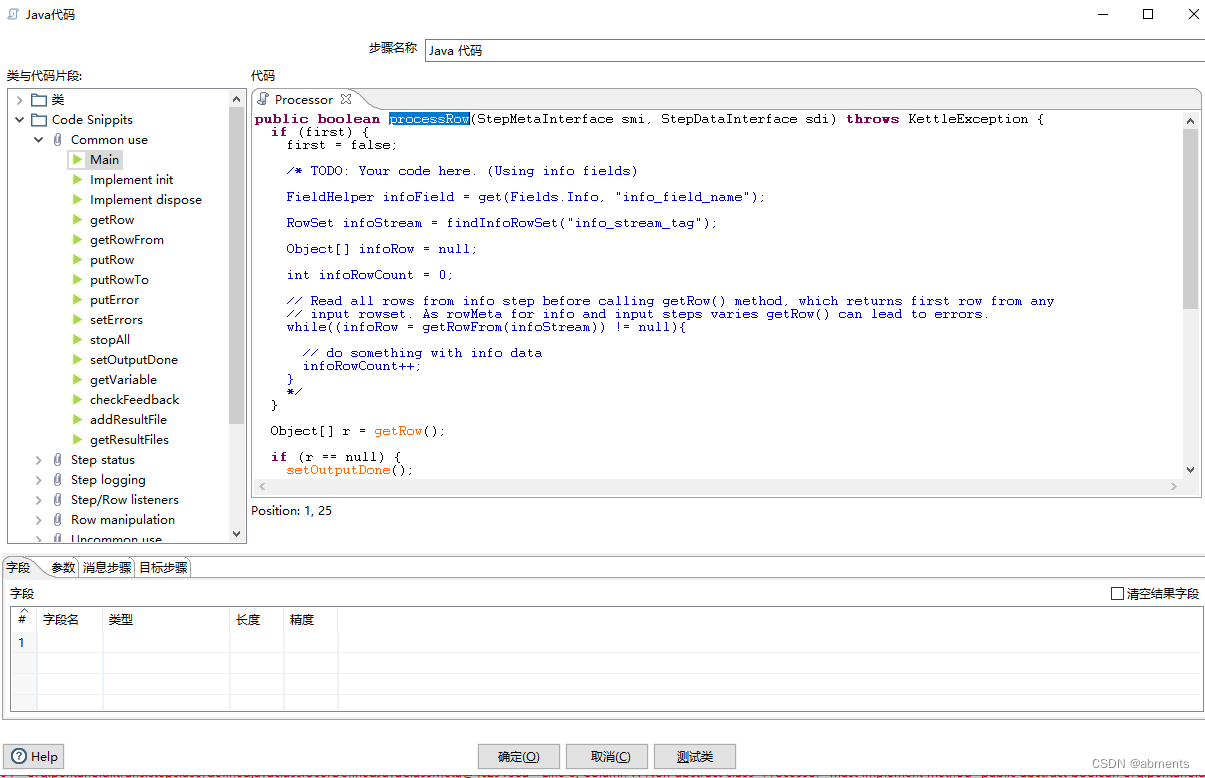
/*
main 方法对应于processRow(..)方法。
主要用来处理单行数据,如对数据进行加工或添加字段
另外,我们也可以在方法外部定义变量。
*/
public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws KettleException {
if (first) {
first = false;
/* TODO: Your code here. (Using info fields)
FieldHelper infoField = get(Fields.Info, "info_field_name");
RowSet infoStream = findInfoRowSet("info_stream_tag");
Object[] infoRow = null;
int infoRowCount = 0;
// Read all rows from info step before calling getRow() method, which returns first row from any
// input rowset. As rowMeta for info and input steps varies getRow() can lead to errors.
while((infoRow = getRowFrom(infoStream)) != null){
// do something with info data
infoRowCount++;
}
*/
}
Object[] r = getRow();
if (r == null) {
setOutputDone();
return false;
}
// It is always safest to call createOutputRow() to ensure that your output row's Object[] is large
// enough to handle any new fields you are creating in this step.
r = createOutputRow(r, data.outputRowMeta.size());
/* TODO: Your code here. (See Sample)
// 从流中获取字段对应的值,如果字段名不存在,会抛出异常
String foobar = get(Fields.In, "a_fieldname").getString(r);
foobar += "bar";
// 把数据设置到对应字段中,如果output_fieldname字段不存在,则可以在代码编辑区的下方字段设置框中设置字段信息。详情看下图:
get(Fields.Out, "output_fieldname").setValue(r, foobar);
*/
// Send the row on to the next step.
putRow(data.outputRowMeta, r);
return true;
}
/*
组件被启动时,执行一次,常用来初始化一些资源数据
*/
public boolean init(StepMetaInterface stepMetaInterface, StepDataInterface stepDataInterface) {
return parent.initImpl(stepMetaInterface, stepDataInterface);
}
/*
流结束时,被调用一次,常用来销毁资源,或做一些后置处理,通知消息等操作
*/
public void dispose(StepMetaInterface smi, StepDataInterface sdi) {
parent.disposeImpl(smi, sdi);
}4.4 getVariable
// 用来获取环境变量的值
String getVariable = getVariable(variableName, defaultValue);3.小技巧
1. 在脚本中还可以通过 Step logging 中的方法来设置日志,方便调试。
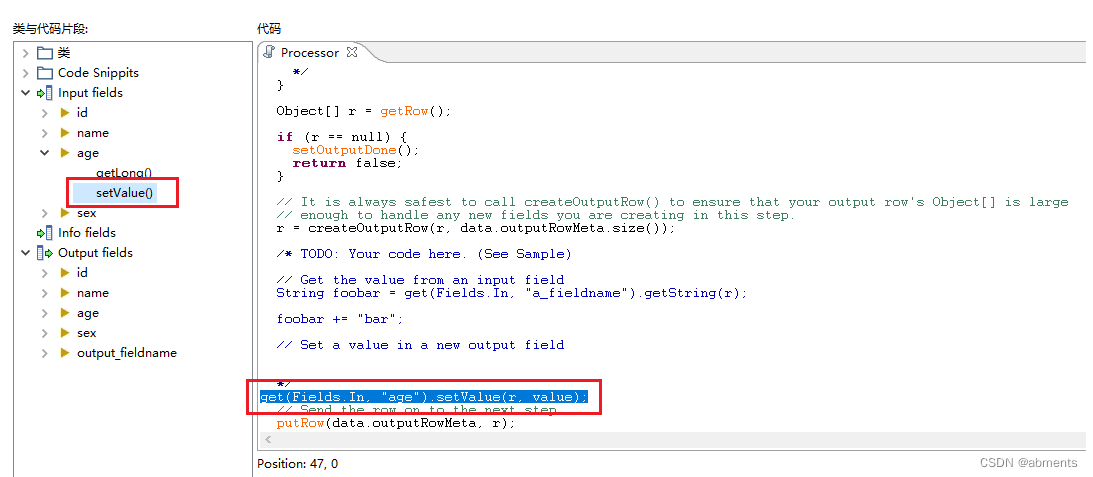
2.可以通过左边 Input files / Output files 快速生成 获取流中的字段值或设置流中的字段值 的相关代码,详情看下图。
设置字段值快捷方式:
3.7 连接模块
3.7.1 记录集连接
1.作用:
根据关键字段连接连个流数据。类似于数据库中的连接操作(INNER JOIN ,LEFT OUT JOIN ,RIGHT OUT JOIN ,FULL OUT JOIN )
2.用法:
为了展示出组件的效果,我们结合表输入组件一起使用,把t_test表中数据与t_test_2表中的数据进行关联。
1.双击<记录集连接>组件
2.编辑数据对话框
3.运行转换。
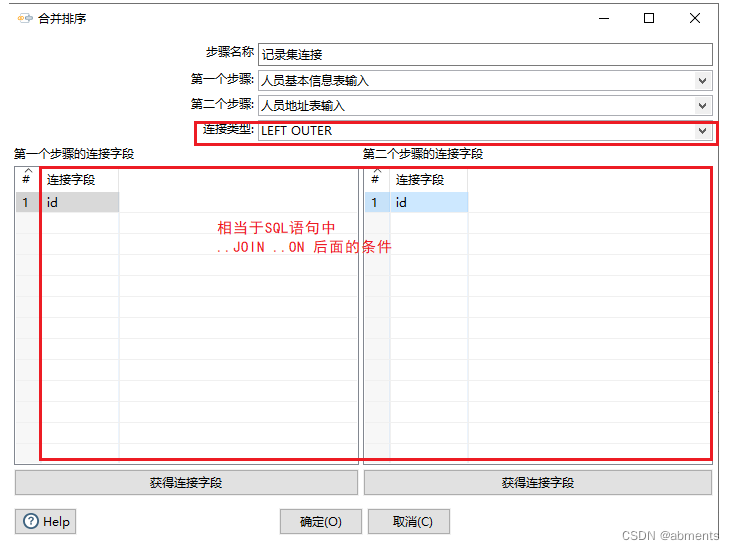

3.注意事项:
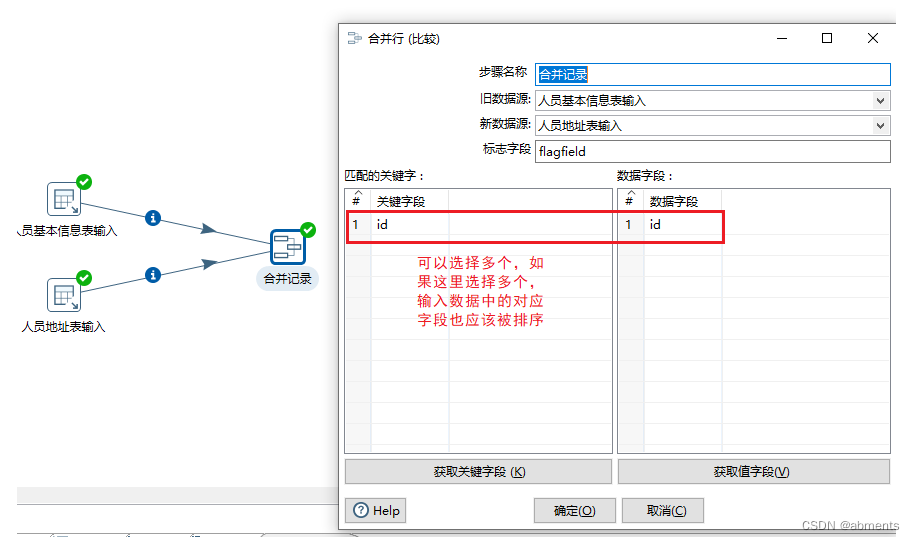
3.7.2 合并记录
1. 作用:
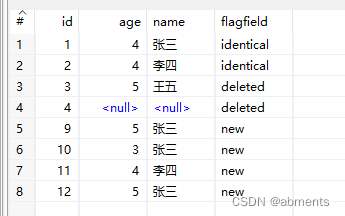
根据已经排序的字段合并两个数据流,并标识出结果集中的数据的状态: new(新建) deleted(删除) changed(改变) identical(相等)。
2.用法:
为了展示出组件的效果,我们结合表输入组件一起使用,把t_test表中数据与t_test_1表中的数据(id,name,age)进行合并。
1.双击<合并记录>组件
2.编辑数据对话框
3.运行转换。
输入数据:

输出结果:
3.8 统计模块
3.8.1 聚合
1.作用:
根据已经排序的分组字段,对结果进行聚合。相当于SQL 语句中的 SELECT 聚合函数() FORM TABLE GROUP BY FIELD ;
2.用法:
为了展示出组件的效果,我们结合表输入组件一起使用,把t_test表中的数据根据sex字段进行分组,并对组内数据中的age字段进行求和,对组内数据中的name字段进行逗号拼接。
1.双击<聚合>组件
2.编辑数据对话框
3.运行转换。

分组前需要先根据分组字段排序
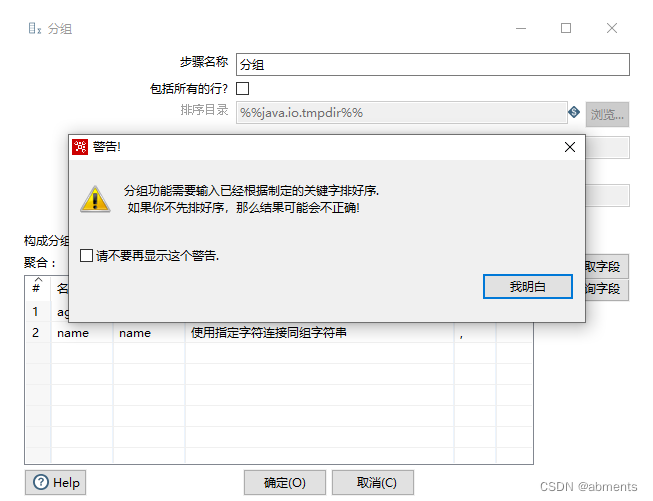
3.注意事项
3.9 作业模块
3.9.1 设置变量
1.作用:
2.用法:
为了展示出组件的效果,我们结合生成记录组件,java代码组件一起使用。我们打算把字段:test_variable 值:test_value 设置为变量。
2.1 设置生成记录组件。只有当有数据流入组件时,组件才会工作。所以我们需要创建一条记录来启动java代码组件。

2. 2 设置java代码组件。
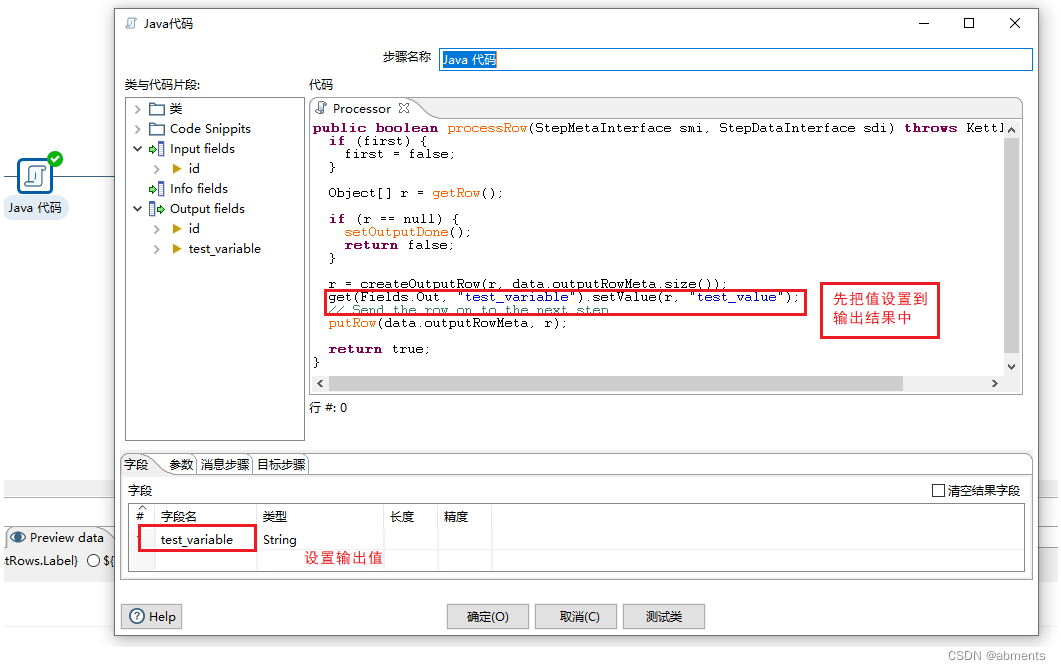
2.3 设置变量
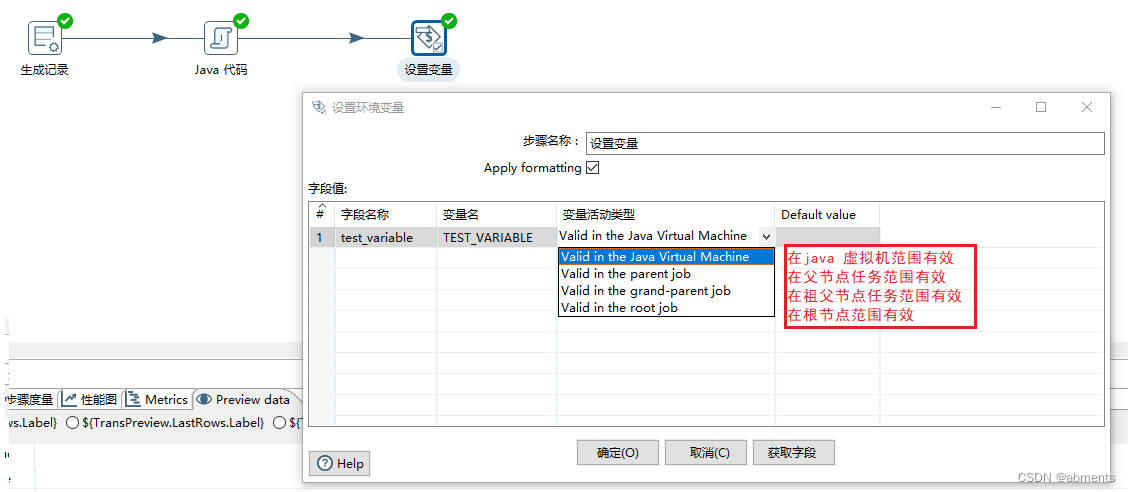
弹出框出现提示语:

3.注意事项
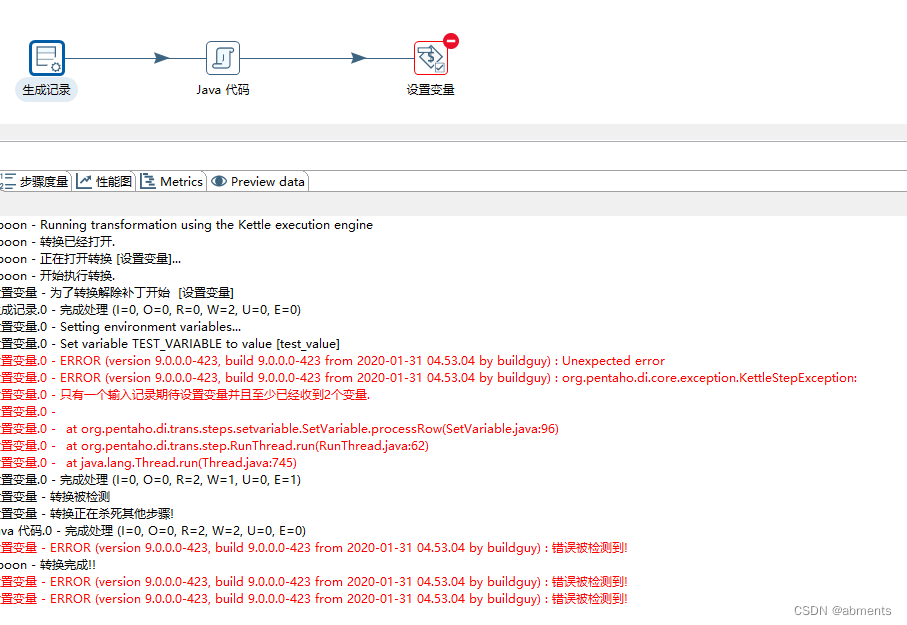
3.10 转换中的通用技巧
3.10.1占位符
1.作用:
2.用法:
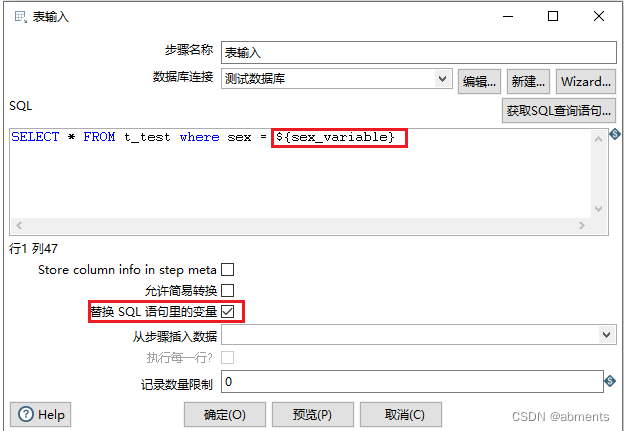
在转换调试过程中可以先设置sex_variable的默认值。双击空白处,弹出如下编辑框,在命名参数tab页可以设置命名参数默认值。

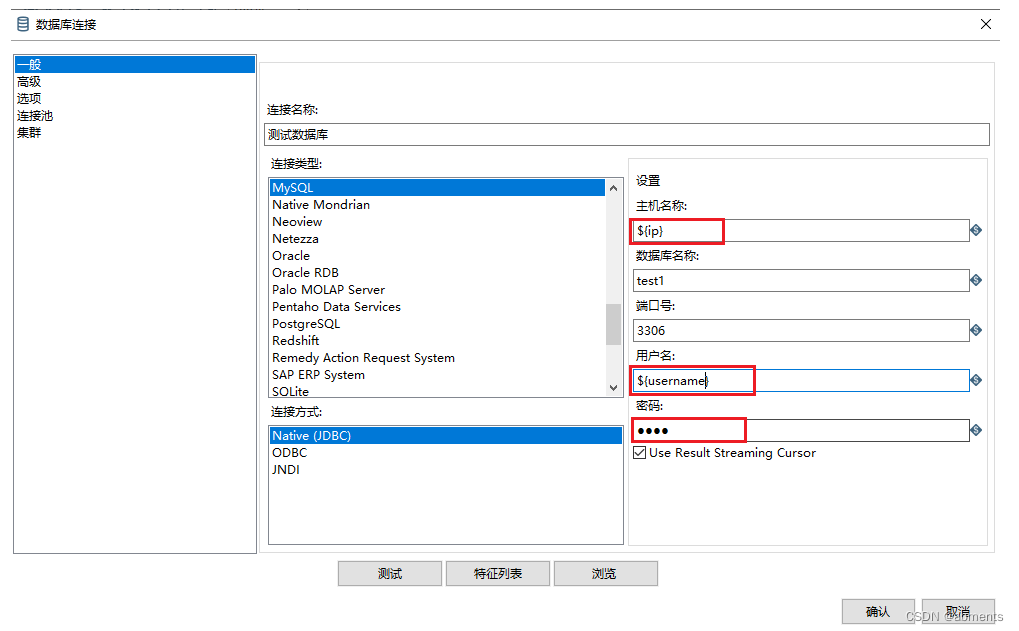
3.10.2 查看显示输入字段,显示输出字段
1.作用:
2.用法:
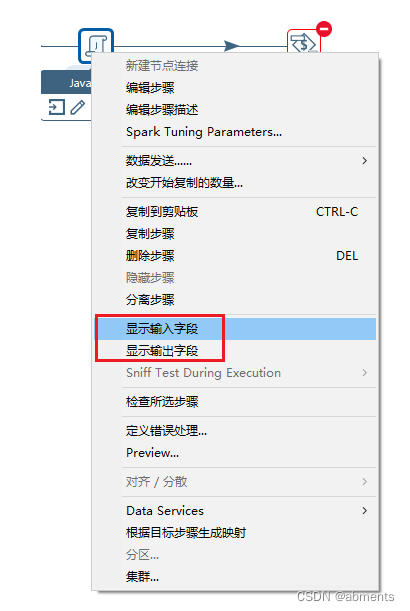
输入字段详细信息:
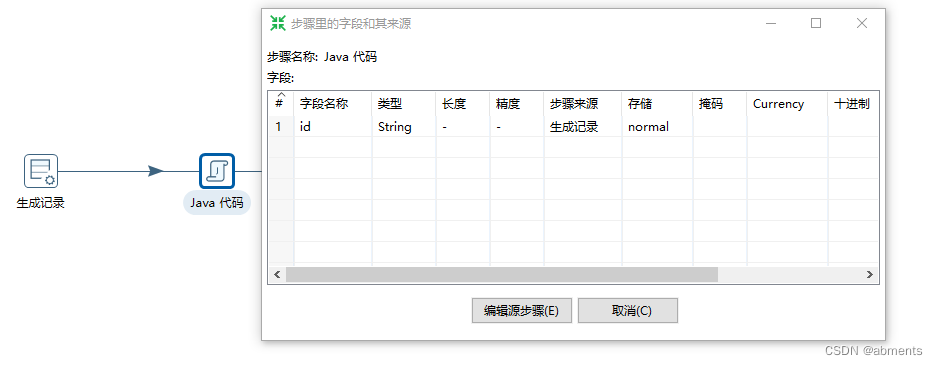
输出字段详细信息:
3.10.3 数据发送
1.作用:
2.用法:
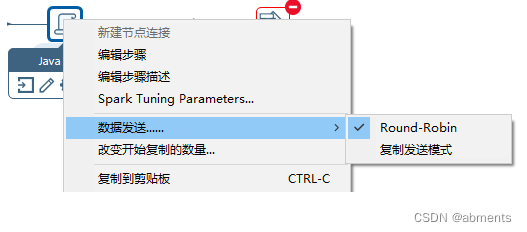
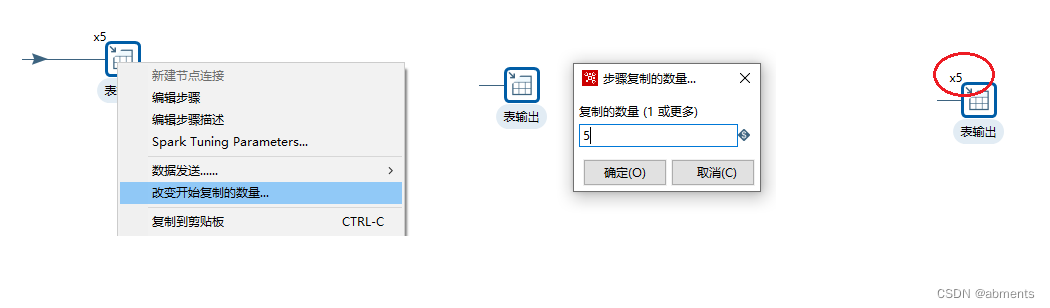
3.10.4 改变开始复制的数量
1.作用:
2.用法:
3.10.5 hop/连接线/跳
1.作用:
控制数据的流向。
2.用法:
鼠标放置到连线上,右键弹出选项框。选项框提供了连接线的常用功能。如果选择<使节点连接失效>则连接线会变灰,同时数据不会流向下一个组件。需要注意的是单击连接线也会使结点在失效和生效之间转换,在使用时需要注意误操作。

四、任务中的常用组件
任务(作业)侧重于对步骤的编排。作业按照一定的顺序完成,因为转换以并行方式执行的,就需要一个可以串行执行的作业来处理一系列按照顺序完成的操作。一个作业包括一个或者多个作业项,这些作业项以某种顺序来执行。作业执行顺序由作业项之间的跳(job hop)和每个作业项的执行结构来决定。
4.1 通用模块
4.1.1 start
1.作用:
2.用法:
2.双击Start图标,设置开始组件。

3.注意点:
虽然kettle的start组件提供了定时调度功能,但是功能比较弱,kettle官方也不推荐使用自带的调度功能,反而建议使用操作系统自带的定时任务。
4.1.2 转换
1.作用:
调用一个已经存在的转换。
2.用法:
1.拖动 转换 图标到编辑区。
2.双击 转换 图标。
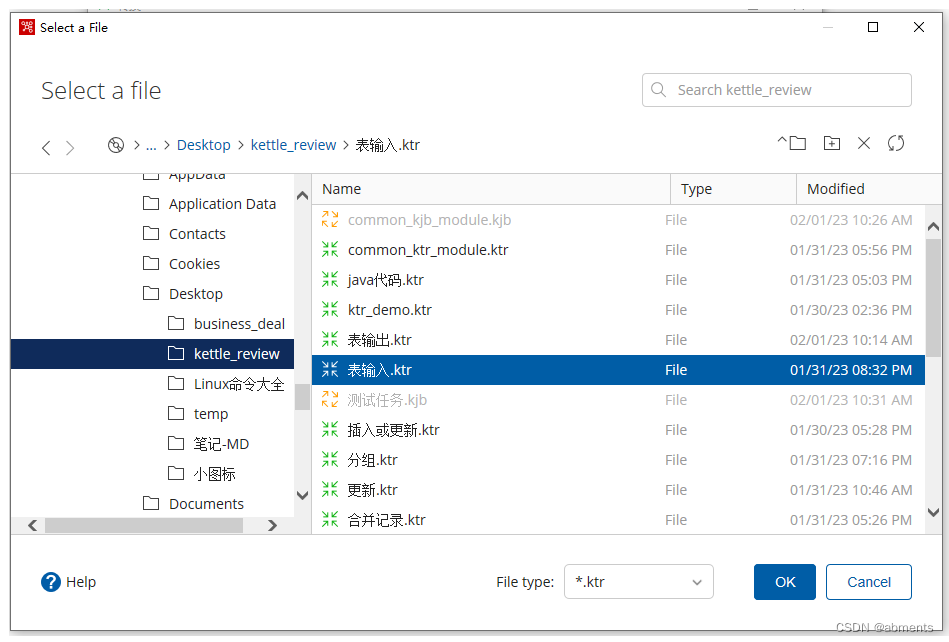
选择转换文件:

选择转换文件:
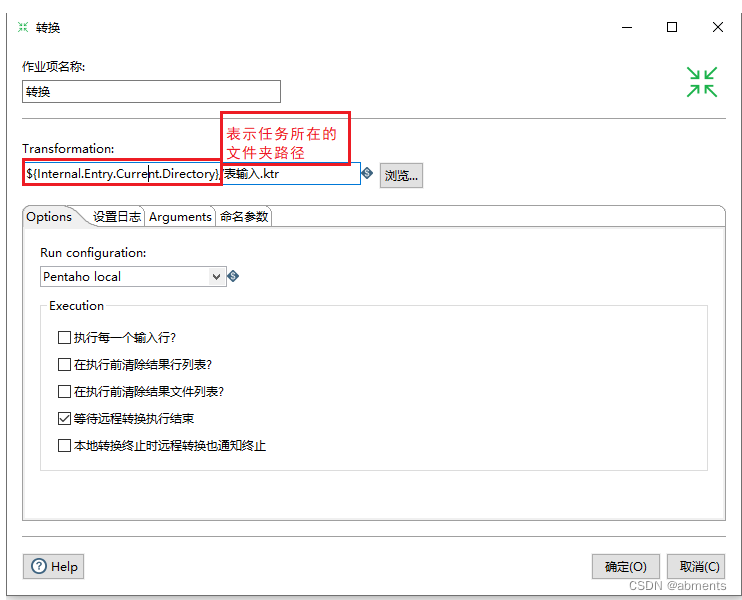
3.需要注意的是,现在的任务还不能直接看到效果。如果需要使组件运行,需要通过连接线进行连接。运行后,组件右上角展示的绿色对号表示正确运行结束。
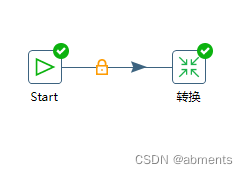
4.1.2 作业
1.作用:
调用一个已经存在的任务。
2.用法:
4.1.3 设置变量
1.作用:
2.用法:
1.拖动 设置变量 图标到编辑区。
2.双击 设置变量 图标。
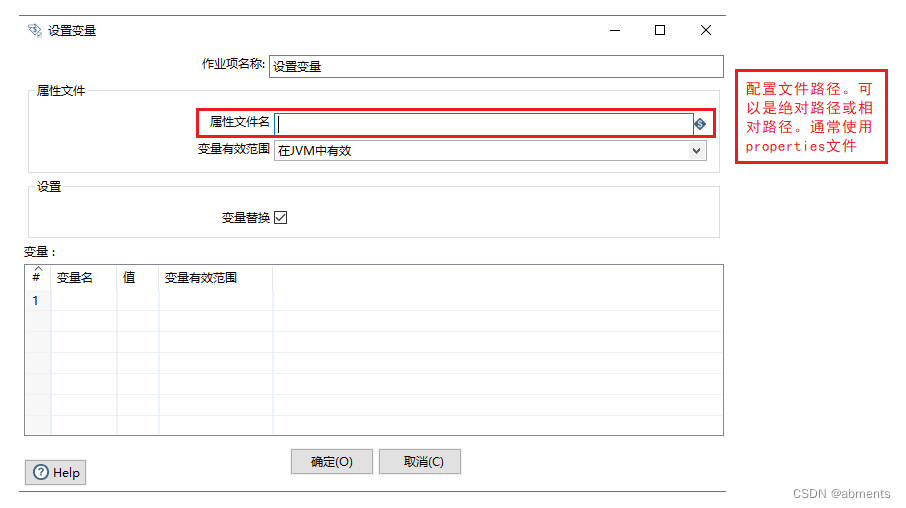
3.注意事项:
1.在这里设置的变量,可以通过组件中的占位符(${})获取,也可以在java代码中通过String getVariable = getVariable(variableName, defaultValue)方法获取。
2.设置时注意变量的有效范围。
4.小技巧:


4.1.4 成功
1.作用:
4.2 脚本模块
4.2.1 SQL
1.作用:
2.用法:
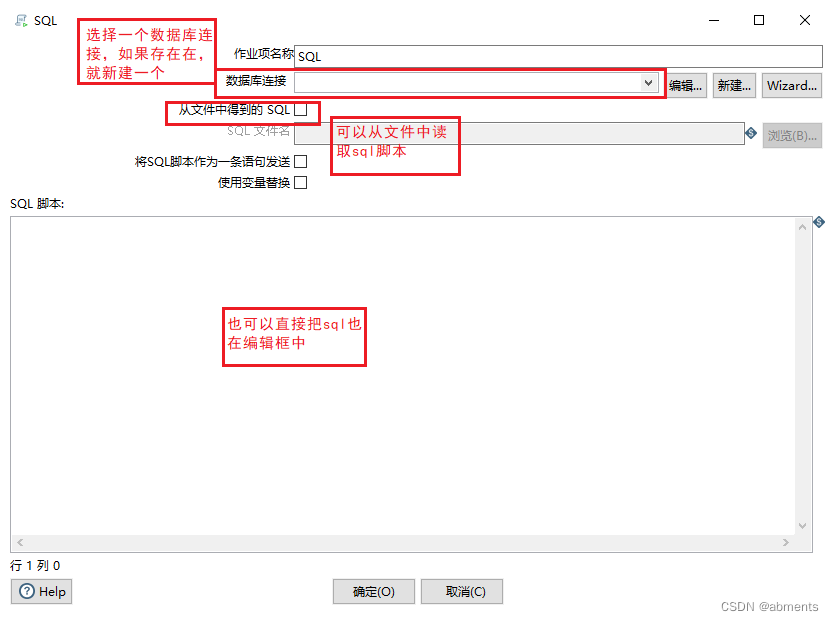
1.拖动 SQL 图标到编辑区。
2.双击 SQL 图标。
4.3 文件管理模块
4.3.1 等待文件
1.作用:
1.等待一个文件,常用来做任务是否完成的标志。当某一个任务完成后,可以创建一个标志文件,当其他任务检测到该文件时,就会知道某一个任务已经完成。
2.用法:
1.拖动 等待文件 图标到编辑区。
2.双击 等待文件 图标。

4.4 任务中的通用技巧
4.4.1 hop/连接线/跳
1.作用:
2.用法:
任务中的连接线与转换中的连接线类似。但多了<评价>选项。评价功能用来决定当上一个组件执行完后是否执行下一个组件(每一个组件执行完后都有一个是否执行成功的标识true/false)。

4.4.2 并行
1.作用:
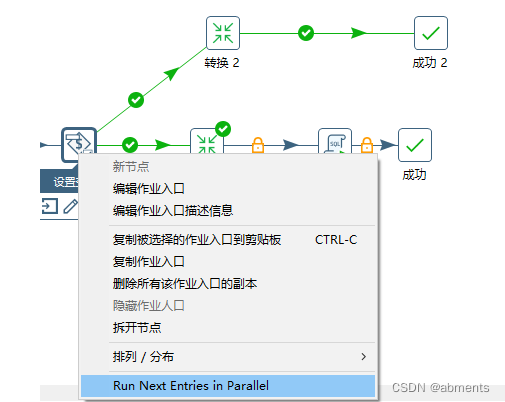
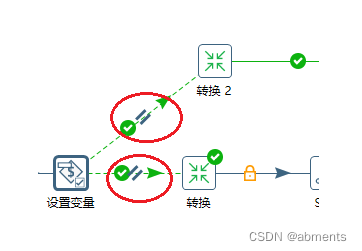
3.注意事项:
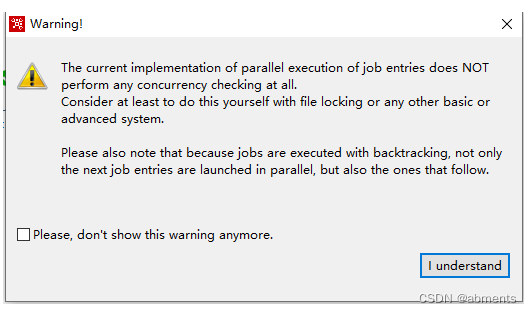
当前并行执行作业项的实现根本不执行任何并发检查。至少可以考虑使用文件锁定或任何其他基本或高级系统自己执行。
还请注意,因为作业是通过回溯执行的,所以不仅下一个作业条目是并行启动的,而且后续的作业条目也是并行启动的。
请不要再显示此警告。
总结
原文地址:https://blog.csdn.net/abments/article/details/128800994
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_31176.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!