Spark经典案例
链接操作案例
案例需求


package base.charpter7
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
/**
* @projectName sparkGNU2023
* @package base.charpter7
* @className base.charpter7.Join
* @description ${description}
* @author pblh123
* @date 2023/11/28 17:25
* @version 1.0
*
*/
object Join {
def main(args: Array[String]): Unit = {
// 1. 创建一个sc对象
if (args.length != 4) {
println("usage is WordCount <rating> <movie> <output>")
System.exit(5)
}
val murl = args(0)
val ratingfile = args(1)
val movingfile = args(2)
val outputfile = args(3)
val spark: SparkSession = new SparkSession.Builder()
.appName(s"${this.getClass.getSimpleName}").master(murl).getOrCreate()
val sc: SparkContext = spark.sparkContext
// 2. 代码主体
// 判断输出路径是否存在,存在则删除
val conf: Configuration = new Configuration()
val fs: FileSystem = FileSystem.get(conf)
if (fs.exists(new Path(outputfile))) {
println(s"存在目标文件夹$outputfile")
fs.delete(new Path(outputfile))
println(s"目标文件夹$outputfile 已删除")
}
else println(s"目标文件夹$outputfile 不存在")
//rating etl
val ratingrdd: RDD[String] = sc.textFile(ratingfile, 1)
val rating: RDD[(Int, Double)] = ratingrdd.map(line => {
val fileds: Array[String] = line.split("::")
(fileds(1).toInt, fileds(2).toDouble)
})
val movieScores: RDD[(Int, Double)] = rating.groupByKey().map(x => {
val avg = x._2.sum / x._2.size
(x._1, avg)
})
// move etl
val movierdd: RDD[String] = sc.textFile(movingfile)
// movieid,(movieid,title)
val movieskey: RDD[(Int, (Int, String))] = movierdd.map(line => {
val fileds: Array[String] = line.split("::")
(fileds(0).toInt, fileds(1))
}).keyBy(tup => tup._1)
// movieid,(movieid,avg_rating)
val sskey: RDD[(Int, (Int, Double))] = movieScores.keyBy(tup => tup._1)
// movieid, (movieid,avg_rating),(movieid,title)
val joinres: RDD[(Int, ((Int, Double), (Int, String)))] = sskey.join(movieskey)
// movieid,avg_rating,title
val res: RDD[(Int, Double, String)] = joinres.filter(f => f._2._1._2 > 4.0)
.map(f => (f._1, f._2._1._2, f._2._2._2))
// val res: RDD[(Int, Double, String)] = sskey.join(movieskey)
// .filter(f => f._2._1._2 > 4.0)
// .map(f => (f._1, f._2._1._2, f._2._2._2))
res.take(5).foreach(println)
res.saveAsTextFile(outputfile)
// 3. 关闭sc,spark对象
sc.stop()
spark.stop()
}
}

二次排序案例

package base.charpter7
/**
* @projectName sparkGNU2023
* @package base.charpter7
* @className base.charpter7.SecondarySortKey
* @description ${description}
* @author pblh123
* @date 2023/11/29 17:01
* @version 1.0
*/
class SecondarySortKey(val first:Int, val second:Int) extends Ordered[SecondarySortKey] with Serializable{
override def compare(that: SecondarySortKey): Int = {
if (this.first - that.first != 0){
this.first - that.first
} else {
this.second - that.second
}
}
}
SecondarySortApp.scala方法
package base.charpter7
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
/**
* @projectName sparkGNU2023
* @package base.charpter7
* @className base.charpter7.SecondarySortApp
* @description ${description}
* @author pblh123
* @date 2023/11/29 17:04
* @version 1.0
*
*/
object SecondarySortApp {
def main(args: Array[String]): Unit = {
// 1. 创建spark,sc对象
if (args.length != 2) {
println("您需要输入二个参数")
System.exit(5)
}
val musrl: String = args(0)
val spark: SparkSession = new SparkSession.Builder()
.appName(s"${this.getClass.getSimpleName}")
.master(musrl)
.getOrCreate()
val sc: SparkContext = spark.sparkContext
// 2. 代码主体
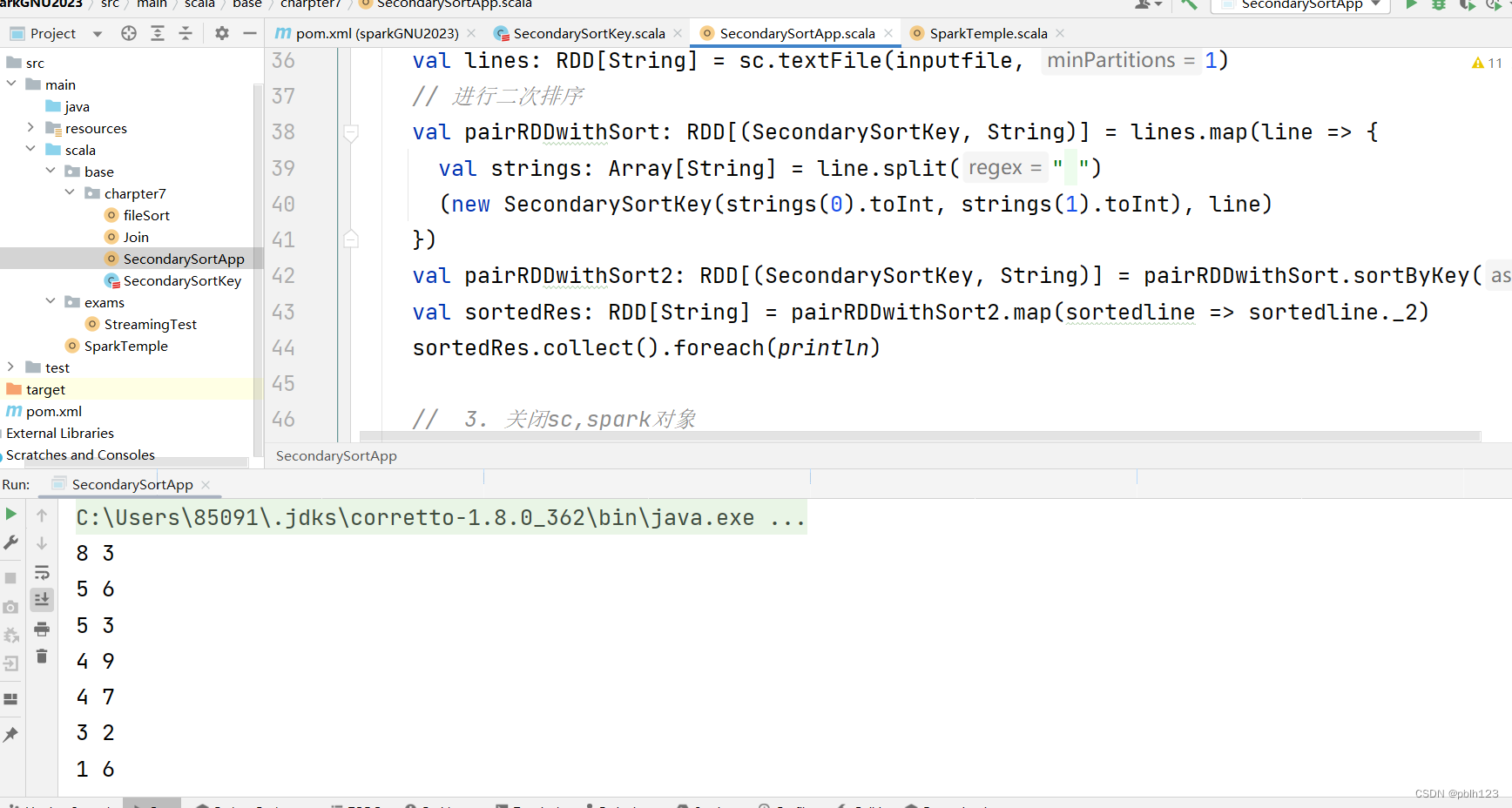
// 读取一个txt文件
val inputfile: String = args(1)
val lines: RDD[String] = sc.textFile(inputfile, 1)
// 进行二次排序
val pairRDDwithSort: RDD[(SecondarySortKey, String)] = lines.map(line => {
val strings: Array[String] = line.split(" ")
(new SecondarySortKey(strings(0).toInt, strings(1).toInt), line)
})
val pairRDDwithSort2: RDD[(SecondarySortKey, String)] = pairRDDwithSort.sortByKey(false)
val sortedRes: RDD[String] = pairRDDwithSort2.map(sortedline => sortedline._2)
sortedRes.collect().foreach(println)
// 3. 关闭sc,spark对象
sc.stop()
spark.stop()
}
}
原文地址:https://blog.csdn.net/pblh123/article/details/134694271
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_31332.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。

![[Lucene]核心类和概念介绍](http://www.7code.cn/wp-content/uploads/2023/11/ee6748cbc735e6105405f8a984d954c804b93f34bc916-Z0IqTf_fw1200.png)