本文介绍: 目前,Lucene 限制 dot_product (点积) 只能在标准化向量上使用。归一化迫使所有等于一。虽然在许多情况下这是可以接受的,但它可能会导致某些数据集的相关性问题。一个典型的例子是构建的嵌入(embeddings)。它们的向量使用幅度来提供更多相关信息。那么,为什么不允许点积中存在非归一化向量,从而实现最大内积呢?有什么大不了的?

目前,Lucene 限制 dot_product (点积) 只能在标准化向量上使用。 归一化迫使所有向量幅度等于一。 虽然在许多情况下这是可以接受的,但它可能会导致某些数据集的相关性问题。 一个典型的例子是 Cohere 构建的嵌入(embeddings)。 它们的向量使用幅度来提供更多相关信息。
那么,为什么不允许点积中存在非归一化向量,从而实现最大内积呢? 有什么大不了的?
负值和 Lucene 优化
Lucene要求分数非负,因此在析取 (disjunctive query) 查询中多匹配一个子句只能使分数更高,而不是更低。 这实际上对于动态修剪优化(例如 block-max WAND)非常重要,如果某些子句可能产生负分数,则其效率会大大降低。 此要求如何影响非标准化向量?
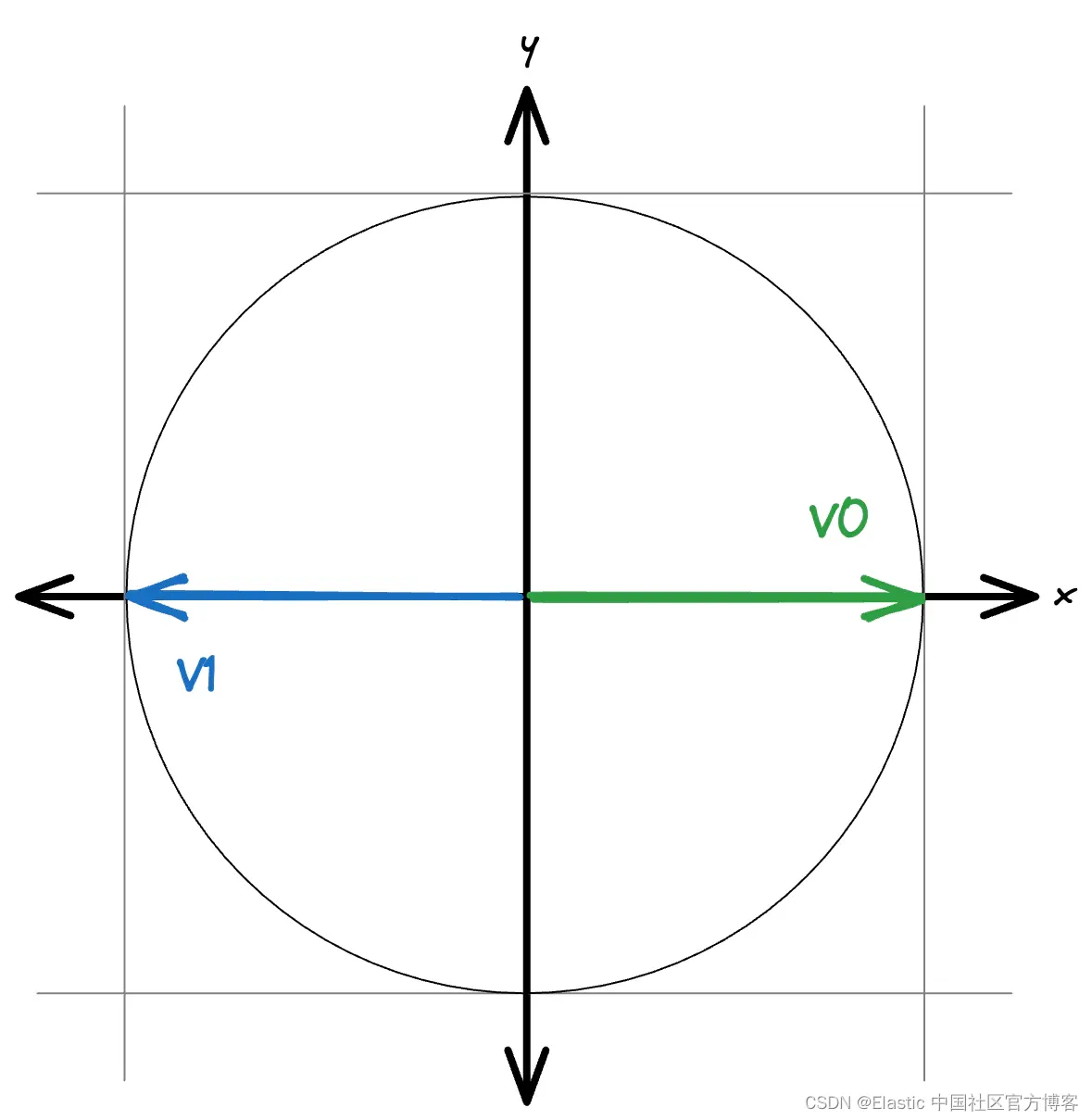
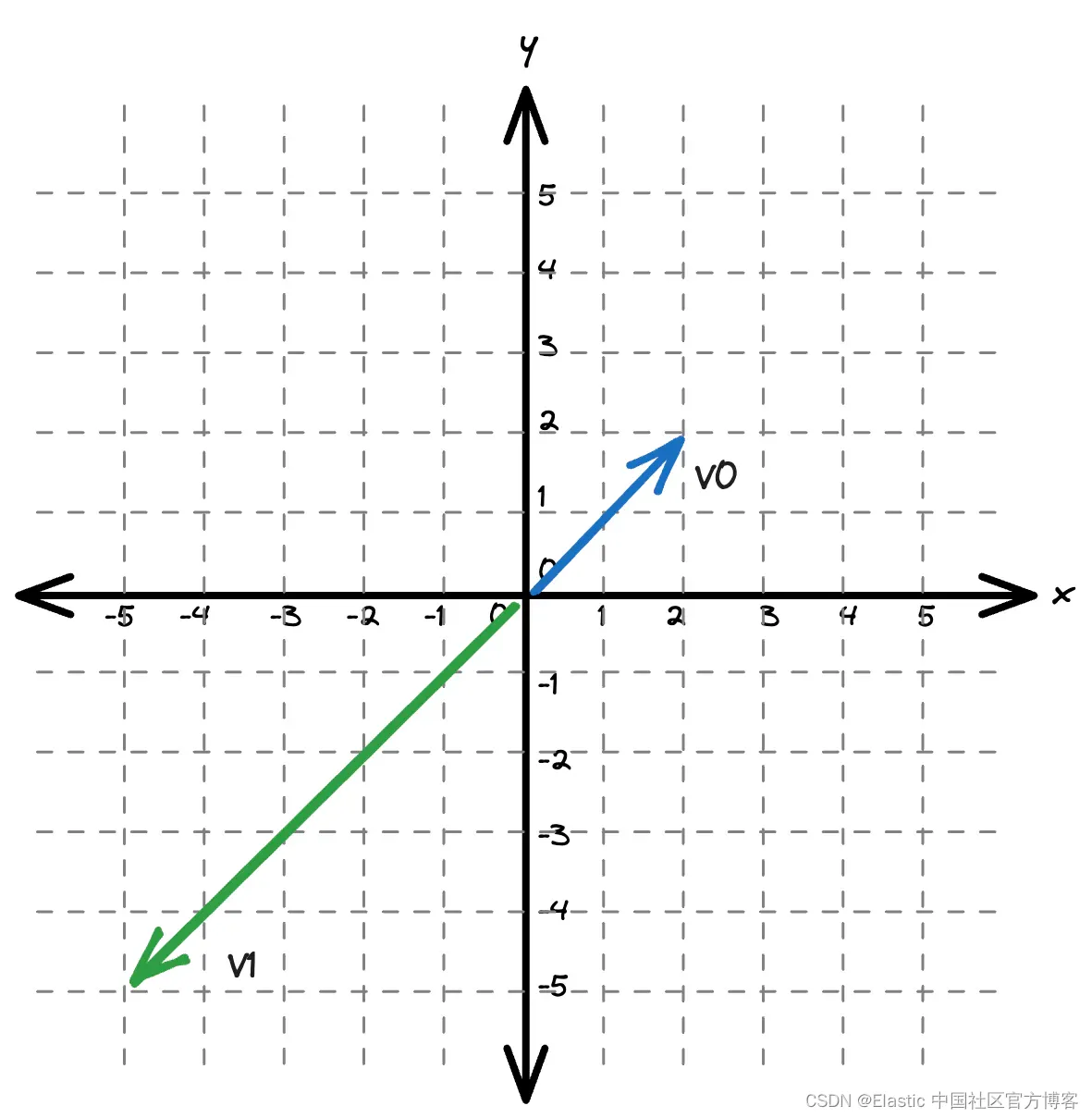
三角形问题



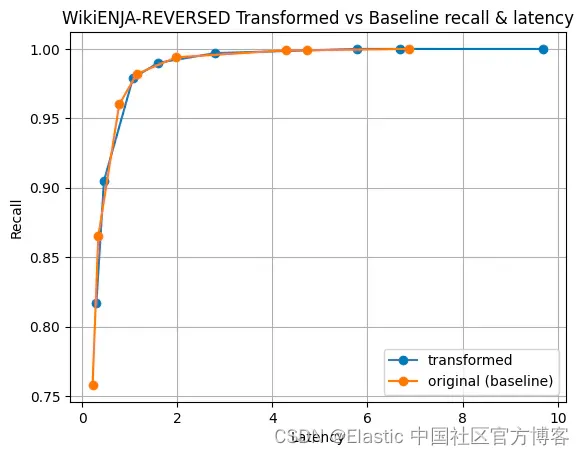



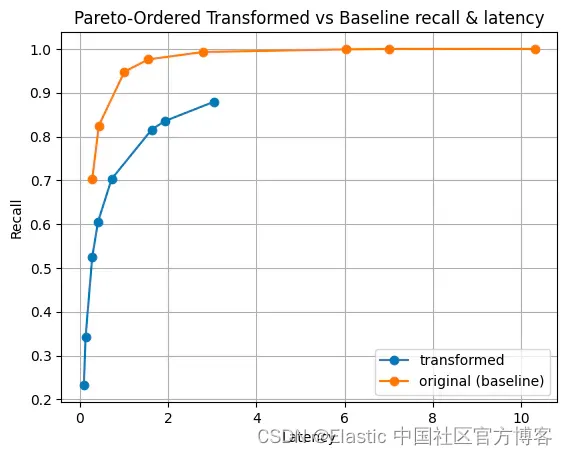
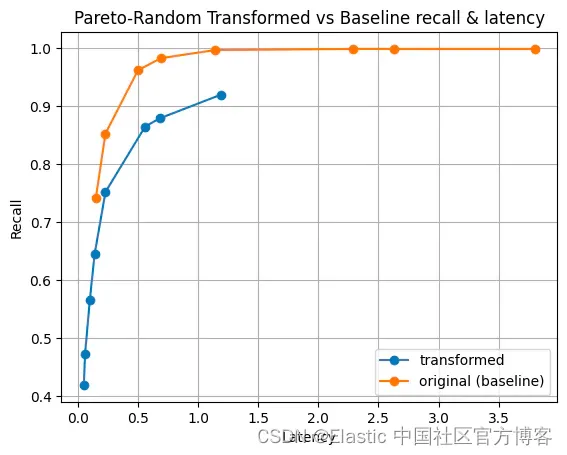
结论
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。

![[Lucene]核心类和概念介绍](http://www.7code.cn/wp-content/uploads/2023/11/ee6748cbc735e6105405f8a984d954c804b93f34bc916-Z0IqTf_fw1200.png)